Redis的数据类型可谓是Redis的精华所在,同样的数据类型,但不同的值对应的存储结构也是不同的。比如:当你存储一个短字符串(小于44字节),实际存储的结构是embstr;长字符串对应的实际存储结构是raw,这样设计的目的就是为了更好的节约内存。
问题:Redis都有哪些数据类型呢?
最常用的数据类型有5种:String(字符串类型)、Hash(字典类型)、List(列表类型)、Set(集合类型)、ZSet(有序集合类型)。
那么这些数据类型都支持哪些操作呢?我们来一一介绍,当然Redis支持的数据结构已经不止这五种了,还有几个更高级的数据结构,我们后面介绍,但是最常用的还是上面五种。
不过在介绍之前需要安装Redis,安装过程比较简单就不说了,我这里就使用docker安装了,比较简单。
通过:docker run -d -p 6379:6379 --name redis redis后台启动。
启动之后,我们需要了解一下Redis的前置知识。
Redis默认有16个数据库,数据库名类似于数组的下表,从0到15,默认使用0号库。select:切换数据库,比如select 1就表示切换到1号库统一密码管理,16个库都是一样的密码,要么都ok要么都连接不上。默认端口是6379
Redis字符串(String)
Redis的string类型,是一个key对应一个value。并且底层是使用自己内部实现的简单动态字符串(SSD),来表示 String 类型。 没有直接使用 C 语言定义的字符串类型。
struct sdshdr{
//记录 buf 数组中已使用字节的数量
//等于 SDS 保存字符串的长度
int len;
//记录 buf 数组中未使用字节的数量
int free;
//字节数组,用于保存字符串
char buf[];
}
然后我们来看看其支持的api操作。
set key value:给指定的key设置value
127.0.0.1:6379> set name hanser
OK
127.0.0.1:6379> set word "hello world"
OK # 如果字符串之间有空格,我们可以使用双引号包起来
设置成功之后会返回一个ok,表示设置成功。除此之外,set还可以指定一些可选参数。
set key value ex 60:设置的时候指定过期时间为60秒,等价于setex key 60 valueset key value px 60:设置的时候指定过期时间为60毫秒,等价于psetex key 60 valueset key value nx:只有key不存在的时候才会设置,存在的话则会什么也不做,而如果不加nx则会覆盖。等价于setnx key valueset key value xx:只有key存在的时候才会设置,注意:对于xx来说,没有setxx key value
我们发现默认参数使用set足够了,因此未来可能会移除setex、psetex、setnx。另外,我们可以同一个key多次set,相当于对原来的值进行了覆盖。
get key:获取指定key对应的value
127.0.0.1:6379> get name
"hanser"
127.0.0.1:6379> get word
"hello world"
127.0.0.1:6379> get age
(nil)
如果key不存在,那么返回nil,也就是C语言中的NULL,python中的None、golang里的nil。存在的话,则返回key对应的value。
del key1 key2···:删除指定key,可以同时删除多个
127.0.0.1:6379> set age 28
OK
127.0.0.1:6379> get name
"hanser"
127.0.0.1:6379> get age
"28" # 虽然我们设置的是一个数值,但是在Redis中都是字符串格式
127.0.0.1:6379> del name age gender
(integer) 2 # 会返回删除的key的个数,表示有效删除了两个,而gender不存在,因此无法删除一个不存在的key
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379> get nil
(nil)
127.0.0.1:6379>
append key value:追加
如果key存在,那么会将value的值追加到key对应的值的末尾,如果不存在,那么会重新设置,类似于set key value。
127.0.0.1:6379> set name han
OK
127.0.0.1:6379> set age 2
OK
127.0.0.1:6379> append name ser
(integer) 6 # 返回拼接之后的字符数量
127.0.0.1:6379> append age 8
(integer) 2 # 按照字符串的格式拼接
127.0.0.1:6379> get name
"hanser"
127.0.0.1:6379> get age
"28"
127.0.0.1:6379> append gender female
(integer) 6 # gender不存在,相当于重新设置,或者你理解为往一个空字符后面追加也行
127.0.0.1:6379> get gender
"female"
127.0.0.1:6379>
strlen key:查看对应key的长度
127.0.0.1:6379> strlen name
(integer) 6
127.0.0.1:6379> strlen age
(integer) 2
127.0.0.1:6379> strlen not_exists
(integer) 0 # 不存在的key返回0
127.0.0.1:6379>
incr key:为key存储的值自增1,必须可以转成整型,否则报错。如果不存在key,默认先设置该key值为0,然后自增1
127.0.0.1:6379> get age
"28"
127.0.0.1:6379> incr age
(integer) 29 # 返回自增后的结果
127.0.0.1:6379> get age
"29"
127.0.0.1:6379> incr age1
(integer) 1
127.0.0.1:6379> get age1
"1"
127.0.0.1:6379> incr name
(error) ERR value is not an integer or out of range
127.0.0.1:6379>
decr key:为key存储的值自减1,必须可以转成整型,否则报错。如果不存在key,默认先设置该key值为0,然后自减1
127.0.0.1:6379> decr age
(integer) 28
127.0.0.1:6379> decr age2
(integer) -1
127.0.0.1:6379>
incrby key number:为key存储的值自增number,必须可以转成整型,否则报错,如果不存在的话,默认先将该值设置为0,然后自增number
127.0.0.1:6379> incrby age 20
(integer) 48
127.0.0.1:6379> incrby age3 5
(integer) 5
127.0.0.1:6379>
decrby key number:为key存储的值自减number,必须可以转成整型,否则报错,如果不存在的话,默认先将该值设置为0,然后自减number
127.0.0.1:6379> decrby age 20
(integer) 28
127.0.0.1:6379> decrby age4 5
(integer) -5
127.0.0.1:6379> decrby age4 -5
(integer) 0 # 指定负数也是可以的,同理incrby也是如此
127.0.0.1:6379>
getrange key start end:获取指定value的同时指定范围,第一个字符为0,最后一个为-1。注意:redis中的索引都是包含结尾的,不管是这里的getrange,还是后面的列表操作,索引都是包含两端的。
127.0.0.1:6379> get name
"hanser"
127.0.0.1:6379> getrange name 0 -1
"hanser"
127.0.0.1:6379> getrange name 0 4
"hanse"
127.0.0.1:6379> getrange name -3 -1
"ser"
127.0.0.1:6379> getrange name -3 10086
"ser"
127.0.0.1:6379> getrange name -3 -4
""
127.0.0.1:6379>
我们看到,索引是可以从后往前数,但是只能从前往后、不能从后往前获取。也就是getrange word -1 -3是不可以的,会返回一个空字符串,因为-1在-3的后面。
setrange key start value:从索引为start的地方开始,将key对应的值替换为value,替换的个数等于value的个数。
127.0.0.1:6379> get name
"hanser"
127.0.0.1:6379> setrange name 0 you
(integer) 6 # 从索引为0的地方开始替换,替换三个字符,因为我们指定了3个字符
127.0.0.1:6379> get name
"youser"
127.0.0.1:6379> setrange name 10 you
(integer) 13 # 从索引为10的地方开始替换,但是字符串索引最大为6,因此会使用\\x00填充
127.0.0.1:6379> get name
"youser\\x00\\x00\\x00\\x00you"
127.0.0.1:6379> setrange myself 3 gagaga
(integer) 9 # 对于不存在的key也是如此
127.0.0.1:6379> get myself
"\\x00\\x00\\x00gagaga"
127.0.0.1:6379> set name hanser
OK
127.0.0.1:6379> setrange name 0 "han han han han"
(integer) 15 # 替换的字符串长度比相应的key长没有关系,会自动扩充
127.0.0.1:6379> get name
"han han han han"
mset key1 value1 key2 value2:同时设置多个key value
这是一个原子性操作,要么都设置成功,要么都设置不成功。注意:这些都是会覆盖原来的值的,如果不想这样的话,可以使用msetnx,这个命令只会在所有的key都不存在的时候才会设置。
mget key1 key2:同时返回多个key对应的value
如果有的key不存在,那么返回nil。
127.0.0.1:6379> get name
"han han han han"
127.0.0.1:6379> mset name hanser age 28
OK
127.0.0.1:6379> mget name age
1) "hanser"
2) "28"
127.0.0.1:6379>
getset key value:先返回key的旧值,然后设置新值
127.0.0.1:6379> getset name yousa
"hanser"
127.0.0.1:6379> get name
"yousa"
127.0.0.1:6379> getset ping pong
(nil)
127.0.0.1:6379> get ping
"pong"
127.0.0.1:6379>
如果有的key不存在,那么返回nil,然后设置。
另外,Redis中还有很多关于key的操作,有必要提前说一下。
keys pattern:查看名称满足pattern所有的key,像string、list、hash、set、zset都有自己的key,key不可以重名,比如有一个叫name的string,那么就不可以再有一个还叫name的。
127.0.0.1:6379> keys * # 查看所有的key
1) "gender"
2) "word"
3) "ping"
4) "name"
5) "age2"
6) "age1"
7) "age"
8) "myself"
9) "age3"
10) "age4"
127.0.0.1:6379> keys *a* # 查看包含a的key
1) "name"
2) "age2"
3) "age1"
4) "age"
5) "age3"
6) "age4"
127.0.0.1:6379> keys age? # 查看以age开头、总共4个字符的key
1) "age2"
2) "age1"
3) "age3"
4) "age4"
exists key:判断某个key是否存在
127.0.0.1:6379> exists name
(integer) 1
127.0.0.1:6379> exists name1
(integer) 0 # 存在返回1,不存在返回0
127.0.0.1:6379> exists name name1
(integer) 1 # 也可以指定多个key,返回存在的key的个数,但是此时无法判断到底是哪个key存在
ttl key:查看还有多少秒过期,-1表示永不过期,-2表示已过期
127.0.0.1:6379> ttl name
(integer) -1 # -1表示永不过期
127.0.0.1:6379> ttl name1
(integer) -2 # -2表示已经过期
127.0.0.1:6379>
key是可以设置过期时间的,如果过期了就不能再用了。我们看到name1这个key压根就不存在,返回的也是-2,因为过期了就相当于不存在了。而name是-1,表示永不过期
expire key 秒钟:为给定的key设置过期时间
127.0.0.1:6379> expire name 60
(integer) 1 # 设置60s,设置成功返回1
127.0.0.1:6379> ttl name
(integer) 55 # 查看时间,还剩下55秒
127.0.0.1:6379> expire name1 60
(integer) 0 # name1不存在,设置失败,返回0
127.0.0.1:6379>
这里设置60s的过期时间。另外设置完之后,在过期时间结束之前是可以再次设置的,比如我先设置了60s,然后快结束的时候我再次设置60s,那么还会再持续60s。
type key:查看你的key是什么类型
127.0.0.1:6379> type name
none # name过期了,相当于不存在了,因此为none
127.0.0.1:6379> type age
string # 类型为string
127.0.0.1:6379>
move key db:将key移动到指定的db中
127.0.0.1:6379> flushdb
OK # 清空当前库,如果是清空所有库,可以使用flushall,当然后面都可以加上async,表示异步删除,我们前面说过的
127.0.0.1:6379> set name hanser
OK
127.0.0.1:6379> keys *
1) "name"
127.0.0.1:6379> move name 3
(integer) 1 # 将name移动到索引为3的库中
127.0.0.1:6379> keys *
(empty array) # 此时当前库已经没有name了
127.0.0.1:6379> select 3
OK # 切换到索引为3的库中
127.0.0.1:6379[3]> keys *
1) "name" # keys *查看,发现name已经有了
127.0.0.1:6379[3]> select 0 # 切换回来
OK
127.0.0.1:6379>
然后我们来看看如何使用Python来操作Redis,这里操作字符串
笔者是Python系的,所以如果你不搞Python的话,那么可以不用看。
import redis
# 获取得到的默认是字节,如果指定了decode_responses,会自动进行解码
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
# 1. set key value
client.set("name", "yousa", ex=None, px=None, nx=False, xx=False)
# 2. get key
print(client.get("name"), client.get("age")) # yousa None
# 3. del key1 key2 ...
print(client.delete("name", "age")) # 1
# 4. apend key value
client.set("name", "han")
print(client.append("name", "ser")) # 6
print(client.get("name")) # hanser
# 5. strlen key
print(client.strlen("name")) # 6
# 6. incr key
client.set("age", 28)
# incr key其实等价于incrby key 1,因此在这里两个命令都是通过incr实现
# 第二个参数为1,是默认值,当然我们也可以自己指定
client.incr("age", 1)
print(client.get("age")) # 29
# 7. decr key
client.decr("age", 10)
print(client.get("age")) # 19
# 8. getrange key start end
print(client.getrange("name", -3, -1)) # ser
# 9. setrange key start value
client.setrange("name", 3, "sa")
print(client.get("name")) # hansar
# 10. mset key1 value1 key2 value2
client.mset({"name": "yousa", "age": 20})
# 11. mget key1 key2
print(client.mget(["name", "age", "gender"])) # [\'yousa\', \'20\', None]
# 12. getset key value
print(client.getset("name", "hanser")) # yousa
print(client.get("name")) # hanser
# 13. keys pattern
print(client.keys("*")) # [\'name\', \'age\']
# 14. exists key
print(client.exists("name"), client.exists("ping")) # 1 0
# 15. ttl key
print(client.ttl("name")) # -1
# 16. expire key 秒钟
client.expire("name", 60)
import time; time.sleep(2)
print(client.ttl("name")) # 58
# 17. type key
print(client.type("name")) # string
# 18. move key db
client.move("name", 15)
print(client.get("name")) # None
# 需要重新连接
print(redis.Redis(host="47.94.174.89", decode_responses="utf-8", db=15).get("name")) # hanser
我们看到,和Redis命令之间是几乎没有什么区别的。
字符串这种数据结构可以用在什么地方呢?
我们讨论完字符串的相关操作,那么我们还要理解字符串要用在什么地方。
首先字符串类型的使用场景有很多,但从功能的角度来区分,大致可分为以下两种:
1. 字符串存储和操作;2. 整数类型和浮点类型的存储和计算。
其最常用的业务场景大致分为以下几个。
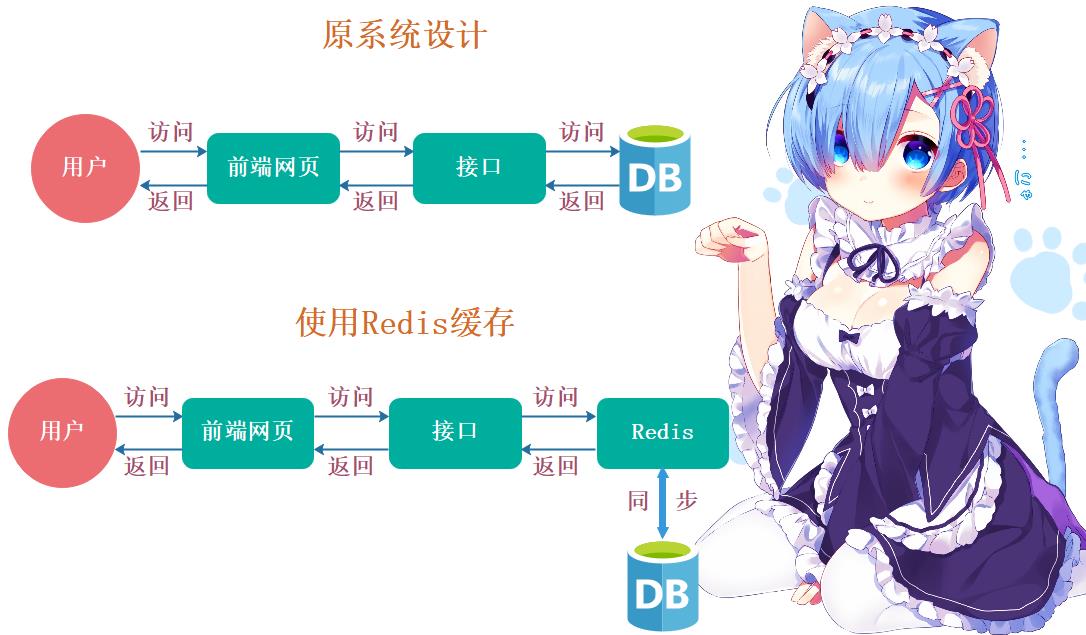
1. 页面数据缓存
我们知道,一个系统最宝贵的资源就是数据库资源,随着公司业务的发展壮大,数据库的存储量也会越来越大,并且要处理的请求也越来越多,当数据量和并发量到达一定级别之后,数据库就变成了拖慢系统运行的“罪魁祸首”,为了避免这种情况的发生,我们可以把查询结果放入缓存(Redis)中,让下次同样的查询直接去缓存系统取结果,而非查询数据库,这样既减少了数据库的压力,同时也提高了程序的运行速度。
画一张图来说明一下:
2. 数据计算与统计
Redis 可以用来存储整数和浮点类型的数据,并且可以通过命令直接累加并存储整数信息,这样就省去了每次先要取数据、转换数据、拼加数据、再存入数据的麻烦,只需要使用一个命令就可以完成此流程。比如:微博、哔哩哔哩等社交平台,我们经常会点赞,然后还有点赞数。每点一个赞,点赞数就加1,这个功能就完全可以交给Redis实现。
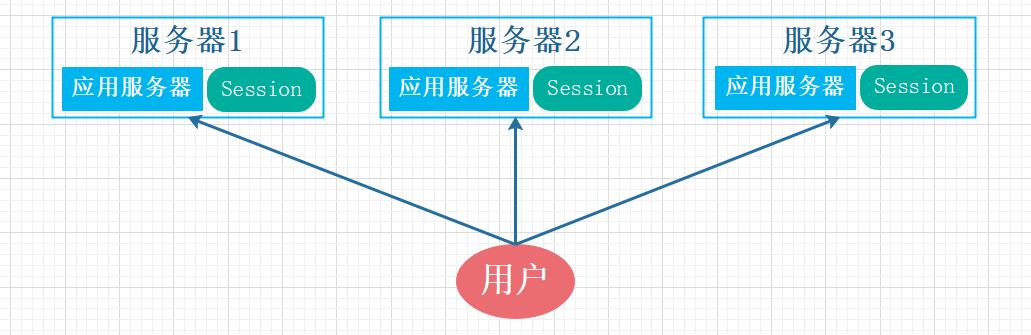
3. 共享Session信息
通常我们在开发后台管理系统时,会使用 Session 来保存用户的会话(登录)状态,这些 Session 信息会被保存在服务器端,但这只适用于单系统应用,如果是分布式系统此模式将不再适用。
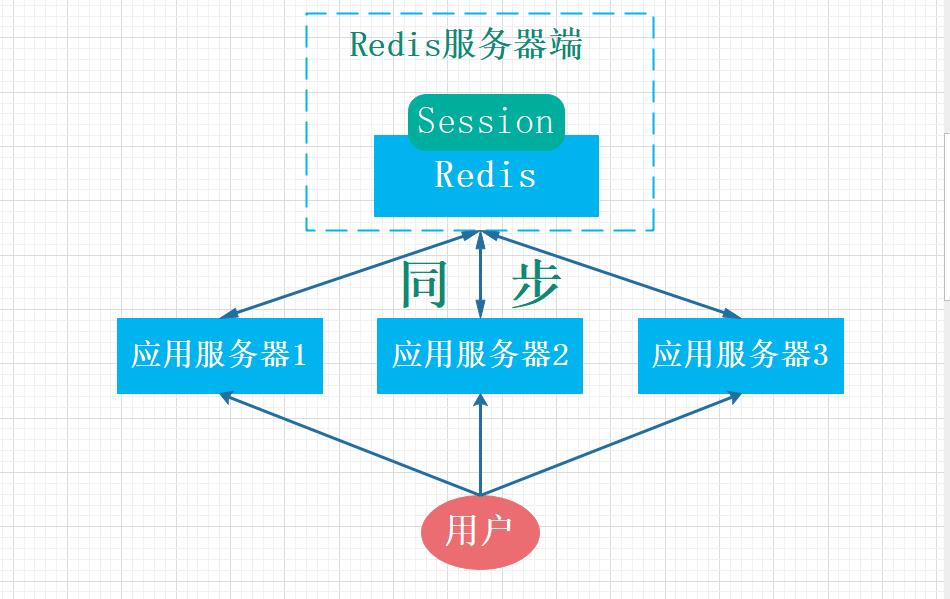
例如用户A的 Session 信息被存储在第一台服务器,但第二次访问时用户A被分配到第二台服务器,这个时候服务器并没有用户A的 Session 信息,就会出现需要重复登录的问题。分布式系统每次会把请求随机分配到不同的服务器,因此我们需要借助缓存系统对这些 Session 信息进行统一的存储和管理,这样无论请求发送到哪台服务器,服务器都会去统一的缓存系统获取相关的 Session 信息,这样就解决了分布式系统下 Session 存储的问题。
分布式系统单独存储Session
分布式系统使用统一的缓存系统存储Session
Redis列表(List)
列表类型 (List) 是一个使用链表结构存储的有序结构,它的元素插入会按照先后顺序存储到链表结构中,因此它的元素操作 (插入、删除) 时间复杂度为 O(1),所以相对来说速度还是比较快的,但它的查询时间复杂度为 O(n),因此查询可能会比较慢。
Redis中的列表和字符串比较类似,只不过字符串是一个key对应一个value、获取的时候直接通过key来获取,而列表是一个key对应的多个value、获取的时候通过key + 索引来获取。
下面我们来看看它所支持的api操作
lpush key value1 value2···:将多个值设置到列表里面,从左边push
rpush key value1 value2···:将多个值设置到列表里面,从右边push
127.0.0.1:6379> lpush girls mashiro koishi
(integer) 2 # 返回插入成功之后,列表的元素个数。这里是lpush,所以此时列表内的元素是:koishi mashiro
127.0.0.1:6379> rpush girls satori
(integer) 3
127.0.0.1:6379>
lrange key start end:遍历列表,索引从0开始,最后一个为-1,且包含两端
127.0.0.1:6379> lrange girls 0 -1
1) "koishi"
2) "mashiro"
3) "satori"
127.0.0.1:6379> lrange girls 0 2
1) "koishi"
2) "mashiro"
3) "satori"
127.0.0.1:6379> lrange girls 0 1
1) "koishi"
2) "mashiro"
127.0.0.1:6379> lrange lst 0 -1
(empty array) # 对不存在的列表使用lrange,会得到空数组
lpop key:从列表的左端弹出一个值,列表长度改变
rpop key:从列表的右端弹出一个值,列表长度改变
127.0.0.1:6379> lpop girls
"koishi"
127.0.0.1:6379> rpop girls
"satori"
127.0.0.1:6379> lrange girls 0 -1
1) "mashiro"
127.0.0.1:6379>
lindex key index:获取指定索引位置的元素,列表长度不变
127.0.0.1:6379> lindex girls 0
"mashiro"
127.0.0.1:6379> lrange girls 0 -1
1) "mashiro"
127.0.0.1:6379> lindex lst 0
(nil) # 对不存在的列表使用lindex,会得到nil
127.0.0.1:6379>
llen key:获取指定列表的长度
127.0.0.1:6379> llen girls
(integer) 1
127.0.0.1:6379> llen lst
(integer) 0 # 对不存在的列表使用llen,会得到0。
127.0.0.1:6379>
lrem key count value:删除count个value,如果count为0,那么将全部删除
127.0.0.1:6379> lpush lst 1 1 1 1
(integer) 4
127.0.0.1:6379> lrem lst 3 1
(integer) 3 # 删除3个1
127.0.0.1:6379> lrange lst 0 -1
1) "1"
127.0.0.1:6379>
ltrim key start end:从start截取到end,再重新赋值给key
127.0.0.1:6379> rpush lst 2 3 4 5
(integer) 5
127.0.0.1:6379> lrange lst 0 -1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
127.0.0.1:6379> ltrim lst 4 -1
OK # 将5 重新赋值给lst
127.0.0.1:6379> lrange lst 0 -1
1) "5"
127.0.0.1:6379>
rpoplpush key1 key2:移除key1的最后一个元素,并添加到key2的开头
127.0.0.1:6379> rpush lst1 1 2 3
(integer) 3
127.0.0.1:6379> rpush lst2 11 22 33
(integer) 3
127.0.0.1:6379> rpoplpush lst1 lst2
"3"
127.0.0.1:6379> lrange lst2 0 -1
1) "3"
2) "11"
3) "22"
4) "33"
127.0.0.1:6379>
lset key index value:将key中索引为index的元素设置为value
127.0.0.1:6379> lrange lst2 0 -1
1) "3"
2) "11"
3) "22"
4) "33"
127.0.0.1:6379> lset lst2 1 2333
OK
127.0.0.1:6379> lrange lst2 0 -1
1) "3"
2) "2333"
3) "22"
4) "33"
127.0.0.1:6379> lset lst2 10 2333
(error) ERR index out of range # 索引越界则报错,显然索引为10越界了
127.0.0.1:6379>
linsert key before/after value1 value2:在value1的前面或者后面插入一个value2
127.0.0.1:6379> rpush lst3 1 2 2 3
(integer) 4
127.0.0.1:6379> linsert lst3 before 2 666
(integer) 5
127.0.0.1:6379> lrange lst3 0 -1
1) "1"
2) "666"
3) "2"
4) "2"
5) "3"
127.0.0.1:6379> linsert lst3 after 2 2333
(integer) 6
127.0.0.1:6379> lrange lst3 0 -1
1) "1"
2) "666"
3) "2"
4) "2333"
5) "2"
6) "3"
127.0.0.1:6379>
我们看到插入位置是由第一个元素决定的
老规矩,我们来看看如何使用Python来操作Redis中的列表,和操作字符串是类似的,因为Python操作Redis的模块提供的api和Redis-cli控制台所使用的api是高度一致的。
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
# 1. lpush key value1 value2 ...
client.lpush("list", 1, 2, 3)
# 2. rpush key value1 value2 ...
client.rpush("list", 2, 2, 2)
# 3. lrange key start end
print(client.lrange("list", 0, -1)) # [\'3\', \'2\', \'1\', \'2\', \'2\', \'2\']
# 4. lpop key
print(client.lpop("list")) # 3
# 5. rpop key
print(client.rpop("list")) # 2
# 6. lindex key
print(client.lindex("list", 0)) # 2
# 7. llen key
print(client.llen("list")) # 4
# 8. lrem key count value
client.lrem("list", 1, 2)
print(client.lrange("list", 0, -1)) # [\'1\', \'2\', \'2\']
# 9. ltrim key start end
print(client.lrange("list", 0, -1)) # [\'1\', \'2\', \'2\']
client.ltrim("list", 0, -2)
print(client.lrange("list", 0, -1)) # [\'1\', \'2]
# 10. rpoplpush key1 key2
client.rpush("list1", 1, 2, 3)
client.rpush("list2", 11, 22, 33)
client.rpoplpush("list1", "list2")
print(client.lrange("list2", 0, -1)) # [\'3\', \'11\', \'22\', \'33\']
# 11. lset key index value
client.lset("list2", -1, "古明地觉")
print(client.lrange("list2", 0, -1)) # [\'3\', \'11\', \'22\', \'古明地觉\']
# 12. linsert key before/after value1 value2
client.linsert("list2", "before", 22, "aaa")
client.linsert("list2", "after", 22, "bbb")
print(client.lrange("list2", 0, -1)) # [\'3\', \'11\', \'aaa\', \'22\', \'bbb\', \'古明地觉\']
然后我们来分析一下Redis列表类型的内部实现
127.0.0.1:6379> object encoding list
"quicklist"
127.0.0.1:6379>
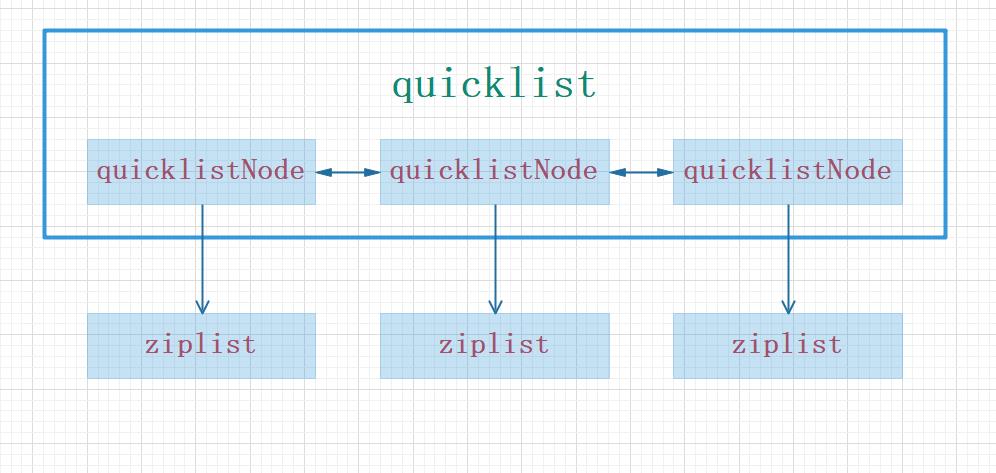
我们看到列表底层的数据类型是quicklist(快速列表),quicklist是Redis3.2引入的数据类型,早期的列表是使用ziplist(压缩列表)和双向列表组成的,Redis3.2的时候改为quicklist。
我们看一下quicklist的源码实现。
typedef struct quicklist { // src/quicklist.h
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* ziplist 的个数 */
unsigned long len; /* quicklist 的节点数 */
unsigned int compress : 16; /* LZF 压缩算法深度 */
//...
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl; /* 对应的 ziplist */
unsigned int sz; /* ziplist 字节数 */
unsigned int count : 16; /* ziplist 个数 */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* 该节点先前是否被压缩 */
unsigned int attempted_compress : 1; /* 节点太小无法压缩 */
//...
} quicklistNode;
typedef struct quicklistLZF {
unsigned int sz;
char compressed[];
} quicklistLZF;
从源码中可以看出quicklist是一个双向链表,链表中的每一个节点实际上是一个ziplist,结构如图所示。
ziplist 作为 quicklist 的实际存储结构,它本质是一个字节数组,ziplist 数据结构如下图所示:

zlbytes:压缩列表字节长度,占 4 字节;zltail:压缩列表尾元素相对于起始元素地址的偏移量,占 4 字节;zllen:压缩列表的元素个数;entryX:压缩列表存储的所有元素,可以是字节数组或者是整数;zlend:压缩列表的结尾,占 1 字节。
使用场景
列表的典型使用场景有以下两个:
- 消息队列:列表类型可以使用 rpush 实现先进先出的功能,同时又可以使用 lpop 轻松的弹出(查询并删除)第一个元素,所以列表类型可以用来实现消息队列;
- 文章列表:对于博客站点来说,当用户和文章都越来越多时,为了加快程序的响应速度,我们可以把用户自己的文章存入到 List 中,因为 List 是有序的结构,所以这样又可以完美的实现分页功能,从而加速了程序的响应速度。
Redis字典(Hash)
字典类型(Hash)又被成为散列类型或是哈希表类型,它底层是通过哈希表存储的,这个哈希表包含两列数据:字段和值,假设我们使用字典来存储文章的详情信息,存储结构如图所示:
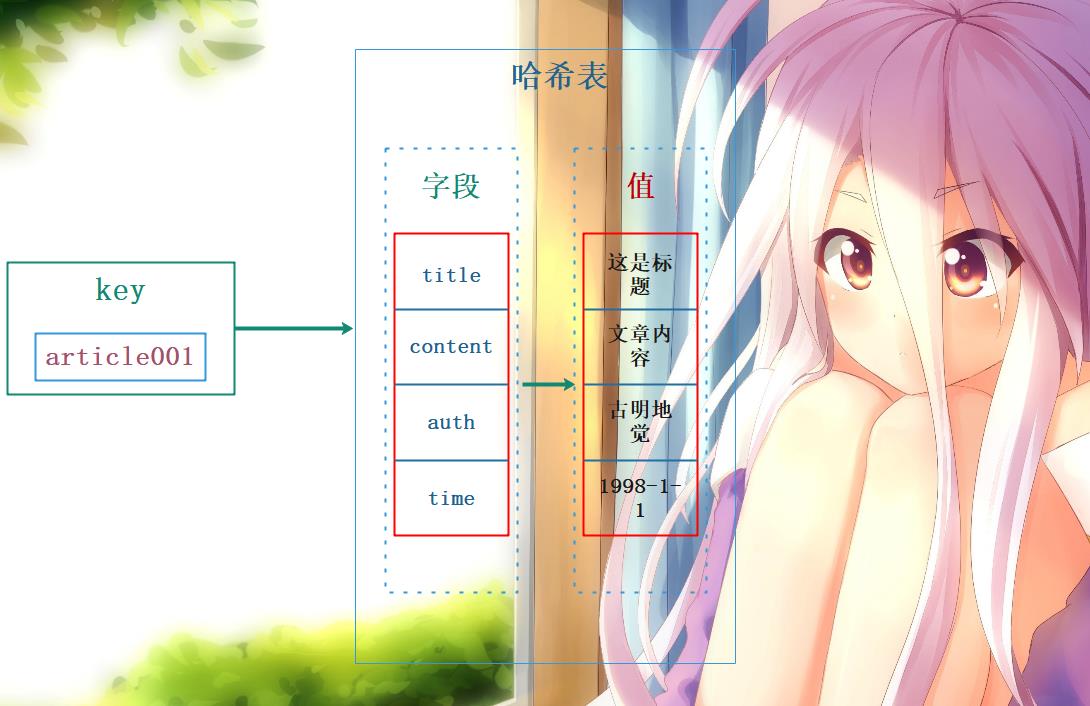
同理我们也可以使用字典来存储用户信息,并且使用字典存储此类信息是不需要序列化和反序列化的,所以使用起来更加的方便和高效。
下面看看字典所支持的api
hset key field1 value1 field2 value2···:设置键值对,可同时设置多个。(这里的键值对指的是field、value,而命令中的key指的是字典、或者哈希表的名称)
127.0.0.1:6379> hset girl name hanser age 28 gender f
(integer) 3 # 返回3表示成功设置3个键值对
127.0.0.1:6379>
hget key field:获取hash中field对应的value
127.0.0.1:6379> hget girl name
"hanser"
127.0.0.1:6379>
hgetall key:获取hash中所有的键值对
127.0.0.1:6379> hgetall girl
1) "name"
2) "hanser"
3) "age"
4) "28"
5) "gender"
6) "f"
127.0.0.1:6379>
hlen key:获取hash中键值对的个数
127.0.0.1:6379> hlen girl
(integer) 3
127.0.0.1:6379>
hexists key field:判断hash中是否存在指定的field
127.0.0.1:6379> hexists girl name
(integer) 1 # 存在返回1
127.0.0.1:6379> hexists girl where
(integer) 0 # 不存在返回0
127.0.0.1:6379>
hkeys/hvals key:获取hash中所有的field和所有的value
127.0.0.1:6379> hkeys girl
1) "name"
2) "age"
3) "gender"
127.0.0.1:6379> hvals girl
1) "hanser"
2) "28"
3) "f"
127.0.0.1:6379>
hincrby key field number:将hash中字段field对应的值自增number,number必须指定,显然field对应的value要能解析成整型
127.0.0.1:6379> hincrby girl age 3
(integer) 31 # 返回增加之后的值
127.0.0.1:6379> hincrby girl age -3
(integer) 28 # 可以为正、可以为负
127.0.0.1:6379>
hsetnx key field1 value1:每次只能设置一个键值对,不存在则设置,存在则无效。
127.0.0.1:6379> hsetnx girl name yousa
(integer) 0 # name存在,所以设置失败
127.0.0.1:6379> hget girl name
"hanser" # 还是原来的结果
127.0.0.1:6379> hsetnx girl length 155.5
(integer) 1 # 设置成功
127.0.0.1:6379> hget girl length
"155.5"
127.0.0.1:6379>
hdel key field1 field2······:删除hash中的键,当然键没了,整个键值对就没了
127.0.0.1:6379> hdel girl name age
(integer) 2
127.0.0.1:6379> hget girl name
(nil)
127.0.0.1:6379> hget girl age
(nil)
127.0.0.1:6379>
然后老规矩,看看如何使用Python操作Redis的字典
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
# 1. hset key field1 value1 field2 value2···
# 这里的hset只能设置单个值,如果设置多个需要使用hmset,传入key和字典
client.hmset("girl1", {"name": "yousa", "age": 26, "length": 148})
# 2. hget key field
print(client.hget("girl1", "name")) # yousa
# 3. hgetall key
print(client.hgetall("girl1")) # {\'name\': \'yousa\', \'age\': \'26\', \'length\': \'148\'}
# 这里还支持同时获取多个值
print(client.hmget("girl1", ["name", "age"])) # [\'yousa\', \'26\']
# 4. hlen key
print(client.hlen("girl1")) # 3
# 5. hexists key field
print(client.hexists("girl1", "name")) # True
print(client.hexists("girl1", "name1")) # False
# 6. hkeys/hvals key
print(client.hkeys("girl1")) # [\'name\', \'age\', \'length\']
print(client.hvals("girl1")) # [\'yousa\', \'26\', \'148\']
# 7. hincrby key field number
client.hincrby("girl1", "age", 2)
print(client.hget("girl1", "age")) # 28
# 8. hsetnx key field1 value1
client.hsetnx("girl1", "name", "hanser")
client.hsetnx("girl1", "gender", "female")
print(client.hmget("girl1", ["name", "gender"])) # [\'yousa\', \'female\']
# 9. hdel key field1 field2······
client.hdel("girl1", "name", "age")
print(client.hmget("girl1", ["name", "age"])) # [None, None]
那么Redis中的字典是如何实现的呢?
字典类型本质上是由数组和链表结构组成的,来看字典类型的源码实现:
typedef struct dictEntry { // dict.h
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 下一个 entry
} dictEntry;
字典类型的数据结构,如下图所示:
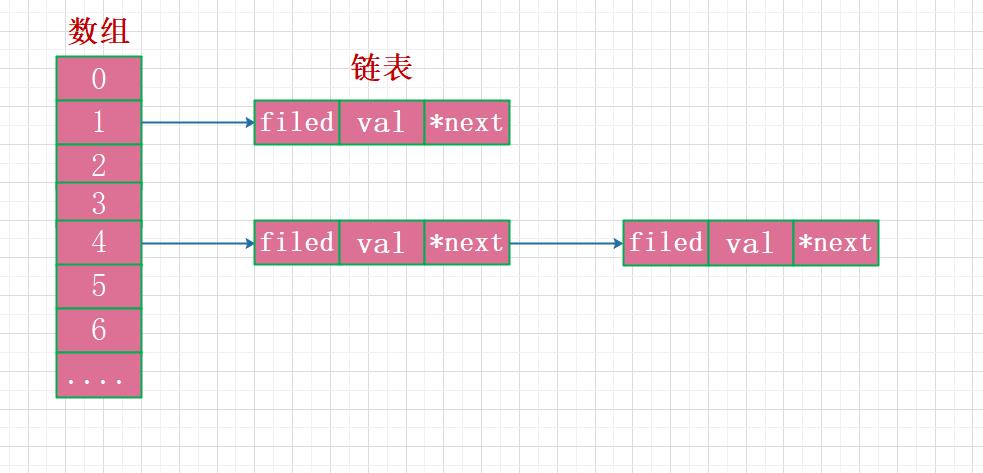
通常情况下字典类型会使用数组的方式来存储相关的数据,但发生哈希冲突时才会使用链表的结构来存储数据。
哈希冲突
字典类型的存储流程是先将键进行 Hash 计算,得到存储键对应的数组索引,再根据数组索引进行数据存储,但在小概率事件下可能会出完全不相同的键进行 Hash 计算之后,得到相同的 Hash 值,这种情况我们称之为哈希冲突。
哈希冲突一般通过链表的形式解决,相同的哈希值会对应一个链表结构,每次有哈希冲突时,就把新的元素插入到链表的尾部,请参考上面数据结构的那张图。
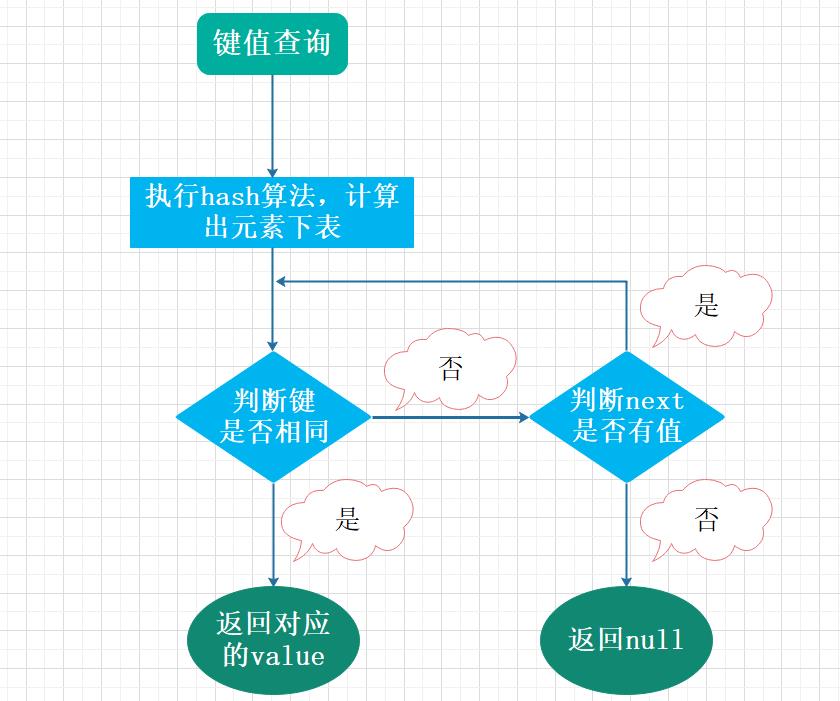
键查询的流程如下:
通过算法 (Hash,计算和取余等) 操作获得数组的索引值,根据索引值找到对应的元素;判断元素和查找的键值是否相等,相等则成功返回数据,否则需要查看 next 指针是否还有对应其他元素,如果没有,则返回 null,如果有的话,重复此步骤。
渐进式rehash
Redis 为了保证应用的高性能运行,提供了一个重要的机制——渐进式 rehash。 渐进式 rehash 是用来保证字典缩放效率的,也就是说在字典进行扩容或者缩容是会采取渐进式 rehash 的机制。
1) 扩容
当元素数量等于数组长度时就会进行扩容操作,源码在 dict.c 文件中,核心代码如下:
int dictExpand(dict *d, unsigned long size)
{
/* 需要的容量小于当前容量,则不需要扩容 */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n;
unsigned long realsize = _dictNextPower(size); // 重新计算扩容后的值
/* 计算新的扩容大小等于当前容量,不需要扩容 */
if (realsize == d->ht[0].size) return DICT_ERR;
/* 分配一个新的哈希表,并将所有指针初始化为NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
if (d->ht[0].table == NULL) {
// 第一次初始化
d->ht[0] = n;
return DICT_OK;
}
d->ht[1] = n; // 把增量输入放入新 ht[1] 中
d->rehashidx = 0; // 非默认值 -1,表示需要进行 rehash
return DICT_OK;
}
从以上源码可以看出,如果需要扩容则会申请一个新的内存地址赋值给 ht[1],并把字典的 rehashindex 设置为 0,表示之后需要进行 rehash 操作。
2) 缩容
当字典的使用容量不足总空间的 10% 时就会触发缩容,Redis 在进行缩容时也会把 rehashindex 设置为 0,表示之后需要进行 rehash 操作。
3) 渐进式rehash流程
在进行渐进式 rehash 时,会同时保留两个 hash 结构,新键值对加入时会直接插入到新的 hash 结构中,并会把旧 hash 结构中的元素一点一点的移动到新的 hash 结构中,当移除完最后一个元素时,清空旧 hash 结构,主要的执行流程如下:
1. 扩容或者缩容时把字典中的字段 rehashidx 标识为 0;2. 在执行定时任务或者执行客户端的 hset、hdel 等操作指令时,判断是否需要触发 rehash 操作(通过 rehashidx 标识判断),如果需要触发 rehash 操作,也就是调用 dictRehash 函数,dictRehash 函数会把 ht[0] 中的元素依次添加到新的 Hash 表 ht[1] 中;3. rehash 操作完成之后,清空 Hash 表 ht[0],然后对调 ht[1] 和 ht[0] 的值,把新的数据表 ht[1] 更改为 ht[0],然后把字典中的 rehashidx 标识为 -1,表示不需要执行 rehash 操作。
那么Redis中的字典都在哪些场景中使用呢?
哈希字典的典型使用场景如下:
商品购物车,购物车非常适合用哈希字典表示,使用人员唯一编号作为 key(哈希表的名称),哈希表本身则负责存储商品的 id 和数量等信息;比如:hset person_id0001 product_id product001 count 20存储用户的属性信息,使用人员唯一编号作为key,哈希表存储属性字段和对应的值;存储文章详情页信息等。
因此通过上面内容我们知道了字典类型实际是由数组和链表组成的,当字典进行扩容或者缩容时会进行渐进式 rehash 操作,渐进式 rehash 是用来保证 Redis 运行效率的,它的执行流程是同时保留两个哈希表,把旧表中的元素一点一点的移动到新表中,查询的时候会先查询两个哈希表,当所有元素都移动到新的哈希表之后,就会删除旧的哈希表。
Redis集合(Set)
Redis的集合和列表是类似的,都是用来存储多个标量,但是它和列表又有不同:
1. 列表中的元素是可以重复的,而集合中的元组不会重复。2. 列表在插入元素的时候可以保持顺序,而集合不保证顺序(集合在存储数据时,底层也是使用了哈希表,后面会说。)。
下面我们来看看它所支持的api操作
sadd key value1 value2···:向集合插入多个元素,如果重复会自动去重
127.0.0.1:6379> sadd set1 1 1 2 3
(integer) 3 # 返回成功插入的元素的个数,这里是3个,因为元素有重复。两个1,只会插入一个
127.0.0.1:6379>
smembers key:查看集合的所有元素
127.0.0.1:6379> smembers set1
1) "1"
2) "2"
3) "3"
127.0.0.1:6379>
sismember key value:查看value是否在集合中
127.0.0.1:6379> sismember set1 1
(integer) 1 # 在的话返回1
127.0.0.1:6379> sismember set1 5
(integer) 0 # 不在返回0
127.0.0.1:6379>
scard key:查看集合的元素个数
127.0.0.1:6379> scard set1
(integer) 3
127.0.0.1:6379>
srem key value1 value2 ······:删除集合中的元素
127.0.0.1:6379> srem set1 1 2
(integer) 2 # 返回删除成功的元素个数
127.0.0.1:6379> srem set1 1 2
(integer) 0
127.0.0.1:6379>
spop key count:随机弹出集合中count个元素,注意:count是可以省略的,如果省略则弹出1个。另外一旦弹出,原来的集合里面也就没有了。
127.0.0.1:6379> smembers set1
1) "3" # 还有一个元素
127.0.0.1:6379> sadd set1 1 2
(integer) 2 # 添加两个进去
127.0.0.1:6379>
127.0.0.1:6379> smembers set1
1) "1"
2) "2"
3) "3"
127.0.0.1:6379> spop set1 1
1) "2" # 弹出1个元素,返回弹出的元素
127.0.0.1:6379> smembers set1
1) "1"
2) "3"
127.0.0.1:6379>
srandmember key count:随机获取集合中count个元素,注意:count是可以省略的,如果省略则获取1个。可以看到类似spop,但是srandmember不会删除集合中的元素。
127.0.0.1:6379> smembers set1
1) "1"
2) "3"
127.0.0.1:6379> srandmember set1 1
1) "1"
127.0.0.1:6379> smembers set1
1) "1"
2) "3"
smove key1 key2 value:将key1当中的value移动到key2当中,因此key1当中的元素会少一个,key2会多一个(前提是value在key2中不重复,否则key2还和原来保持一致)。
127.0.0.1:6379> smembers set1
1) "1"
2) "3"
127.0.0.1:6379> smembers set2
1) "1"
127.0.0.1:6379> smove set1 set2 3
(integer) 1
127.0.0.1:6379> smembers set1
1) "1"
127.0.0.1:6379> smembers set2
1) "1"
2) "3"
127.0.0.1:6379>
sinter key1 key2:返回即在key1中,又在key2中的元素
sunion key1 key2:返回在key1中,或者在key2中的元素
sdiff key1 key2:返回在key1中,但不在key2中的元素
127.0.0.1:6379> sinter set1 set2
1) "2"
2) "3"
127.0.0.1:6379> sunion set1 set2
1) "1"
2) "2"
3) "3"
4) "4"
127.0.0.1:6379> sdiff set1 set2
1) "1"
127.0.0.1:6379> sdiff set2 set1
1) "4"
127.0.0.1:6379>
下面我们来看看如何使用Python操作Redis的集合
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
# 1. sadd key value1 value2·····
client.sadd("s1", 1, 2, 3, 1)
# 2. smembers key
print(client.smembers("s1")) # {\'2\', \'1\', \'3\'}
# 3. sismember key value
print(client.sismember("s1", 1)) # True
print(client.sismember("s1", 5)) # False
# 4. scard key
print(client.scard("s1")) # 3
# 5. srem key value1 value2······
client.srem("s1", 1, 2)
print(client.smembers("s1")) # {\'3\'}
# 6. spop key count
print(client.smembers("s1")) # {\'3\'}
client.spop("s1", 1)
print(client.smembers("s1")) # set()
# 7. srandmember key count
client.sadd("s1", 1, 2, 3)
print(client.smembers("s1")) # {\'2\', \'1\', \'3\'}
client.srandmember("s1", 2)
print(client.smembers("s1")) # {\'2\', \'1\', \'3\'}
# 8. smove key1 key2 value
client.sadd("s2", 1)
client.smove("s1", "s2", 3)
print(client.smembers("s2")) # {\'1\', \'3\'}
# 9. sinter key1 key2
# 10. sunion key1 key2
# 11. sdiff key1 key2
client.sadd("s3", 1, 2, 3)
client.sadd("s4", 2, 3, 4)
print(client.sinter("s3", "s4")) # {\'2\', \'3\'}
print(client.sunion("s3", "s4")) # {\'2\', \'4\', \'1\', \'3\'}
print(client.sdiff("s3", "s4")) # {\'1\'}
那么Redis的集合底层是如何实现的呢?
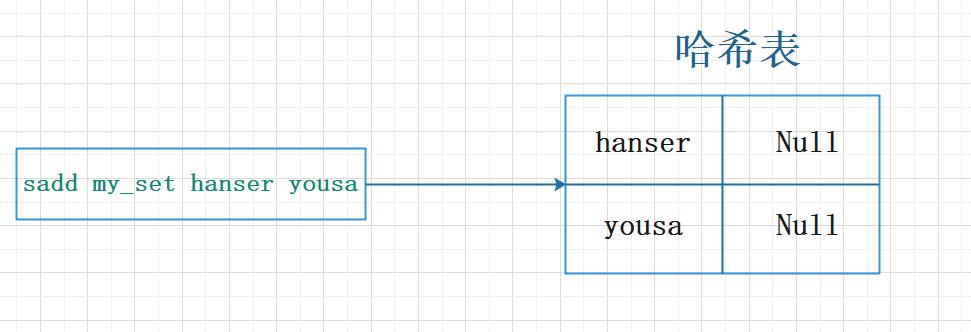
集合类型是由 intset (整数集合) 或 hashtable (普通哈希表) 组成的。当集合类型以 hashtable 存储时,哈希表的 key 为要插入的元素值,而哈希表的 value 则为 Null,如下图所示:
当集合中所有的值都为整数时,Redis 会使用 intset 结构来存储,如下代码所示:
127.0.0.1:6379> sadd s 1 2 3
(integer) 3
127.0.0.1:6379> object encoding s
"intset"
127.0.0.1:6379>
从上面代码可以看出,当所有元素都为整数时,集合会以 intset 结构进行(数据)存储。 当发生以下两种情况时,会导致集合类型使用 hashtable 而非 intset 存储: 1)当元素的个数超过一定数量时,默认是 512 个,该值可通过命令 set-max-intset-entries xxx 来配置。 2)当元素为非整数时,集合将会使用 hashtable 来存储,如下代码所示:
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
client.sadd("s1", *range(513))
# 超过512个,使用哈希表存储
print(client.object("encoding", "s1")) # hashtable
client.sadd("s2", *range(512))
# 没超过512个,使用intset
print(client.object("encoding", "s2")) # intset
client.sadd("s3", "hanser")
# 不是整数,使用哈希表存储
print(client.object("encoding", "s3")) # hashtable
源码解析
集合源码在 t_set.c 文件中,核心源码如下:
/*
* 添加元素到集合
* 如果当前值已经存在,则返回 0 不作任何处理,否则就添加该元素,并返回 1。
*/
int setTypeAdd(robj *subject, sds value) {
long long llval;
if (subject->encoding == OBJ_ENCODING_HT) { // 字典类型
dict *ht = subject->ptr;
dictEntry *de = dictAddRaw(ht,value,NULL);
if (de) {
// 把 value 作为字典到 key,将 Null 作为字典到 value,将元素存入到字典
dictSetKey(ht,de,sdsdup(value));
dictSetVal(ht,de,NULL);
return 1;
}
} else if (subject->encoding == OBJ_ENCODING_INTSET) { // inset 数据类型
if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {
uint8_t success = 0;
subject->ptr = intsetAdd(subject->ptr,llval,&success);
if (success) {
// 超过 inset 的最大存储数量,则使用字典类型存储
if (intsetLen(subject->ptr) > server.set_max_intset_entries)
setTypeConvert(subject,OBJ_ENCODING_HT);
return 1;
}
} else {
// 转化为整数类型失败,使用字典类型存储
setTypeConvert(subject,OBJ_ENCODING_HT);
serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);
return 1;
}
} else {
// 未知编码(类型)
serverPanic("Unknown set encoding");
}
return 0;
}
以上这些代码验证了,我们上面所说的内容,当元素都为整数并且元素的个数没有到达设置的最大值时,键值的存储使用的是 intset 的数据结构,反之到元素超过了一定的范围,又或者是存储的元素为非整数时,集合会选择使用 hashtable 的数据结构进行存储。
使用场景
集合类型的经典使用场景如下:
微博关注我的人和我关注的人都适合用集合存储,可以保证人员不会重复;中奖人信息也适合用集合类型存储,这样可以保证一个人不会重复中奖。
Redis有序集合(Sorted Set)
Redis的有序集合相比集合多了一个排序属性:score(分值),对于有序集合zset来说,每个存储元素相当于有两个值,一个是有序集合的元素值,一个是排序值。有序集合存储的元素值也是不重复的,但分数可以重复。
当我们把学生的成绩存储在有序集合中,它的存储结构如下图所示:
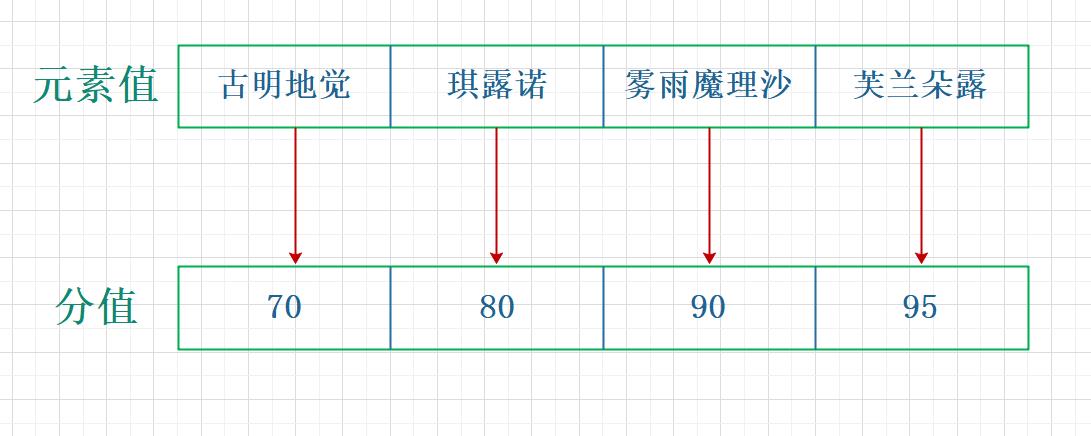
下面我们来看看它所支持的api操作
zadd key score1 value1 score2 value2:设置score和value
127.0.0.1:6379> zadd zset1 1 n1 2 n2 3 n2
(integer) 2
127.0.0.1:6379>
一个score对应一个value,value不会重复,因此即便我们这里添加了3个,但是后面两个的value都是n2,所以实际上只有两个元素,并且n2是以后一个score为准,因为相当于覆盖了。
zscore key value:获取value对应的score
127.0.0.1:6379> zscore zset1 n2
"3"
127.0.0.1:6379>
zrange key start end:获取指定范围的value,递增排列,这里是基于索引获取
127.0.0.1:6379> zadd zset2 1 n1 3 n3 2 n2 4 n4
(integer) 4
127.0.0.1:6379> zrange zset2 0 -1
1) "n1"
2) "n2"
3) "n3"
4) "n4"
127.0.0.1:6379> zrange zset2 0 2
1) "n1"
2) "n2"
3) "n3"
127.0.0.1:6379>
如果结尾加上with scores参数,那么会和score一同返回,注意:score是在下面。我们看到这个zset有点像hash啊,value是hash的k,score是hash的v
127.0.0.1:6379> zrange zset2 0 2 withscores
1) "n1"
2) "1"
3) "n2"
4) "2"
5) "n3"
6) "3"
127.0.0.1:6379>
zrevrange key start end:获取所有的value,递减排列,同理也有withscores参数
127.0.0.1:6379> zrevrange zset2 0 -1
1) "n4"
2) "n3"
3) "n2"
4) "n1"
127.0.0.1:6379>
zrangebyscore key 开始score 结束score:获取>=开始score <=结束score的value,递增排列,同理也有withscores参数
zrevrangebyscore key 结束score 开始score:获取>=开始score <=结束score的value,递减排列,同理也有withscores参数。注意:这里的开始和结束是相反的。
127.0.0.1:6379> zadd zset3 1 n1 2 n2 3 n3 4 n4 5 n5 6 n6 7 n7
(integer) 7
127.0.0.1:6379> zrangebyscore zset3 3 6
1) "n3"
2) "n4"
3) "n5"
4) "n6"
127.0.0.1:6379> zrevrangebyscore zset3 6 3
1) "n6"
2) "n5"
3) "n4"
4) "n3"
127.0.0.1:6379> zrangebyscore zset3 (3 (6
1) "n4" # 如果在分数前面加上了(, 那么会不匹配边界,同理也支持withscores
2) "n5"
127.0.0.1:6379> zrevrangebyscore zset3 (6 (3
1) "n5"
2) "n4"
127.0.0.1:6379>
zrem key value1 value2···:移除对应的value
127.0.0.1:6379> zrem zset3 n1 n2 n3 n4
(integer) 4
127.0.0.1:6379> zrange zset3 0 -1
1) "n5"
2) "n6"
3) "n7"
zcard key:获取集合的元素个数
127.0.0.1:6379> zcard zset3
(integer) 3
127.0.0.1:6379>
zcount key 开始分数区间 结束分数区间:获取集合指定分数区间内的元素个数
127.0.0.1:6379> zcount zset3 6 8
(integer) 2
127.0.0.1:6379> zcount zset3 5 7
(integer) 3
127.0.0.1:6379>
下面看看如何使用Python操作Redis的有序集合
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
# 1. zadd key score1 value1 score2 value2
# 这里使用字典的方式传递,因为value不重复,所以作为字典传递的话,value作为键、分数作为值
client.zadd("zset1", {"n1": 1, "n2": 2, "n3": 3})
# 2. zscore key value
print(client.zscore("zset1", "n1")) # 1.0
# 3. zrange key start end
print(client.zrange("zset1", 0, -1)) # [\'n1\', \'n2\', \'n3\']
print(client.zrange("zset1", 0, -1, withscores=True)) # [(\'n1\', 1.0), (\'n2\', 2.0), (\'n3\', 3.0)]
# 4. zrevrange key start end
print(client.zrevrange("zset1", 0, -1)) # [\'n3\', \'n2\', \'n1\']
print(client.zrevrange("zset1", 0, -1, withscores=True)) # [(\'n3\', 3.0), (\'n2\', 2.0), (\'n1\', 1.0)]
# 5. zrangebyscore key 开始score 结束score
# 6. zrevrangebyscore key 结束score 开始score
print(client.zrangebyscore("zset1", 1, 3)) # [\'n1\', \'n2\', \'n3\']
print(client.zrevrangebyscore("zset1", 3, 1)) # [\'n3\', \'n2\', \'n1\']
# 7. zrem key value1 value2······
client.zrem("zset1", "n1", "n2")
print(client.zrange("zset1", 0, -1)) # [\'n3\']
# 8. zcard key
print(client.zcard("zset1")) # 1
# 9. zcount key 开始分数区间 结束分数区间
client.zadd("zset2", {"n1": 1, "n2": 2, "n3": 3, "n4": 4, "n5": 5})
print(client.zcount("zset2", 1, 4)) # 4
下面看看Redis有序集合的底层实现
有序集合是由 ziplist (压缩列表) 或 skiplist (跳跃表) 组成的。
1)ziplist
当数据比较少时,有序集合使用的是 ziplist 存储的,如下代码所示:
127.0.0.1:6379> zadd my_zset 1 n1 2 n2
(integer) 2
127.0.0.1:6379> object encoding my_zset
"ziplist"
127.0.0.1:6379>
从结果可以看出,有序集合把键值对存储在 ziplist 结构中了。 有序集合使用 ziplist 格式存储必须满足以下两个条件:
有序集合保存的元素个数要小于等于 128 个;有序集合保存的所有元素成员的长度都必须小于等于 64 字节。
如果不能满足以上两个条件中的任意一个,有序集合将会使用 skiplist 结构进行存储。 接下来我们来测试以下,当有序集合中某个元素长度大于 64 字节时会发生什么情况? 代码如下:
import redis
client = redis.Redis(host="47.94.174.89", decode_responses="utf-8")
# 元素长度超过64
client.zadd("my_zset2", {"a" * 65: 1})
print(client.object("encoding", "my_zset2")) # skiplist
# 集合元素超过128个
client.zadd("my_zset3", dict(zip(range(129), range(129))))
print(client.object("encoding", "my_zset3")) # skiplist
通过以上代码可以看出,当有序集合保存的元素的长度大于 64 字节、或者元素个数超过128个时,有序集合就会从 ziplist 转换成为 skiplist。
可以通过配置文件中的 zset-max-ziplist-entries(默认 128)和 zset-max-ziplist-value(默认 64)来设置有序集合使用 ziplist 存储的临界值。
2)skiplist
skiplist 数据编码底层是使用 zset 结构实现的,而 zset 结构中包含了一个字典和一个跳跃表,源码如下:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
1. 跳跃表实现原理
跳跃表的结构如下图所示:
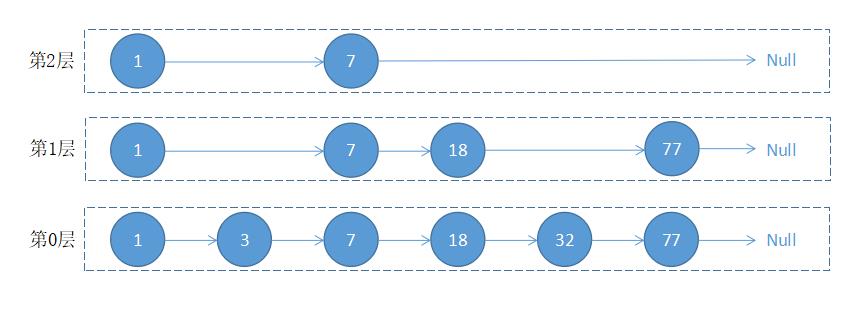
根据以上图片展示,当我们在跳跃表中查询值 32 时,执行流程如下:
从最上层开始找,1 比 32 小,在当前层移动到下一个节点进行比较;7 比 32 小,当前层移动下一个节点比较,由于下一个节点指向 Null,所以以 7 为目标,移动到下一层继续向后比较;18 小于 32,继续向后移动查找,对比 77 大于 32,以 18 为目标,移动到下一层继续向后比较;对比 32 等于 32,值被顺利找到。
从上面的流程可以看出,跳跃表会想从最上层开始找起,依次向后查找,如果本层的节点大于要找的值,或者本层的节点为 Null 时,以上一个节点为目标,往下移一层继续向后查找并循环此流程,直到找到该节点并返回,如果对比到最后一个元素仍未找到,则返回 Null。
2. 为什么是跳跃表?而非红黑树?
因为跳跃表的性能和红黑树基本相近,但却比红黑树更好实现,所以 Redis 的有序集合会选用跳跃表来实现存储。
使用场景
有序集合的经典使用场景如下:< 以上是关于3. Redis有哪些数据类型?的主要内容,如果未能解决你的问题,请参考以下文章