MongoDB安装和入门
Posted 路仁甲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB安装和入门相关的知识,希望对你有一定的参考价值。
MongoDB是一个文档数据库,提供好的性能,领先的非关系型数据库。采用BSON存储文档数据。2007年10月,MongoDB由
优势:
-
面向文档的存储:以 JSON 格式的文档保存数据。
-
任何属性都可以建立索引。
-
复制以及高可扩展性。
-
自动分片。
-
丰富的查询功能。
-
快速的即时更新。
-
来自 MongoDB 的专业支持。
选择版本、系统环境、包 。以下将以tgz包 为例
上传完成后解压
tar zxvf mongodb-linux-x86_64-rhel70-4.2.8.tgz
移动到/usr/local/mongodb目录(非必须)
mv mongodb-linux-x86_64-rhel70-4.2.8/ /usr/local/mongodb
创建专门的负责的用户并赋予权限(非必须)
cd /usr/local/mongodb groupadd mongodb useradd -s /sbin/nologin -g mongodb -M mongodb mkdir data log run chown -R mongodb:mongodb data log run
在/usr/local/mongodb 里面创建一个配置文件 mongodb.conf
vim mongodb.conf 并写入下面的信息:
bind_ip=0.0.0.0 port=27017 dbpath=/usr/local/mongodb/data/ logpath=/usr/local/mongodb/log/mongodb.log pidfilepath =/usr/local/mongodb/run/mongodb.pid logappend=true fork=true maxConns=500 noauth = true # 配置解释: # fork=true 运行在后台 # logappend=true 如果为 true,当 mongod/mongos 重启后,将在现有日志的尾部继续添加日志。否则,将会备份当前日志文件,然后创建一个新的日志文件;默认为 false。 # noauth = true 不需要验证用户密码 # maxConns=500 最大同时连接数 默认2000
以上是MongoDB的安装与启动的准备工作,可直接启动 启动命令:
/usr/local/mongodb/bin/mongod -f /usr/local/mongodb/mongodb.conf
配置环境变量
vim /etc/profile
在/etc/profile文件末尾添加一行:
export PATH=/usr/local/mongodb/bin:$PATH
让其生效:
source /etc/profile
查看当前mongodb的版本:
mongod --version

mongo
查看MongoDB自带的原始数据库
show dbs


local:这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config:当mongo用于分片设置时,config数据库在内部使用。用于保存分片的相关信息
use test


删除数据库:db.dropDatabase()
db.dropDatabase()

用于删除已经持久化的数据库,刚创建在内存中的数据库删除无效
相当于恢复到刚创建test数据库且并没有持久化到磁盘的状态
创建一个集合:db.createCollection("集合名称")
db.createCollection("西游记")
查看所有的集合show tables 或者 show collections
show tables
show collections

删除集合:db.集合名称.drop()
db.西游记.drop()

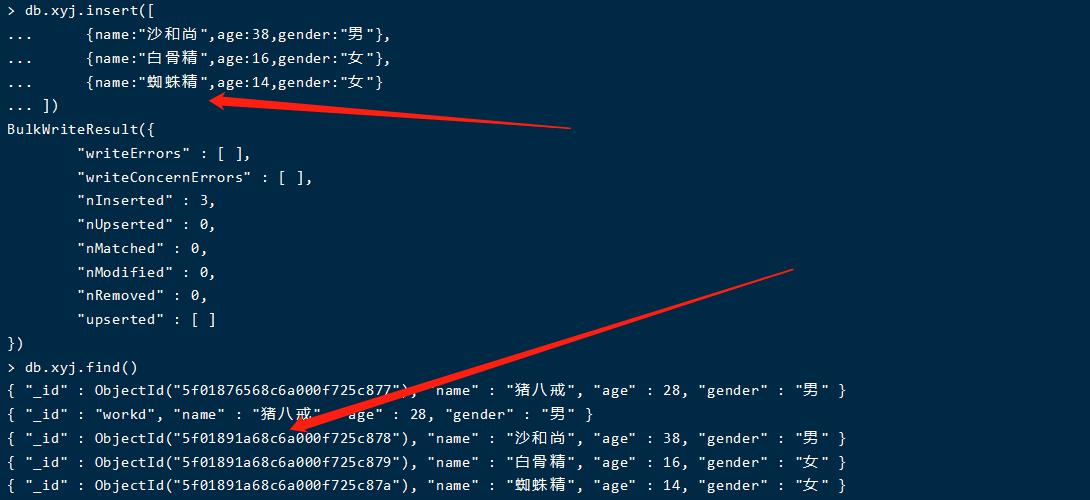
db.xyj.insert({name:"猪八戒",age:28,gender:"男"})
这里会自动创建xyj这个集合
查询数据
db.xyj.find()

可以看到,我们没有指定id,MongoDB自动给我们生成了一条id,我们也可以指定id,如下
添加一条指定id的数据
db.xyj.insertOne({_id:"workd",name:"猪八戒",age:28,gender:"男"})

当我们向集合中插入文档时,如果没有给文档指定 _id属性,则数据库会自动为文档添加 _id该属性用来作为文档的唯一标识 _id
我们可以自己指定,如果我们指定了数据库就不会在添加了,如果自己指定 _id 也必须确保它的唯一性
批量添加数据
db.xyj.insert([ ... {name:"沙和尚",age:38,gender:"男"}, ... {name:"白骨精",age:16,gender:"女"}, ... {name:"蜘蛛精",age:14,gender:"女"} ... ])
或者以下命令也是一样的效果
db.xyj.insertMany([ {name:"沙和尚",age:38,gender:"男"}, {name:"白骨精",age:16,gender:"女"}, {name:"蜘蛛精",age:14,gender:"女"} ])

总结:
db.collection.insertOne() 插入一个文档对象
db.collection.insertMany() 插入多个文档对象
额外小知识
try{ db.xyj.insert([ {name:"沙和尚",age:38,gender:"男"}, {name:"白骨精",age:16,gender:"女"}, {name:"蜘蛛精",age:14,gender:"女"} ]); }catch(e){ print(e) }
可以知道那条插入失败
全量修改操作
db.xyj.update({_id: ObjectId("5f0189a368c6a000f725c87b")},{age:NumberInt(30)})
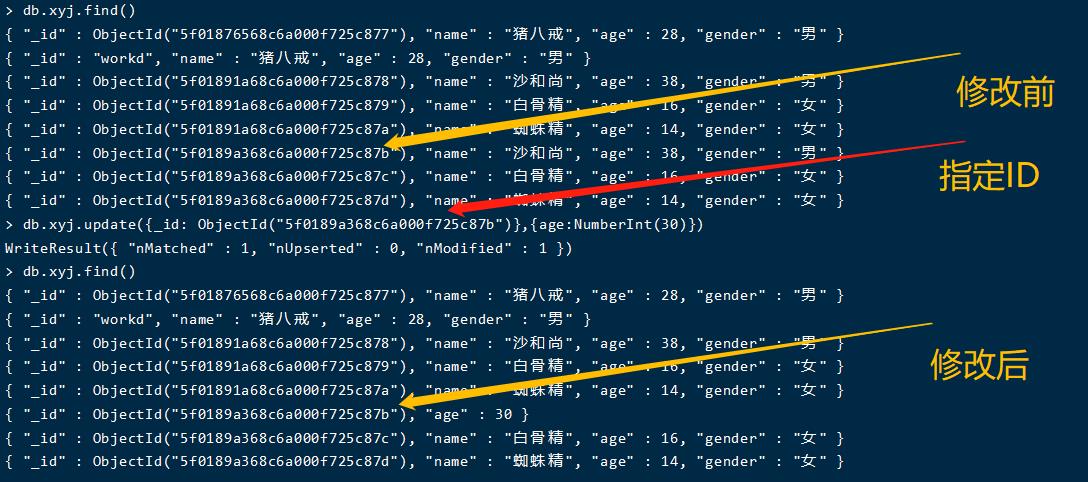
执行效果:这条数据只有age一个字段了
局部修改操作
db.xyj.update({_id:ObjectId("5f0189a368c6a000f725c87c")},{$set:{age:NumberInt(30)}})
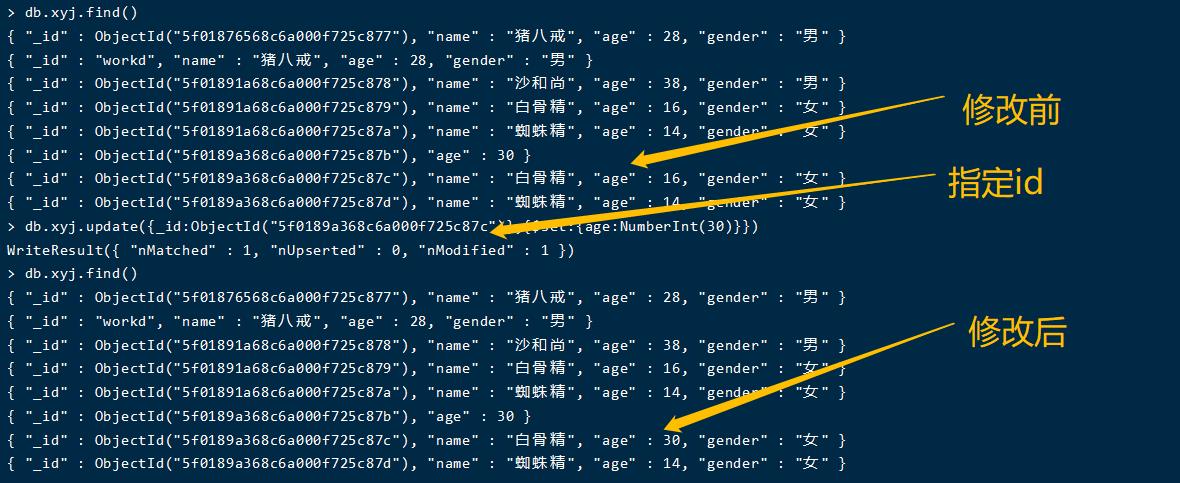
执行效果:只会修改这条数据的某个字段
批量修改
db.xyj.update({name:"蜘蛛精"},{$set:{age:NumberInt(100)}},{multi:true})

注意:在修改条数据时,必须要加上第三个参数{multi:true},否则只会修改一条数据
字段增加操作
db.xyj.update({_id:"workd"},{$inc:{age:NumberInt(1)}})

删除文档
db.xyj.remove({_id:"workd"})
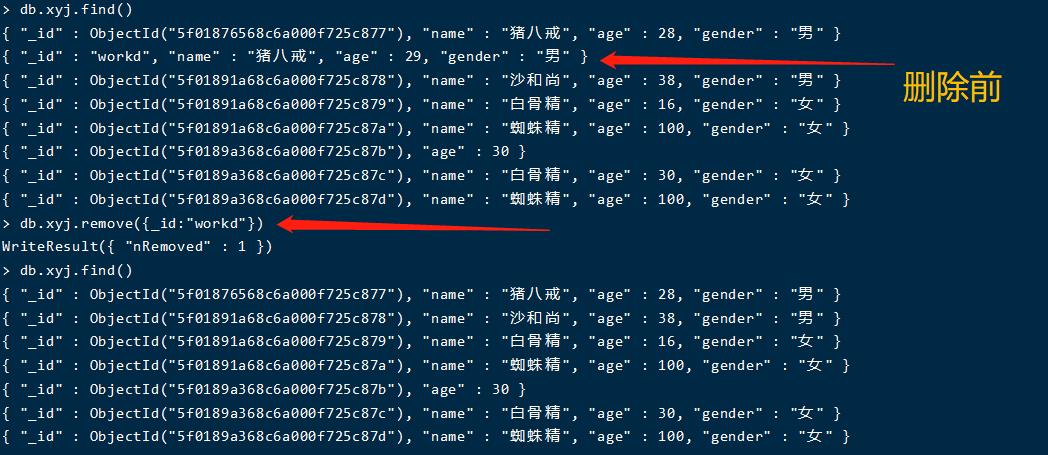
删除文档字段
db.xyj.update({"_id": ObjectId("5f0189a368c6a000f725c87d")}, {"$unset": {"name":1}})
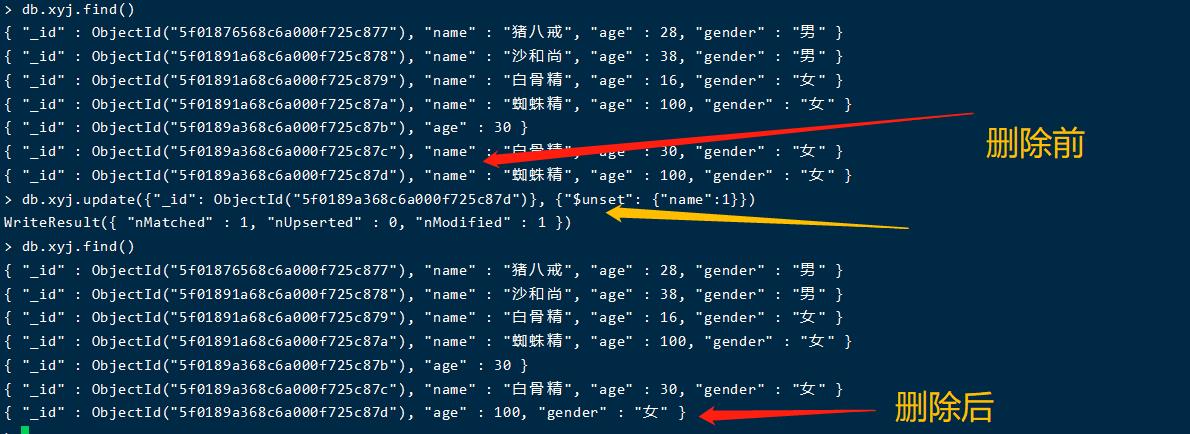
删除所有
db.xyj.remove({})

数组操作
插入测试数据
db.xyj.insertMany([ {name:"沙和尚",age:38,gender:"男",hobby:["打篮球","吃喝"]}, {name:"白骨精",age:16,gender:"女",hobby:["吃喝"]}, {name:"蜘蛛精",age:14,gender:"女",hobby:["跑步","打乒乓球"]}, {name:"唐生",age:25,gender:"男",hobby:["坐禅","吃喝"]} ]);
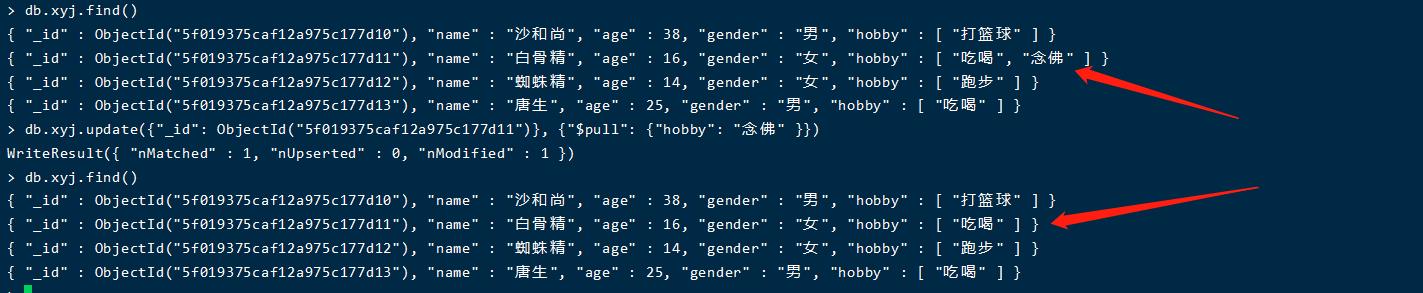
添加数组内容($push)
db.xyj.update({"name": "白骨精"}, {"$push": {"hobby": "念佛"}})
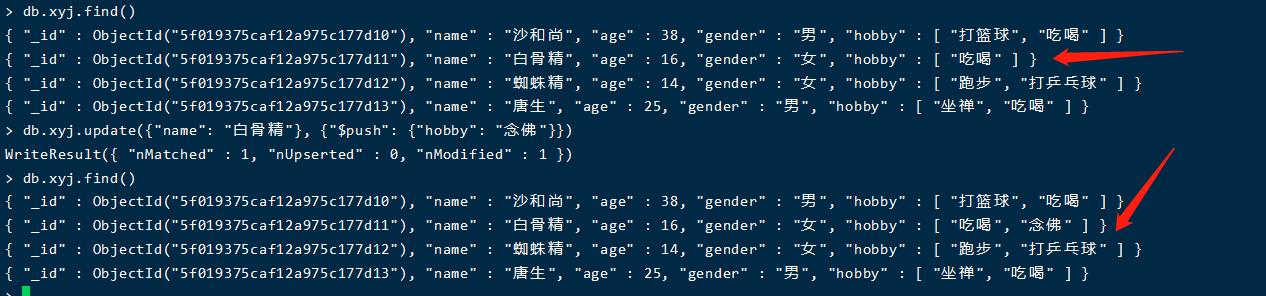
db.xyj.update({"_id": ObjectId("5f019375caf12a975c177d10")}, {"$pop": {"hobby": 1}})

删除第一个元素
db.xyj.update({"_id": ObjectId("5f019375caf12a975c177d13")}, {"$pop": {"hobby": -1}})
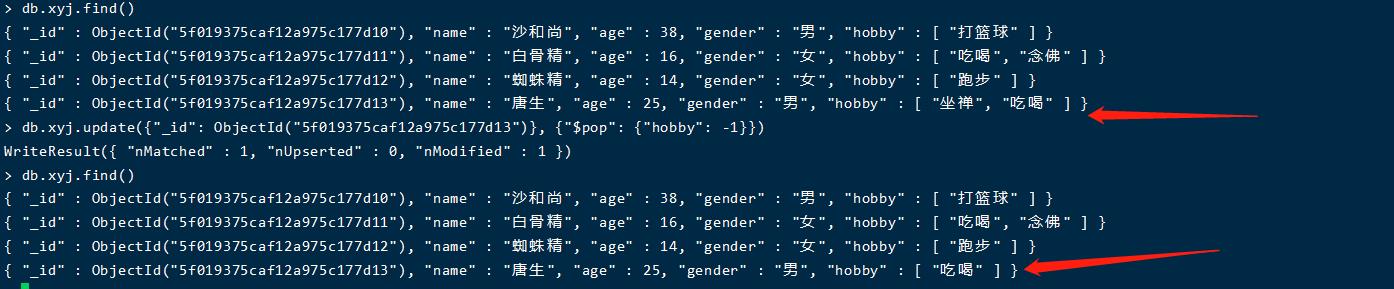
db.xyj.update({"_id": ObjectId("5f019375caf12a975c177d11")}, {"$pull": {"hobby": "念佛" }})
添加一条测试数据
db.xyj.insert({name:"猪八戒",age:28,gender:"男",address: [{place: "nanji", tel: 123}, {place: "dongbei", tel: 321}]});
更新嵌套数组的值($set)
db.xyj.update({"_id": ObjectId("5f019881caf12a975c177d14")}, {"$set": {"address.0.tel": 213}})

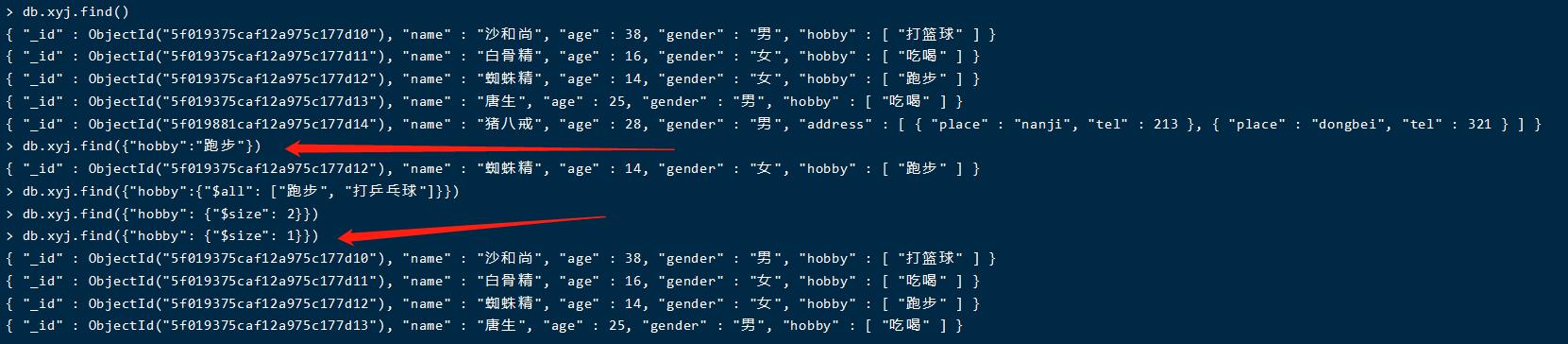
数组查询:
db.xyj.find({"hobby":"跑步"})
多个元素的查询
db.xyj.find({"hobby":{"$all": ["跑步", "打乒乓球"]}})
只有hobby数组同时存在跑步和打乒乓球才会匹配
限制数组长度查询
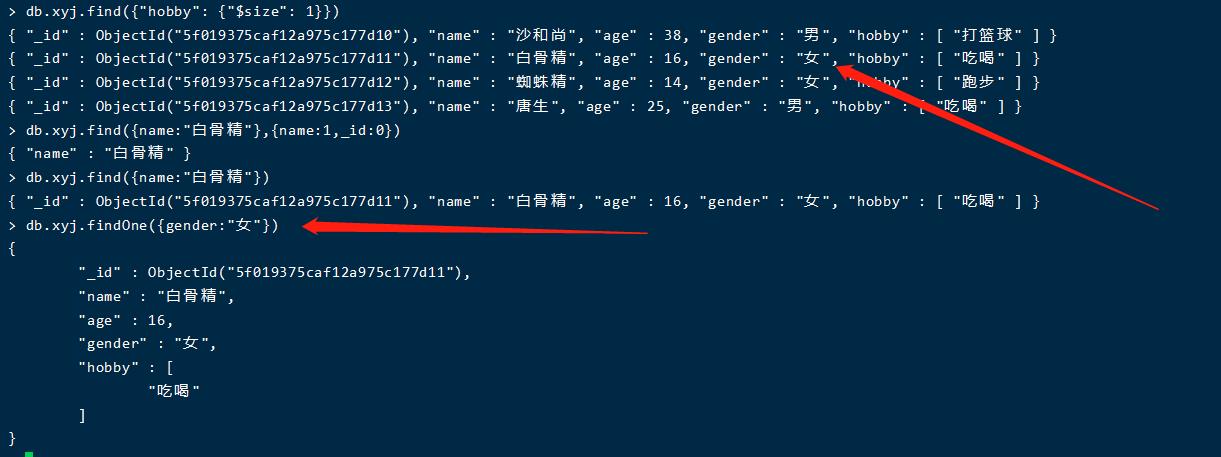
db.xyj.find({"hobby": {"$size": 1}})
只有数组的长度是1才会匹配
投影查询
db.xyj.find({name:"白骨精"},{name:1,_id:0})
1表示显示 0表示强制隐藏
相当于sql里面只查某些字段

按字段条件查询
db.xyj.find({name:"白骨精"})

按字段条件查询并只返回一条
db.xyj.findOne({gender:"女"})
其他api就不都演示了
组合查询:
语法:db.xyj.find($and:[{},{},{}]) //查询年级大于20小于50的 db.xyj.find({$and:[{age:{$gt:NumberInt(20)}},{age:{$lt:NumberInt(50)}}]}) //查询名字里有”精“的或者年纪大于30的 db.xyj.find({$or:[{age:{$gt:NumberInt(30)}},{name:/精/}]})
比较查询:
db.xyj.find({age:{$gt:NumberInt(20)}}) //查询年级大于20岁的
$gt--》大于 $lt--》小于 $gte--》大于等于 $lte--》小于等于 $ne---》不等于(不等于不一定要用于数字)
包含查询:
db.xyj.find({age:{$in:[28,38]}})
不包含:
db.xyj.find({age:{$nin:[28,38]}})
Like:
db.xyj.find({"name": /精/})
统计查询:
db.xyj.count()或者db.xyj.count({字段:条件})
取模:
db.xyj.find({"age": {$mod: [5, 1]}})
比如我们要匹配 age % 5 == 1
是否存在($exists)
db.xyj.find({"love": {"$exists": true}}) // 如果存在字段love,就返回
db.xyj.find({"love": {"$exists": false}}) // 如果不存在字段love,就返回
分页查询
limit:显示几条记录
skip:跳过几条记录
第一次查询:db.xyj.find().limit(2)
第一次查询:db.xyj.find().limit(2).skip(2)
结合排序:db.xyj.find().limit(2).skip(2).sort({age:1}) // 1代表升序,-1代表降序
执行顺序: sort > skip > limit
| 描述 | 语法 | |
|---|---|---|
| $project | 数据投影,主要用于重命名,增加,删除字段 | db.article.aggregate({ $project : {title : 1 ,author : 1 ,}}); |
| $match | 过滤,筛选符合条件的文档,作为下一阶段输入 | db.articles.aggregate( [{ $match : { score : { $gt : 70, $lte : 90 } } },{ $group: { _id: null, count: { $sum: 1 } } }] ); |
| $limit | 限制经过管道的文档数量 | db.article.aggregate({ $limit : 5 }); |
| $skip | 待操作集合处理前跳过部分文档 | db.article.aggregate({ $skip : 5 }); |
| $unwind | 将数组拆分成独立字段 | db.article.aggregate({$project:{author:1,title:1,tags:1}},{$unwind:"$tags"}) |
| $group | 对数据进行分组 | db.article.aggregate({ $group : {_id : "$author",docsPerAuthor : { $sum : 1 },viewsPerAuthor : { $sum : "$pageViews" }}}); |
| $sort | 对文档按照指定字段排序 | db.users.aggregate( { $sort : { age : -1, posts: 1 } }); |
| $sample | 随机选择从其输入指定数量的文档。 | { $sample: { size: <positive integer> } } |
| $out | 必须为pipeline最后一个阶段管道,因为是将最后计算结果写入到指定的collection中 | |
| $indexStats | 返回数据集合的每个索引的使用情况 |
插入测试数据
document1=({name:\'dogOne\',age:1,tags:[\'animal\',\'dog\'],type:\'dog\',money:[{min:100},{norm:200},{big:300}]});
document2=({name:\'catOne\',age:3,tags:[\'animal\',\'cat\'],type:\'cat\',money:[{min:50},{norm:100},{big:200}]});
document3=({name:\'catTwo\',age:2,tags:[\'animal\',\'cat\'],type:\'cat\',money:[{min:20},{norm:50},{big:100}]});
document4=({name:\'dogTwo\',age:5,tags:[\'animal\',\'dog\'],type:\'dog\',money:[{min:300},{norm:500},{big:700}]});
document5=({name:\'appleOne\',age:0,tags:[\'fruit\',\'apple\'],type:\'apple\',money:[{min:10},{norm:12},{big:13}]});
document6=({name:\'appleTwo\',age:0,tags:[\'fruit\',\'apple\'],type:\'apple\',money:[{min:10},{norm:12},{big:13}]});
document7=({name:\'pineapple\',age:0,tags:[\'fruit\',\'pineapple\'],type:\'pineapple\',money:[{min:8},{norm:9},{big:10}]});
db.mycol.insert(document1)
db.mycol.insert(document2)
db.mycol.insert(document3)
db.mycol.insert(document4)
db.mycol.insert(document5)
db.mycol.insert(document6)
db.mycol.insert(document7)

假定我们想提取money中min为100的文档,并且只输出名称和money数组中的min那一项
db.mycol.aggregate( {$match:{\'money.min\':100}}, {$project:{_id:0,name:\'$name\',minprice:\'$money.min\'}} )

假定我们想提取money中min小于100的文档,并且限制3个文档,跳过一个文档再显示

通过type类型来对数据进行分类,并且同时统计他们的年龄age总和
db.mycol.aggregate( {$group:{_id:\'$type\',sumage:{$sum:\'$age\'}}} )
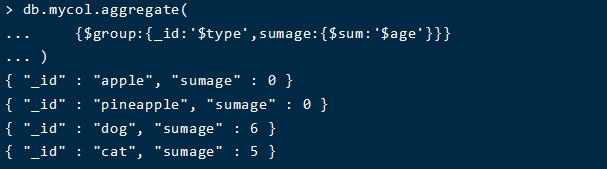
按照年龄对数据进行排序
db.mycol.aggregate( {$group:{_id:\'$type\',sumage:{$sum:\'$age\'}}}, {$sort:{sumage:1}} )

以上是关于MongoDB安装和入门的主要内容,如果未能解决你的问题,请参考以下文章