总结:这种适合把已有的mysql数据导入到Elasticsearch中
有一个csv文件,把里面的数据通过Navicat Premium 软件导入到数据表中,共有998条数据
文件下载地址:https://files.cnblogs.com/files/sanduzxcvbnm/SalesJan2009.zip
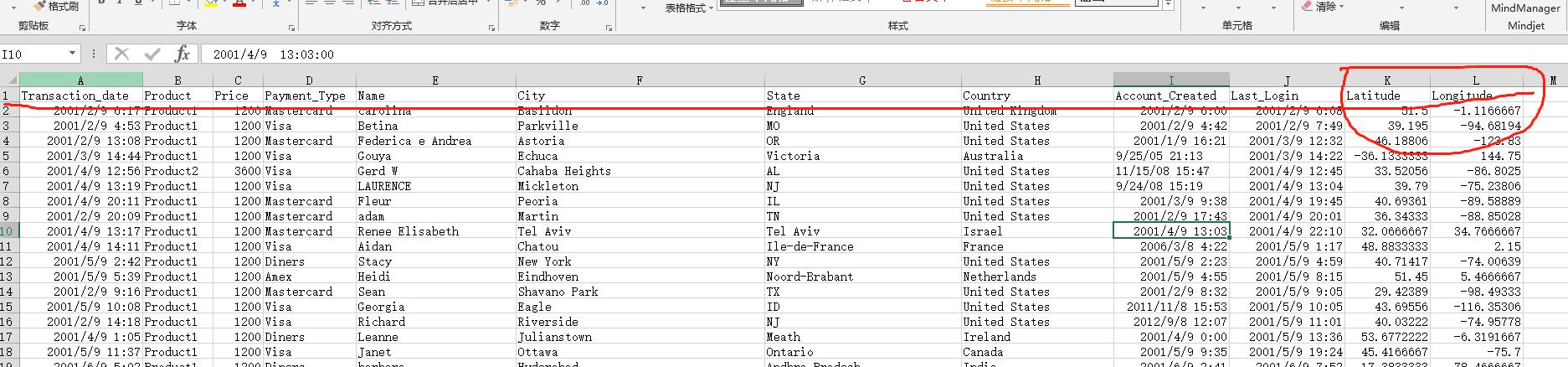
csv文件格式如下:
Logstash 配置
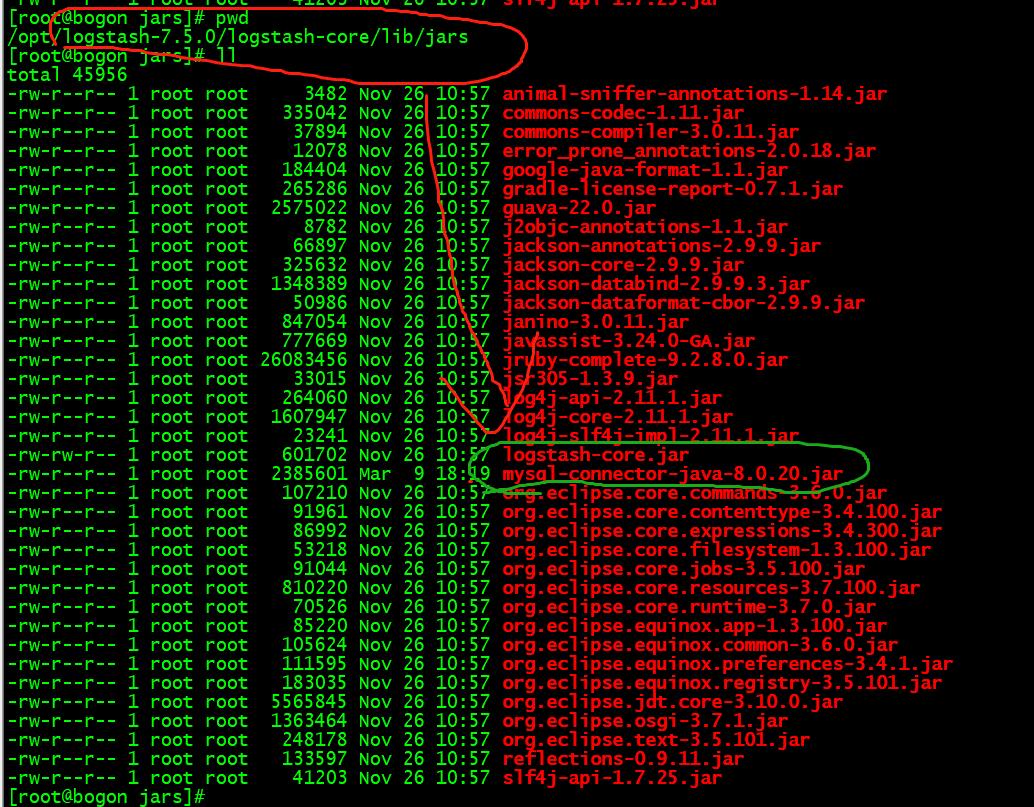
1.下载连接mysql的驱动包,放到指定目录下
在地址https://dev.mysql.com/downloads/connector/j/下载最新的Connector。下载完这个Connector后,把这个connector存入到Logstash安装目录下的如下子目录中:
logstash-core/lib/jars/
conf文件内容如下:
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.0.145:3306/db_example?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC"
jdbc_user => "root"
jdbc_password => "root"
jdbc_validate_connection => true
jdbc_driver_library => ""
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
parameters => { "Product_id" => "Product1" }
statement => "SELECT * FROM salesjan2009 WHERE Product = :Product_id"
}
}
filter {
mutate {
rename => {
"longitude" => "[location][lon]"
"latitude" => "[location][lat]"
}
}
}
output {
stdout {
}
elasticsearch {
hosts => ["192.168.75.21:9200"]
index => "sales" # 指定索引名
document_type => "_doc"
user => "elastic"
password => "GmSjOkL8Pz8IwKJfWgLT"
}
}
说明:
1.jdbc_connection_string => "jdbc:mysql://192.168.0.145:3306/db_example?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC"
连接的数据库地址,端口号,数据库名,字符编码,时区等,db_example为数据库名
2.
jdbc_user => "root"
jdbc_password => "root"
连接数据库使用的用户名和密码,根据自己的实际情况而定
3.jdbc_driver_library
驱动包路径,若是在logstash指定目录下则留空,若不是则需要指定绝对路径
4.jdbc_driver_class
最新使用的驱动包类
5.parameters
设置一个参数Product_id,其值是Product1
6.statement
sql语句,结合上面的理解,是查询salesjan2009数据表中条件Product的值是Product_id也即是Product1的数据
7.filter mutate
新增一个字段,重构经纬度参数值结构
运行Logstash来加载我们的MySQL里的数据到Elasticsearch中:
./bin/logstash --debug -f ./config/conf.d/sales.conf
可以在Kibana中查看到最新的导入到Elasticsearch中的数据:

注意数据总数,并不是数据表中的全部数据,而是根据查询条件获得的部分数据。