redis-缓存设计-文章管理
Posted 意犹未尽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis-缓存设计-文章管理相关的知识,希望对你有一定的参考价值。
需求
文章根据创建时间排序,用户可以给文章分,影响排序,用户指定时间只能打一次分,不能重复打。文章支持分组
key定义
/** * content表的id生成器 * */ public final static String CONTENT_ID_GENERATOR="cs:id:generator:content"; /** * 数据key %s为数据id * hash */ public final static String CONTENT_KEY = "cs:content:%s"; /** * 维护各个group的数据 %s为groupId * zset */ public final static String GROUP_KEY = "cs:content:group:%s"; /** * 记录文章打分 后的排序文章排序 * zset */ public final static String CONTENT_SCORE_KEY = "cs:content:routing:score"; /** * 记录指定文章的用户打分记录 %s为文章id * zset */ public final static String CONTENT_VOTE_KEY = "cs:content:routing:score:%s"; /** * 记录所有文章的排序 创建时间排序 * zset */ public final static String CONTENT_SORT_KEY = "cs:content:routing:sort"; /** * 7天的秒数 86400位1天的秒数 */ public final static long ONE_WEEK_IN_SECONDS = 7 * 86400;
发布文章
代码
/** * 发布指定文章 * @param conn * @param title * @param content * @param link */ public static void postArticle(Jedis conn,String title,String content,String link){ Long contentId=conn.incr(CONTENT_ID_GENERATOR); //数据 hash key String key = String.format(CONTENT_KEY, contentId); Long now=System.currentTimeMillis(); HashMap<String,String> data=new HashMap<>(); data.put("id",contentId.toString()); data.put("title",title); data.put("content",content); data.put("link",link); data.put("votes","0"); //保存 数据 conn.hmset(key,data); //设置创建时间排序 conn.zadd(CONTENT_SORT_KEY,now,contentId.toString()); //设置打分排序 conn.zadd(CONTENT_SCORE_KEY,now+1,contentId.toString()); }
此处利用hash存储文章信息,并通过2个zset维护创建时间排序和打分排序 id使用redis.incr是原子性的 线程安全的
数据json


[{ "id": 1, "title": "我爱成都大熊猫", "content": "哈哈哈哈", "link": "wwww.baidu.com" }, { "id": 2, "title": "我爱广州小蛮腰", "content": "哈哈哈哈", "link": "wwww.baidu.com" } ]
数据图解
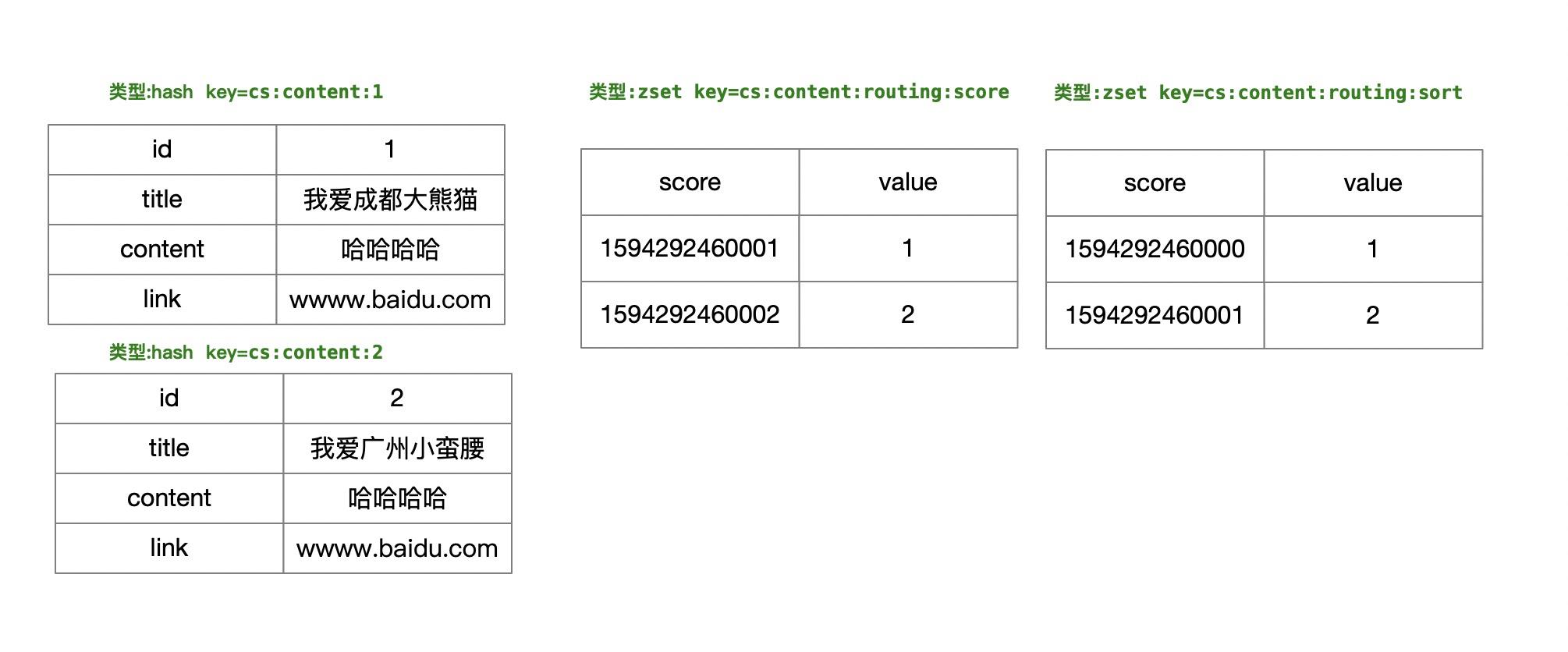
给文章分组
代码
/** * 将 指定文章分配到指定分组 * @param conn * @param contentId * @param group */ public static void addGroup(Jedis conn,Long contentId,String group){ conn.sadd(String.format(GROUP_KEY, group),contentId.toString()); }
通过set来保存组信息
图解
如将添加文章的数据 分别新增2个广州文章专区和 成都文章专区

给指定文章打分
代码
/** * 指定用户打分接口 * @param conn 连接 * @param userId 用户id * @param contentId 文章id */ public static void article_vote(Jedis conn, Long userId, Long contentId) { //数据 hash key String key = String.format(CONTENT_KEY, contentId); //维护已投票列表的key String scoreKey=CONTENT_SCORE_KEY; //文章已打分用户 String voteKey=String.format(CONTENT_VOTE_KEY,contentId); //创建时间排序的key String sortKey = CONTENT_SORT_KEY; //计算过期时间 因为创建时间作为分值,小于此时间的都是过期的 long index = System.currentTimeMillis() - ONE_WEEK_IN_SECONDS; /** * 根据评分判断是否是7天以前的 * zscore表示获取指定对象的评分 */ if (conn.zscore(sortKey, contentId.toString()) < index) { return; } //因为set是不允许重复的当第二次插入会<0 大于0表示重复打分 if (conn.sadd(voteKey,userId.toString())>0){ //数据hash的votes+1 并记录投票数量 conn.hincrBy(key,"votes",1); conn.zincrby(scoreKey,438,contentId.toString()); } }
图解
如给id为1的投一票

根据投票分页查询
代码
先从zeset获取id 然后根据id查询hash
/** * 打分排序分页分页查询 * @param conn * @param page * @param pageSize * @return */ public static Page<Map<String,String>> getArticle(Jedis conn, Integer page, Integer pageSize){ return getByKeyArticle(conn,CONTENT_SCORE_KEY,page,pageSize); } /** * 封装的公共的根据指定key分页查询 * @param conn * @param key * @param page * @param pageSize * @return */ public static Page<Map<String,String>> getByKeyArticle(Jedis conn, String key,Integer page, Integer pageSize){ Integer star=(page-1)*pageSize; Integer end=star+pageSize-1; //获得总条数 Long total= conn.zcard(key); //表示没有文章 if(total<=0){ return null; } List<Map<String,String>> datas=new ArrayList<>(); //根据评分排序获得指定区间数据 Set<String> ids= conn.zrevrange(key,star,end); for (String id: ids) { String contentkey=String.format(CONTENT_KEY,id); datas.add(conn.hgetAll(contentkey)); } Page<Map<String,String>> pageResult=new Page<>(); pageResult.setData(datas); pageResult.setTotal(total); return pageResult; }
分组查询根据投票排序
代码
根据 group set和打分zset取交集得出一个新的zset 打分2个取最大
public static Page<Map<String,String>> getByGroup(Jedis conn,String group,Integer page, Integer pageSize){ //临时集合key 交集 String newKey="cs:content:routing:groupNewKey:"+group; //避免频繁执行交集操作 所以缓存了60秒 if(!conn.exists(newKey)) { //zinterstore取2个集合的交集,分值会取分值相加的 conn.zinterstore(newKey, String.format(GROUP_KEY, group),CONTENT_SCORE_KEY); conn.expire(newKey, 60); } return getByKeyArticle(conn,newKey,page,pageSize); }
交集时间复杂度测试
/** * 2个100万 6毫秒 * 2个1000万超时 20多秒 * 一个1000万一个一万46毫秒 * 10个10万655毫秒 * 测试交集时间复杂度 * @param conn */ public static void testZinterstore(Jedis conn){ //conn.flushDB(); List<String> keys=new ArrayList<String>(); for(int i=0;i<20;i++){ keys.add("keys" + i); for(int j=0;j<100000;j++) { conn.zadd("keys" + i, new Double(j), String.valueOf(j)); // conn.zadd(key1,new Double(i),String.valueOf(i)); } } Long start=System.currentTimeMillis(); conn.zinterstore("newkey",keys.toArray(new String[keys.size()])); Long end=System.currentTimeMillis(); System.out.println("耗时"+(end-start)+"毫秒"); }
main方法测试代码
public static final void main(String[] args) throws Exception { Jedis conn = new Jedis("127.0.0.1", 6379); conn.select(15); Set<String> keys=conn.keys("cs:*");//因为命名规则 我们可以快速清除指定模块自定表的数据 cs为模块 content为表名 for (String key: keys) { conn.del(key); } //id=1 postArticle(conn,"我爱广州小蛮腰","嘿嘿","com.liqiang"); //id=2 postArticle(conn,"广州真好玩","嘿嘿","com.liqiang"); //id=3 postArticle(conn,"我爱成都大熊猫","嘿嘿","com.liqiang"); //id=4 postArticle(conn,"成都真好玩","嘿嘿","com.liqiang"); //id=5 postArticle(conn,"我爱上海东方明珠","嘿嘿","com.liqiang"); //id=6 postArticle(conn,"上海真好玩","嘿嘿","com.liqiang"); //id=7 postArticle(conn,"我爱北京天安门","嘿嘿","com.liqiang"); //id=8 postArticle(conn,"北京真好玩","嘿嘿","com.liqiang"); /** *因为我们id生成器从1开始,模拟从页面操作为指定文章分组 */ addGroup(conn,1L,"广州"); addGroup(conn,2L,"广州"); addGroup(conn,3L,"成都"); addGroup(conn,4L,"成都"); addGroup(conn,5L,"上海"); addGroup(conn,6L,"上海"); addGroup(conn,7L,"北京"); addGroup(conn,8L,"北京"); /** * 首先模拟查看全部文章的查询 */ System.out.println("=============================全部文章第一页数据============================"); System.out.println(JSON.toJSONString(getArticle(conn,1,4))); System.out.println("=============================全部文章第二页数据============================"); System.out.println(JSON.toJSONString(getArticle(conn,2,4))); System.out.println("=============================成都分组第一页数据============================"); System.out.println(JSON.toJSONString(getByGroup(conn,"成都",1,1))); System.out.println("=============================成都分组第二页数据============================"); System.out.println(JSON.toJSONString(getByGroup(conn,"成都",2,1))); /** * 给id为3的打分 */ article_vote(conn,1L,3L); article_vote(conn,2L,3L); article_vote(conn,3L,3L); conn.del("cs:content:routing:groupNewKey:"+"成都"); System.out.println("=============================打分后全部文章第一页数据============================"); System.out.println(JSON.toJSONString(getArticle(conn,1,4))); System.out.println("=============================打分后全部文章第二页数据============================"); System.out.println(JSON.toJSONString(getArticle(conn,2,4))); System.out.println("=============================打分后成都分组第一页数据============================"); System.out.println(JSON.toJSONString(getByGroup(conn,"成都",1,1))); System.out.println("=============================打分后成都分组第二页数据============================"); System.out.println(JSON.toJSONString(getByGroup(conn,"成都",2,1))); //testZinterstore(conn); }
以上是关于redis-缓存设计-文章管理的主要内容,如果未能解决你的问题,请参考以下文章