大数据 Hadoop
Posted 氧气
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据 Hadoop相关的知识,希望对你有一定的参考价值。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。一句话来讲Hadoop就是存储加计算。
Hadoop这个名字不是一个缩写,而是一个虚构的名字。该项目的创建者,Doug Cutting解释Hadoop的得名 :“这个名字是我孩子给一个棕黄色的大象玩具命名的。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
1、高可靠性 Hadoop按位存储和处理数据的能力值得人们信赖。
2、高扩展性 Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3、高效性 Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4、高容错性 Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5、低成本 与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
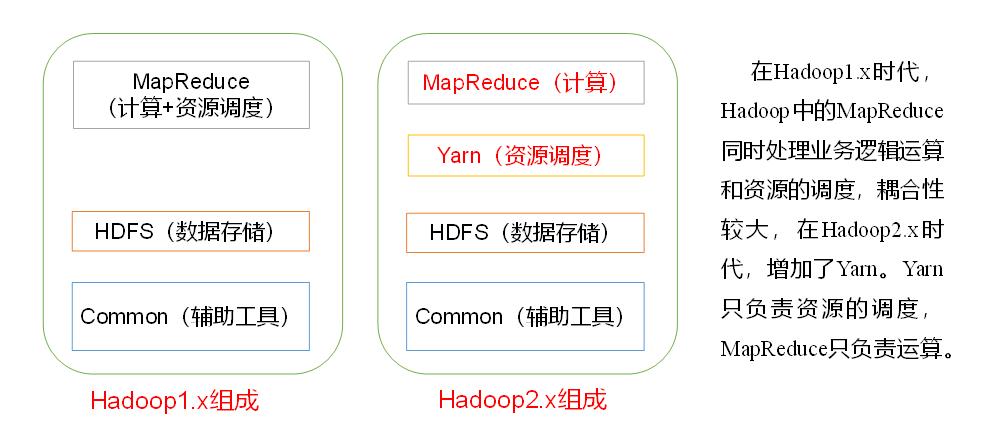
Hadoop Distributed File System(HDFS): 一个分布式文件系统,它提供对应用程序数据的高吞吐量访问。
Hadoop YARN(2.x版本以后才有的): 作业调度和集群资源管理的框架。
Hadoop MapReduce: 基于YARN的大型数据集并行处理系统。
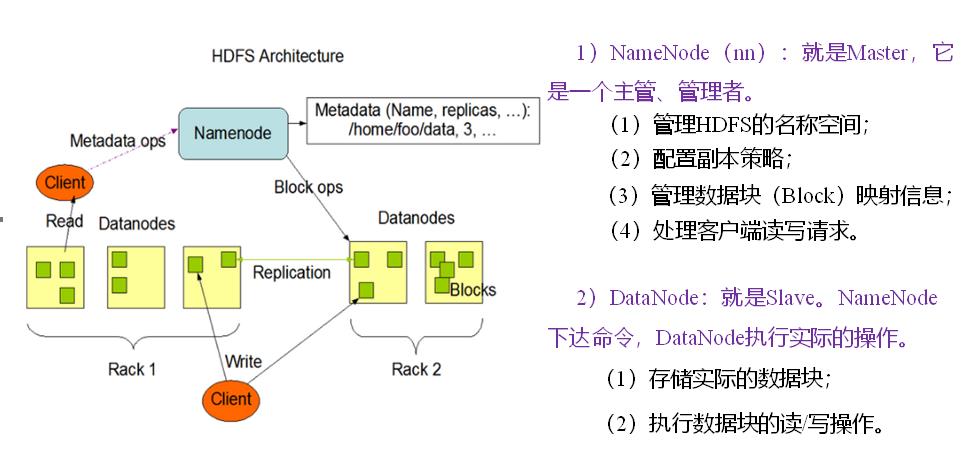
1 HDFS架构概述

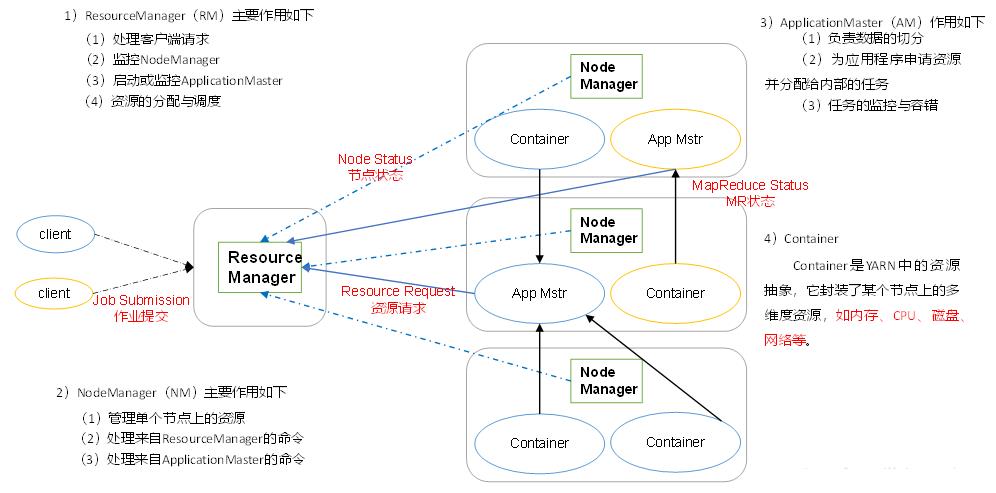
YARN架构概述,如图所示。
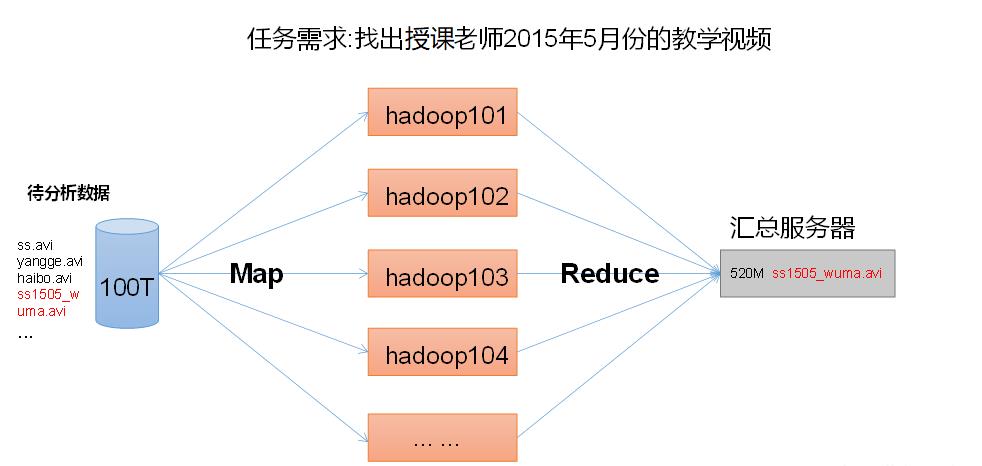
MapReduce将计算过程分为两个阶段:Map和Reduce,如图所示
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
了解了MapReduce的基本原理之后,我们看一下其两个版本之间的演变:
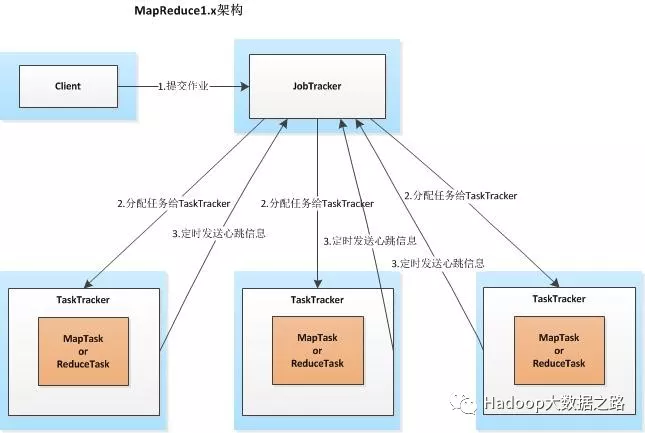
客户端向JobTracker提交一个作业,JobTracker会把这个作业拆分成多份,然后分配给TaskTracker(任务执行者)执行,TaskTracker会每隔一段时间向JobTracker发送心跳信息,如果JobTracker在一段时间内没有收到TaskTracker的心跳信息,JobTracker会认为TaskTracker挂掉,并把TaskTracker的任务分配给其它TaskTracker。该架构存在的问题:a、JobTracker节点压力过大;b、单点故障;3、只能跑MapReduce作业。
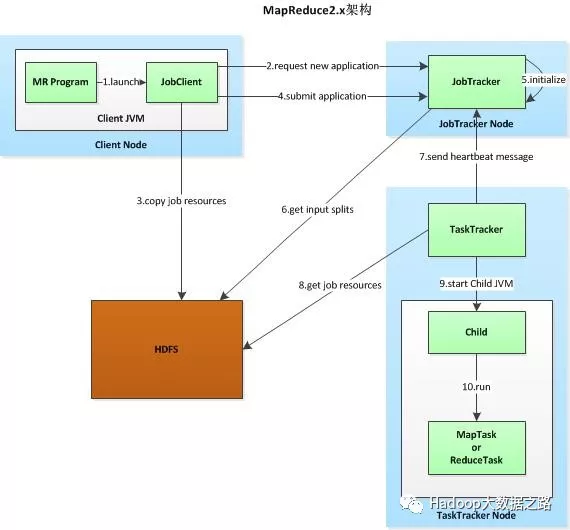

以上架构,在Hadoop版本中称为MRv2,所解决的问题:
1、更高的集群利用率,一个框架未使用的资源可由另一个框架进行使用,充分的避免资源浪费
2、很高的扩展性
3、yarn通过加入ApplicationMaster可变部分,可以编写不同的APPMst
4、监控job的tasks运行情况下放到ApplicationMaster中
以上是关于大数据 Hadoop的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之_03_Hadoop学习_01_入门_大数据概论+从Hadoop框架讨论大数据生态+Hadoop运行环境搭建(开发重点)