Mysql------InnoDB----使用B+树
Posted 梦想成为DALAO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql------InnoDB----使用B+树相关的知识,希望对你有一定的参考价值。
前言
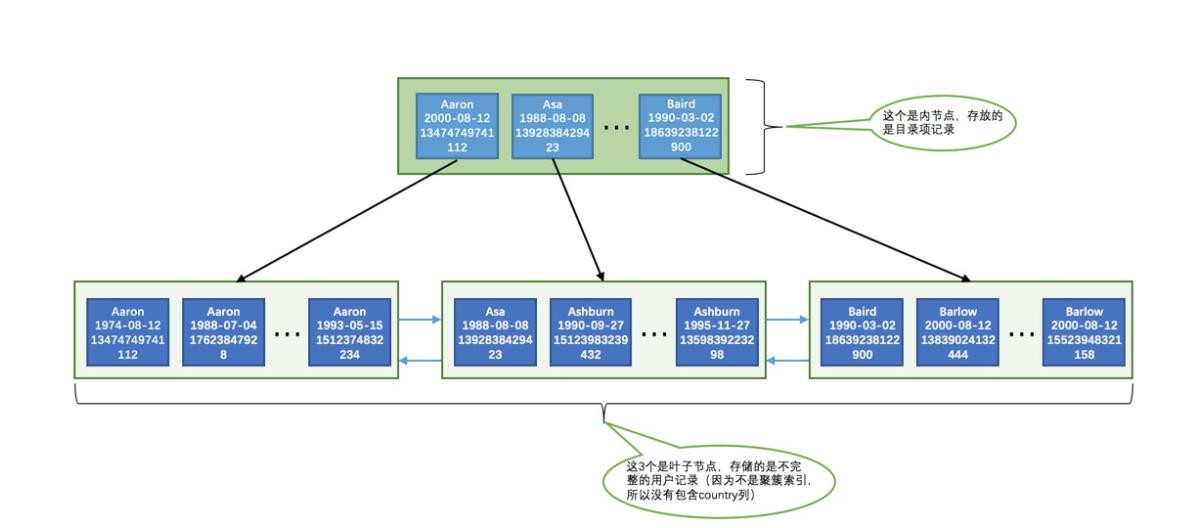
- 每个索引都对应一棵B+树,B+树分为好多层,最下边一层是叶子节点,其余的是内节点。所有用户记录都存储再B+树的叶子节点,所有目录项记录都存储在内节点。
- InnoDB存储引擎会自动为主键建立聚簇索引,聚簇索引的叶子节点包含完整的用户记录
- 我们可以根据自己的兴趣建立二级索引,二级索引的叶子节点包含的用户记录有索引列+主键组成,索引查找后需要回表查询。
- B+树每层节点都是按照索引列值从小到达的顺序排序而组成了双向链表,而且每个页内的记录都是按照索引列的值从小到大排列,形成单链表。如果是联合索引,就先比前面的索引列,顺序标胶
- 通过索引查找记录是从B+树的根节点开始,一层一层向下搜索。由于每个页面都按照索引列的值建立了Page Directory(页目录),所以在这些页面中的查找非常块。
索引的代价
- 空间上代价:浪费空间
- 时间上代价:因为每次增删改记录,都需要改B+树索引
B+树索引使用的条件
例子:
create table person_info( id int not null auto_increment, name varchar(100) not null, birthday date not null, phone_number char(11)not null, country varchar(100) not null, primary key(id), key idx_name_birthday_phone_number (name, birthday, phone_number) );
- 先按照name列的值进行排序
- 如果name列的值相同,则按照birthday列的值进行排序
- 如果birthday列的值也相同,则按照phone_number的值进行排序
全值匹配
如果不是按照B+树的排列顺序,是无法用到索引的;因为索引是按照那个顺序进行排列的。
匹配左边的列
反正你就从name----birthday-----phone_number进行查找就肯定能用到索引,如果你直接跳过name,去查找birthday,那肯定是不行的。
匹配列前缀
SELECT * FROM person_info WHERE name LIKE \'As%\';
这个肯定是可以的,因为字符串排序,就是从第一个字母开始排序的。
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SELECT * FROM person_info WHERE name LIKE \'%As%\';
这个肯定是不可以的
匹配范围值
SELECT * FROM person_info WHERE name > \'Asa\' AND name < \'Barlow\';
这个肯定是可以用到索引的。
-------------------------------------------------------------------------------------------------------------------------------
SELECT * FROM person_info WHERE name > \'Asa\' AND name < \'Barlow\' AND birthday > \'1980-01-01\';
这个只能用到name索引,而无法用到birthday索引;因为只有在name相同时,才能使用到birthday索引
上sql语句的查询方式是:
- 通过条件name>\'Asa\' and name < \'Barlow\'来对name进行范围,用到了索引
- 然后多name值不同的记录通过birthday > ‘1980.。。’来过滤。
精确匹配某一列并范围匹配另外一列
SELECT * FROM person_info WHERE name = \'Ashburn\' AND birthday > \'1980-01-01\' AND birthday < \'2000-12-31\' AND phone_number > \'15100000000\';
-
name = \'Ashburn\' ,对name列进行精确查找,是可以用到B+树的
- birthday > \'1980-01-01\' AND birthday < \'2000-12-31\', 由于name列是精确查找, 所以通过name = \'Ashburn\'条件查找后得到的结果的name值都是相同的,索引后续的birthday的范围查找也是可以用到索引的
- 而phone_number由于前面查找到的值,在birthday上的值不一样,所以这个条件不会用到B+树索引
索引用于排序
SELECT * FROM person_info ORDER BY name, birthday, phone_number LIMIT 10;
排序时需要注意的事项
ASC、 DESC混用
order by 子句后面如果不加ASC或者DESC默认是按照升序
SELECT * FROM person_info ORDER BY name, birthday DESC LIMIT 10;
上述语句:就会很烦,先从name值最小的中找,然后不够十条,再从name值第二小的中找,然后往复这个过程。其实我也觉得没那么麻烦
where子句中出现非排序使用到的索引列
SELECT * FROM person_info WHERE country = \'China\' ORDER BY name LIMIT 10;
排序列包含非同一个索引的列
有时候,用来排序的多个列不是一个索引里面的,这种情况也不能使用到索引进行排序
废话!!
排序列使用了复杂的表达式
SELECT * FROM person_info ORDER BY UPPER(name) LIMIT 10;
索引用户分组
SELECT name, birthday, phone_number, COUNT(*) FROM person_info GROUP BY name, birthday, phone_number
- 先把记录按照name值进行分组,所有name值相同的记录划为一组
- 将每个name值相同的birthday进行分组
- 最后用phone_number进行分组
肯定可以,分组列的顺序和索引列的顺序一致
回表的代价
耗时就完事了
会使用到两个索引
访问二级索引使用顺序I/O,访问聚簇索引使用随机I/O
覆盖索引
说白了,就是查找索引列,不查别的,就不用回表了。
SELECT name, birthday, phone_number FROM person_info WHERE name > \'Asa\' AND name < \'Barlow\'
如何挑选索引
只为用于搜索、排序或者分组的列创建索引
考虑列的基数
基数就是:一个集合中,不同的个数;假如(1,1,2,2,2,1)基数为2。
列的技术越大,该列的值越分散,列的基数越小,该列中的值越集中。
最好是将基数大的列建立索引,这样索引涵盖面会很大,可以精确的查找到很多的数据。
索引列的类型尽量小:内存啊,大哥;查询也快
索引字符串的前缀:因为有很多时候,我们并比不了很长的字符串
但是这样的话,就不能对列进行排序了。
让索引列在表达式中单独出现
WHERE my_col * 2 < 4 WHERE my_col < 4/2
上述代码中,第二行比第一行快很多
主键插入顺序
让主键具有AUTO_INCREMENT, 让存储引擎自己为表生成主键, 而不是我们手动插入
瞎JB乱插,每次都会修改B+树的。

别建立冗余和重复的索引
总之就是没事别瞎JB建立索引!!!!!!!
以上是关于Mysql------InnoDB----使用B+树的主要内容,如果未能解决你的问题,请参考以下文章