本文章主要涉及group by报错注入的原理讲解,如有错误,望指出。(附有目录,如需查看请点右下角)
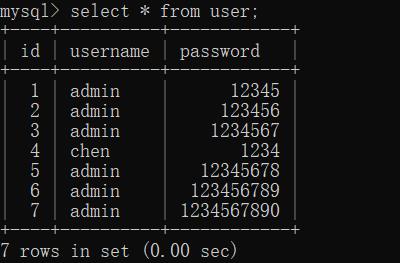
一、下图为本次文章所使用到 user表,该表所在的数据库为 test
二、首先介绍一下本文章所使用的到的语法:(第5、6条必须看,这涉及到之后的原理讲解)
1、group by语句:用于结合合计函数,根据一个或多个列对结果集进行分组。
如下图:
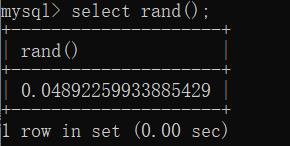
2、rand()函数:用于产生一个0-1之间的随机数:
如下图:
注意:
当以某个整数值作为参数来调用的时候,rand() 会将该值作为随机数发生器的种子。对于每一个给定的种子,rand() 函数都会产生一列【可以复现】的数字
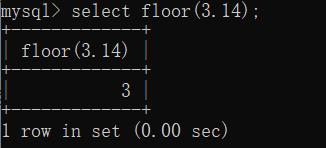
3、floor()函数:向下取整:
如下图:
4、count()函数:返回指定列的值的数目(NULL 不计入),count(*):返回表中的记录数
如下图
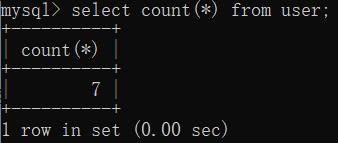
5、floor(rand()*2):rand()*2 函数生成 0-2之间的数,使用floor()函数向下取整,得到的值就是【不固定】的 “0” 或 “1”
如下图:
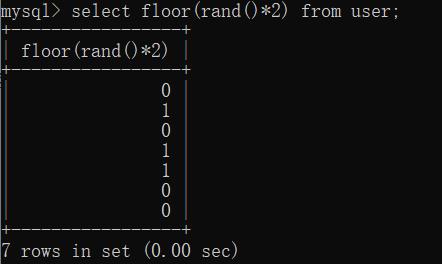
6、floor(rand(0)*2):rand(0)*2 函数生成 0-2之间的数,使用floor()函数向下取整,但是得到的值【前6位(包括第六位)是固定的】。(为:011011)
如下图:
三、接下来我们开始讲解group by进行分组的原理:(如果你觉得已经理解了该原理请直接转:四)
首先让我们思考一下下面三个sql语句,从中我们可以得知什么:
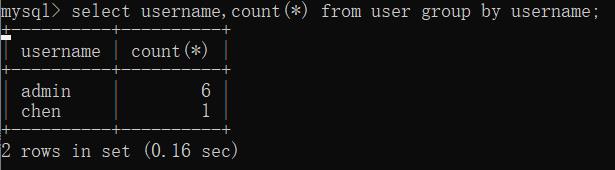
1、select username,count(*) from user group by username;
2、select username,count(*) from user group by "username";
3、select username,count(*) from user group by userna;
运行结果如下:
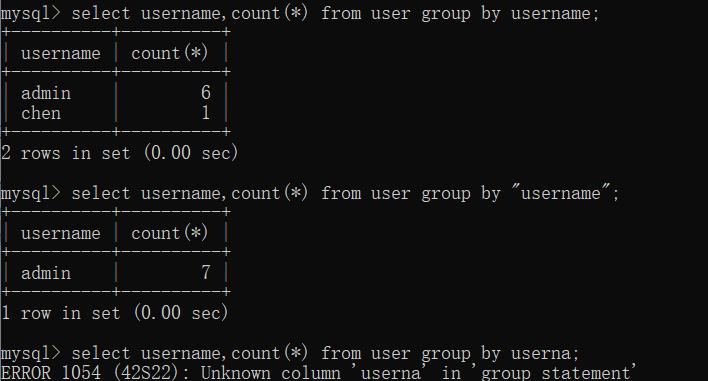
结论:
我们发现group by后面的参数可以是一个column_name(字段名),可以是一个字符串(或返回值为字符串的函数),不可以是不完整的column_name。这时你们可能会想,参数是column_name我倒是可以理解是怎么分组的,但是参数是 字符串 是怎么回事?username字段的值中没有"username"啊?只有"admin","chen"两个,结果怎么会是 7 呢?让我们接着往下看。
原因:上面sql语句的分组原理(虽然是我的推测,但是这样说明的确可以解释的通):
1、如果参数是 column_name,即 username,不是字符串("username")。
语句执行的时候会建立一个虚拟表(里面有两个字段,分别是 key 主键,count(*)),如果参数是 column_name,系统便会在 user 表中【 依次查询 [相应的] 字段的值(即:参数指明的字段中的值) 】,取username字段第一个值为 admin,这时会在虚拟表的 主键key 中查找 admin 这个字符串,如果存在,就使 count(*) 的值加 1 ;如果不存在就将 admin 这个字符串插入到 主键key 字段中,并且使 count(*) 变为 1;接着取username字段第二个值也为 admin ,查找虚拟表中的 主键key 中已经存在 admin 字符串,就直接将 count(*) 加 1;…… …… ……;到username字段第四个值为 chen 时,查找虚拟表中的 主键key 字段不存在 chen 这个值,此时就将 chen 这个字符串再次插入到 主键key 字段中,并且使 count(*) 变为 1,就这样一直执行下去,直到所有的字段值分组完毕。之后系统就按照虚拟表中的结果将其显示出来。
取完username字段第四个值(即:chen)时的 虚拟表 ,如下图:
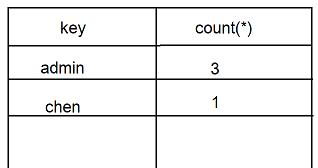
2、如果参数是字符串:"username",而不是字段名:
语句执行的时候仍会建立一个虚拟表(里面有两个字段,分别是 key 主键,count(*)),如果参数是字符串 "username",那系统就不会去取user表中的字段值了,而是直接取字符串:"username"作为值,然后查找比对虚拟表中 key 字段的值,发现没有字符串 "username",便插入 "username" 这个字符串,并将count(*) 变为1;然后执行第二次,在虚拟表 key 字段中查找 "username" 这个字符串,发现有,便使 count(*) 加 1,就这样执行 7 次,count(*)便变成了 7。
四、理解完上面之后,让我们进入正题,请看下两条的sql group by报错注入语句,以及其运行结果:
1、select count(*) from information_schema.tables group by concat(database(),floor(rand(0)*2));
2、select count(*) from information_schema.tables group by concat(database(),floor(rand()*2));
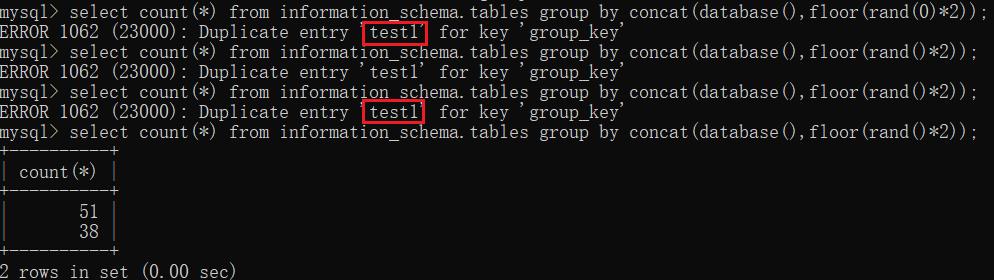
可以看到,user表所在的 test 数据库被成功的爆了出来。但是你们仔细观察的话会发现第二个sql语句爆率并不是100%,有时会爆不出来,为什么呢?别着急,继续往下看:
原因:在我们已经有上面的铺垫之后其实要理解这个sql group by报错注入的原理已经不难了:
以第一条语句为例:select count(*) from information_schema.tables group by concat(database(),floor(rand(0)*2));
首先我们知道
- floor(rand(0)*2) 产生的随机数的前六位 一定是 “011011”(上面已经提到过了),
- concat()函数用于将前后两个字符串相连
- database ()函数由于返回当前使用数据库的名称。
- concat(database(),floor(rand(0)*2))生成由‘database()+‘0’’和‘database()+‘1’’组成的随机数列,则前六个数列一定依次是:
- \'database()+\'0\'\'
- \'database()+\'1\'\'
- \'database()+\'1\'\'
- \'database()+\'0\'\'
- \'database()+\'1\'\'
- \'database()+\'1\'\'
报错的过程:
- 查询前默认会建立空的虚拟表
- 取第一条记录,执行concat(database(),floor(rand(0)*2))(第一次执行),计算结果为\'database()+\'0\'\',查询虚拟表,发现\'database()+\'0\'\'主键值不存在,则会执行插入命令,此时又会再次执行一次concat(database(),floor(rand(0)*2))(第二次执行),计算结果为\'database()+\'1\'\',然后插入该值。(即:虽然查询比对的是\'database()+\'0\'\',但是真正插入的是执行第二次的结果\'database()+\'1\'\',这个过程,concat(database(),floor(rand(0)*2))执行了两次,查询比对时执行了一次,插入时执行了一次)。
- 取第二条记录,执行concat(database(),floor(rand(0)*2))(第三次执行),计算结果为\'database()+\'1\'\',查询虚拟表,发现\'database()+\'1\'\'主键值存在,所以不再执行插入指令,也就不会执行第二次concat(database(),floor(rand(0)*2)),count(*) 直接加1,(即,查询为\'database()+\'1\'\',直接加1,这个过程,concat(database(),floor(rand(0)*2))执行了一次)。
- 取第三条记录,执行concat(database(),floor(rand(0)*2))(第四次执行),计算结果为\'database()+\'0\'\',查询虚拟表,发现\'database()+\'0\'\'主键值不存在,则会执行插入命令,此时又会再次执行一次concat(database(),floor(rand(0)*2))(第五次执行),计算结果为\'database()+\'1\'\'将其作为主键值,但是\'database()+\'1\'\'这个主键值已经存在于虚拟表中了,由于主键值必需唯一,所以会发生报错。而报错的结果就是 \'database()+\'1\'\'即 \'test1\',从而得出数据库的名称 test。%e6%b5%85%e6%98%93%e6%b7%b1
由以上过程发现,总共取了三条记录(所以表中的记录数至少为三条),floor(rand(0)*2)执行了五次。
五、总结
现在,解释了group by报错注入的原理,想必大家已经知道为什么:
- select count(*) from information_schema.tables group by concat(database(),floor(rand(0)*2));一定可以注入成功(要成功注入,前提表中的记录数至少为三条)
- 而select count(*) from information_schema.tables group by concat(database(),floor(rand()*2));却不一定了吧。(要成功注入,前提表中的记录数至少为两条)
没错是因为floor(rand()*2)的前几位随机数顺序是不固定的,所以并不能保证一定会注入成功,但是其只需两条记录数就行了(因为它可能会产出 “0101” ,这样只需两条记录就可以成功注入,你可以试试推导一下),这也算是它的优势吧。