ElasticSearch Python Client ReadTimeout 解决办法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch Python Client ReadTimeout 解决办法相关的知识,希望对你有一定的参考价值。
参考技术A ElasticSearch Python Client API,Bulk操作时,当ElasticSearch服务端的性能不足时,Client可能会超时,打印类似异常:简单的解决方法是加入timeout和重试相关参数(参考: https://stackoverflow.com/questions/25908484/how-to-fix-read-timed-out-in-elasticsearch )
Increase the default timeout Globally when you create the ES client by passing the timeout parameter. Example in Python
Set the timeout per request made by the client. Taken from Elasticsearch Python docs below.
only wait for 1 second, regardless of the client's default
我设置timeout=100,max_retries=3,因为,当ElasticSearch在做大量查询的时候,会消耗掉所有的读IO,此时bluk数据,可能POST成功,但等待服务端返回确认结果timeout了,如果timeout时间设置太短,而max_retries设置太多,会导致数据重复插入max_retries次。
这里显示,默认max_retries为3,retry_on_timeout为False,retry_on_status为(502, 503, 504)。
可以看出,这里原来默认timeout只有10秒。
Elasticsearch:使用 Python elasticsearch-dsl-py 库对 Elasticsearch 进行查询
在我之前的几篇文章中:
我详细地描述了如何使用 elasticsearch-py 这个库来对 Elasticsearch 进行访问。 elasticsearch-py 库是一个官方发布的低级客户端库。它其实就是针对 Elasticsearch 的 REST API 接口进行了包装。
在今天的文章中,我将介绍如何使用 elasticsearch-dsl-py 这个高级库来对 Elasticsearch 进行访问。这个库是建立于 elasticsearch-py 之上的。它提供用于将文档作为 Python 对象处理的可选包装器。
有关更多关于 Elasticsearch 的客户端开发,可以参阅官方链接 https://www.elastic.co/guide/en/elasticsearch/client/index.html
在本次练习中,我将使用 Elastic Stack 7.14 来进行展示。有些版本的界面可能和这个有所不同。
安装
Elasticsearch
我们可以参阅文章 “如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch” 来安装 Elasticsearch。
Kibana
我们可以参阅文章 “Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana” 来安装 Kibana。
Python
我们需要安装 Python 的环境。同时为了能够访问 Elasticsearch,我们必须安装如下的库:
pip install elasticsearch
pip install elasticsearch-dsl为了能够使得我们很方便地展示,我们也安装 ipython。当然你也可以使用 Jupyter Notebook 来进行展示。你可以参考我之前的文章 “Elasticsearch:使用 Jupyter Notebook 创建 Python 应用导入 CSV 文件”。
我们使用如下的命令来安装 ipython:
pip install ipython准备数据
在本次练习中,我将使用 Kibana 自带的索引来进行练习。
这样我们就导入了索引 kibana_sample_data_logs。
我们们在 Kibana 的 Dev Tools 中可以使用如下的查询:
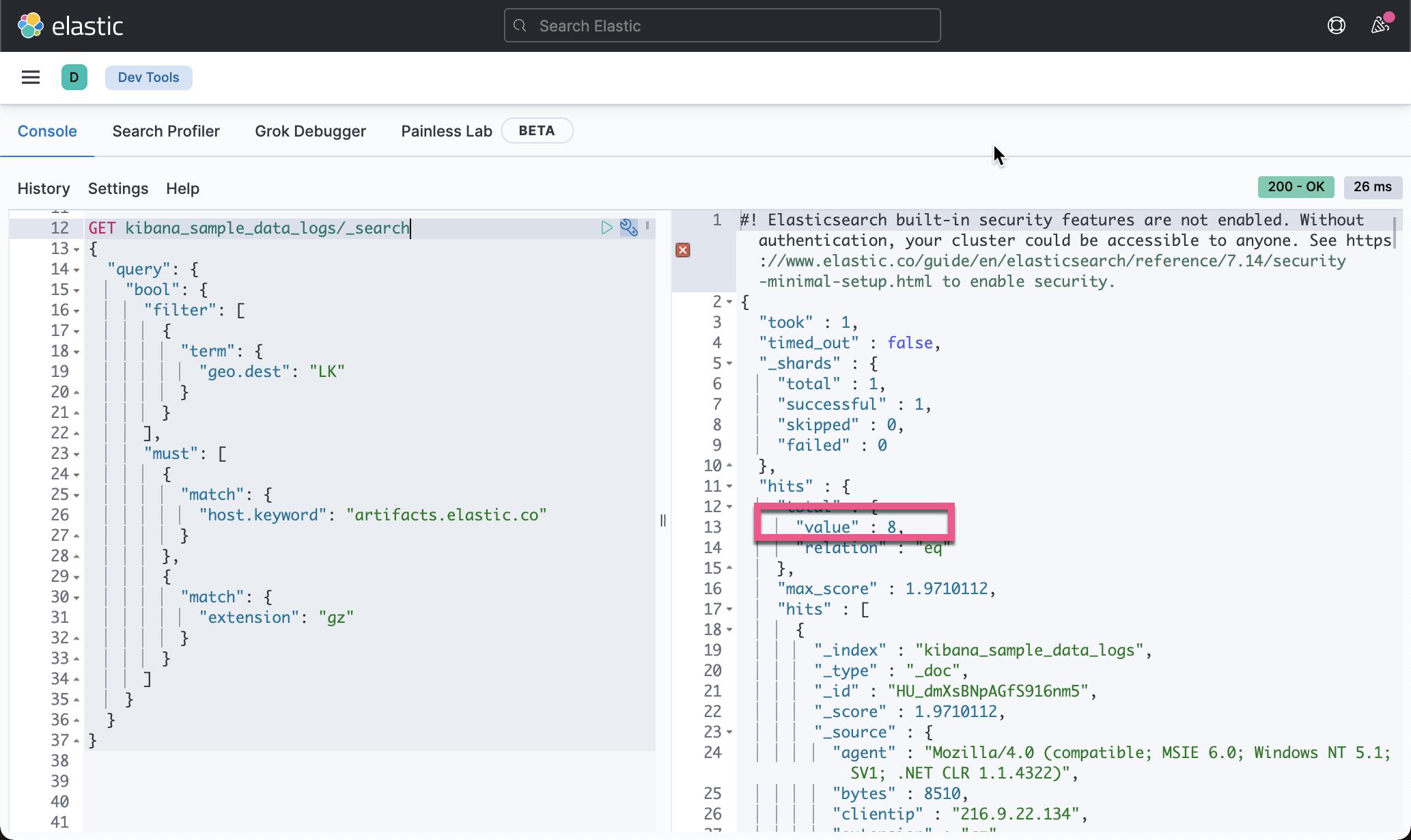
显然这是一个比较复杂的 compound DSL 查询。如果大家对这个查询还是不很熟悉的话,请参阅我之前的文章 “开始使用 Elasticsearch (2)”。在那里,有详细的关于 DSL 查询以及 compound query 的具体描述。
上面的查询结果将返回 8 个结果的查询:
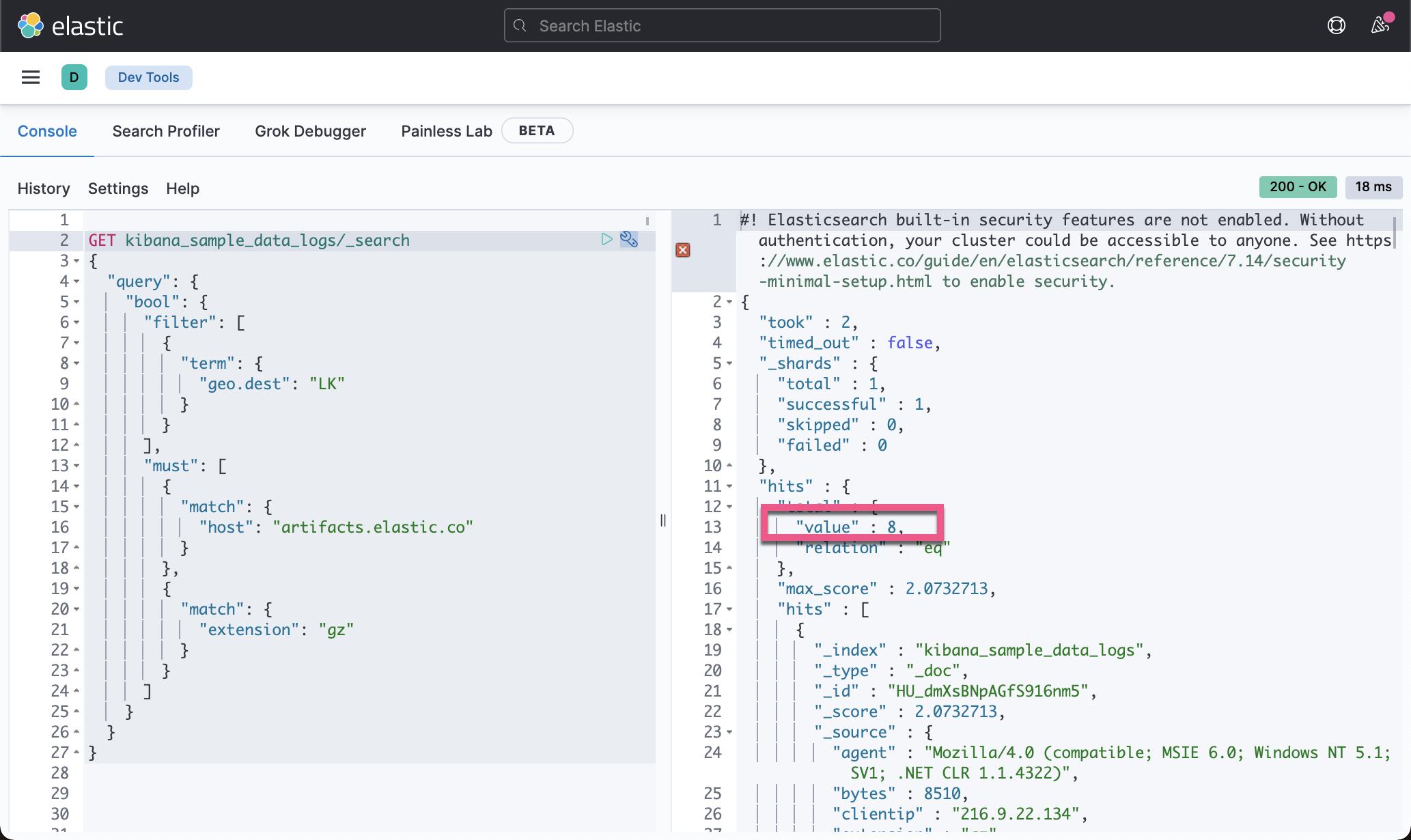
在接下来的介绍中,我们将展示如何使用 elastiicsearch-dsl 来实现上面的查询。
elaticsearch-dsl 实践
我们在 terminal 中打入如下的命令:
ipython
我们接着打入如下的句子:
from elasticsearch import Elasticsearch
es = Elasticsearch(hosts=['localhost:9200'])
es.info()我们可以看到:
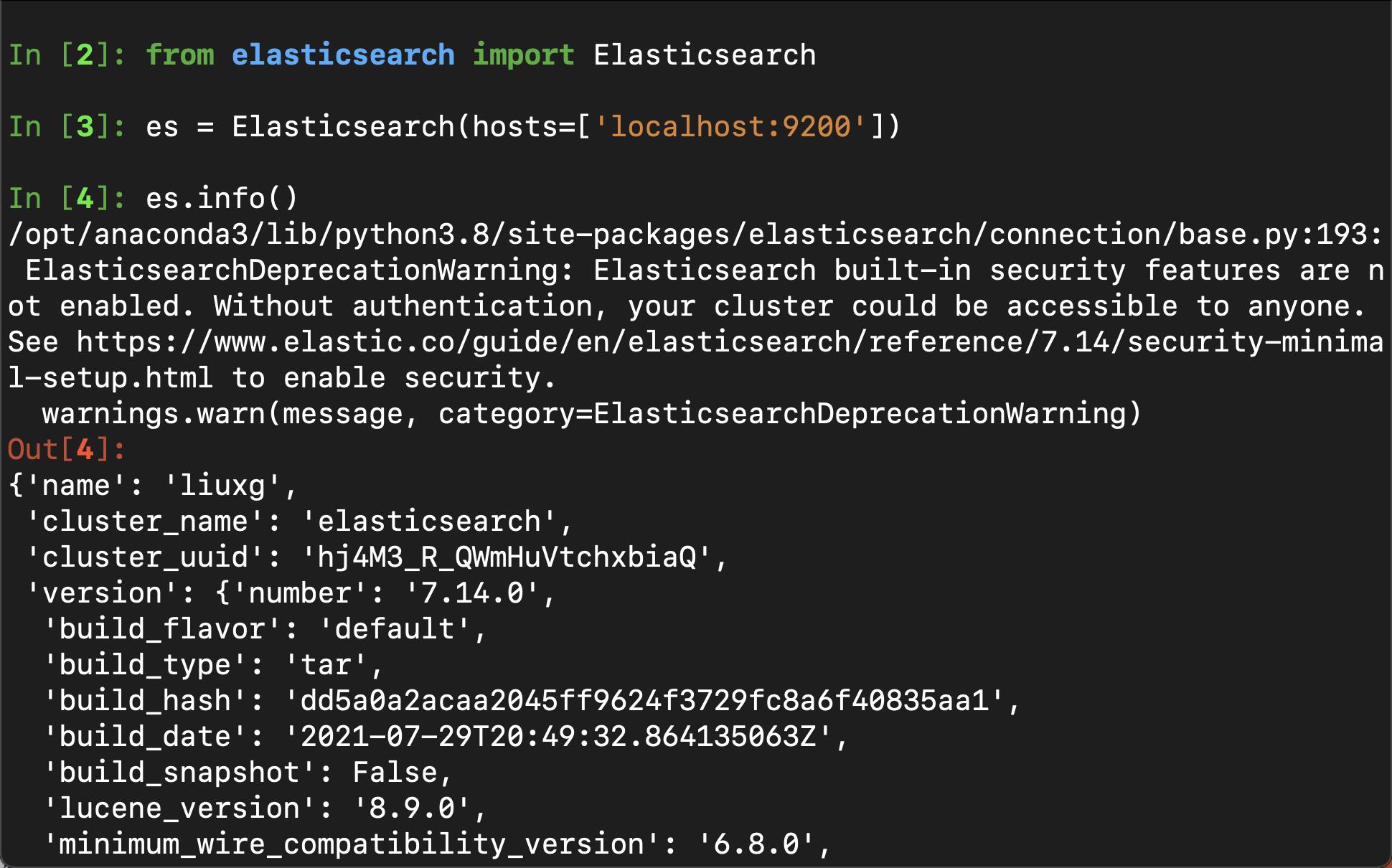
上面表明我们的连接到 Elasticsearch 是成功的。如果你的 Elasticsearch 是 HTTPS 的那么你需要使用如下的格式来进行连接:
from elasticsearch import Elasticsearch
es = Elasticsearch(
hosts=['YourElasticsearchServer:9200'],
http_auth=('YourUserName', 'YourPassword'),
scheme="https",
use_ssl=True,
verify_certs=False,
ssl_show_warn=False
)我们接下来 import elasticsearch-dsl 库:
from elasticsearch_dsl import Search
s = Search(index="kibana_sample_data_logs")
s = s.using(es)
我们接着打入如下的命令:
s.to_dict()上面的命令显示:

显然这个查询和我们在 Kibana 中如下的搜索是一样的:
GET kibana_sample_data_logs/_search
{
"query": {
"match": {
"extension": "gz"
}
}
}我们接下来添加另外一个 match query:
s = s.query("match", host__keyword="artifacts.elastic.co")
s.to_dict()请注意上面的 host__keyword。中间是两个 _。这是因为在 Python 中 . 是一个保留符号。它表示 host.keyword。经过上面的添加后,我们可以查看现在的 query:
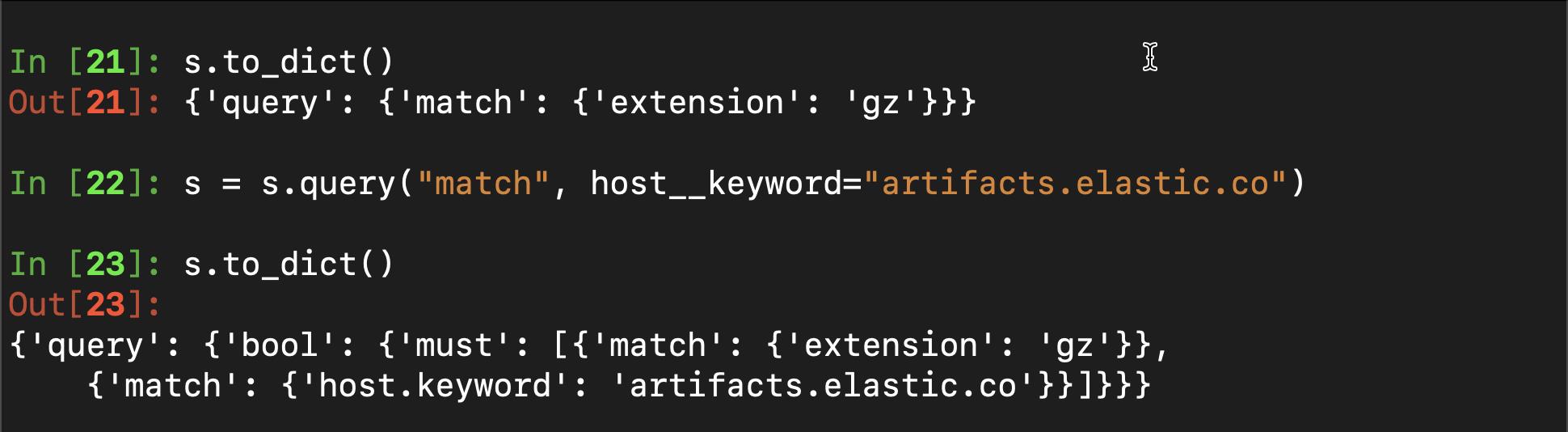
很显然这是一个 compound query。它和如下格式的查询是一样的:
GET kibana_sample_data_logs/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"host.keyword": "artifacts.elastic.co"
}
},
{
"match": {
"extension": "gz"
}
}
]
}
}
}我们接着添加一个 filter 的 clause:
s=s.filter("term", geo__dest="LK")
再次提醒请注意上面的 __ 符号。geo__dest 表示的是 geo.dest。
上面的 query 在 Kibana 中是这样的:
GET kibana_sample_data_logs/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"geo.dest": "LK"
}
}
],
"must": [
{
"match": {
"host.keyword": "artifacts.elastic.co"
}
},
{
"match": {
"extension": "gz"
}
}
]
}
}
}我们接下来添加 from + size 来选择我们想要的数据:
s=s[2:4]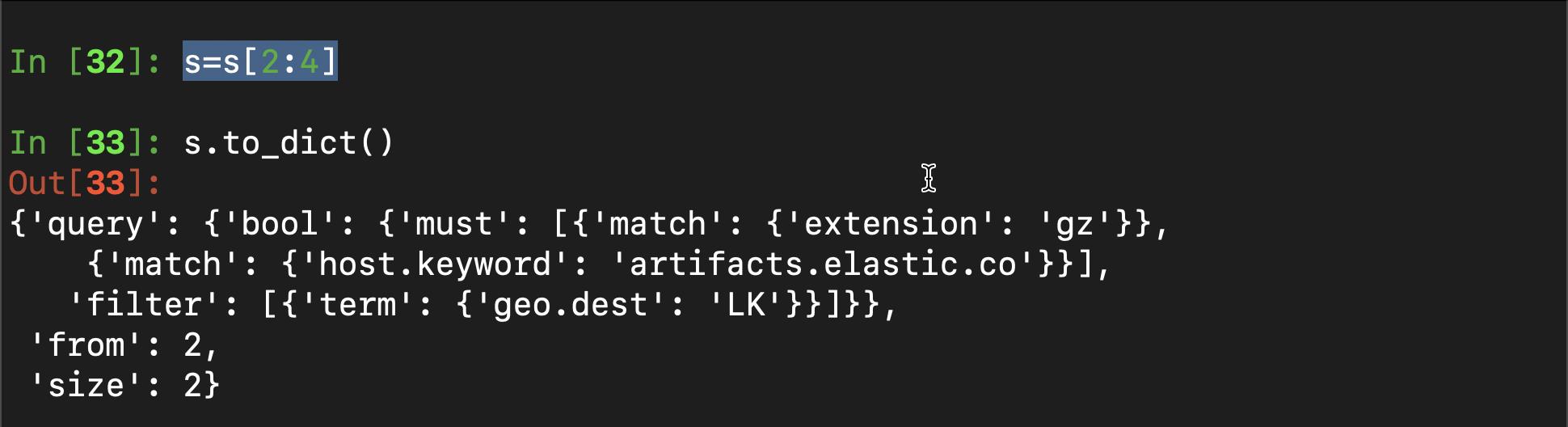
这个类似如下的查询:
GET kibana_sample_data_logs/_search
{
"from": 2,
"size": 2,
"query": {
"bool": {
"filter": [
{
"term": {
"geo.dest": "LK"
}
}
],
"must": [
{
"match": {
"host.keyword": "artifacts.elastic.co"
}
},
{
"match": {
"extension": "gz"
}
}
]
}
}
}最后,我们可以甚至添加 aggregation:
s.aggs.bucket("source_country","terms",field="geo__src")在上面,我们针对 geo.src 做一个 terms 的 bucket 聚合:

上面的查询就是如下的查询:
GET kibana_sample_data_logs/_search
{
"from": 2,
"size": 2,
"query": {
"bool": {
"filter": [
{
"term": {
"geo.dest": "LK"
}
}
],
"must": [
{
"match": {
"host.keyword": "artifacts.elastic.co"
}
},
{
"match": {
"extension": "gz"
}
}
]
}
},
"aggs": {
"source_country": {
"terms": {
"field": "geo.src"
}
}
}
}我们可以使用如下的方法来打印查询的结果:
for hit in s:
print (hit.clientip)在上面,我们打印出来 clientip 的地址:
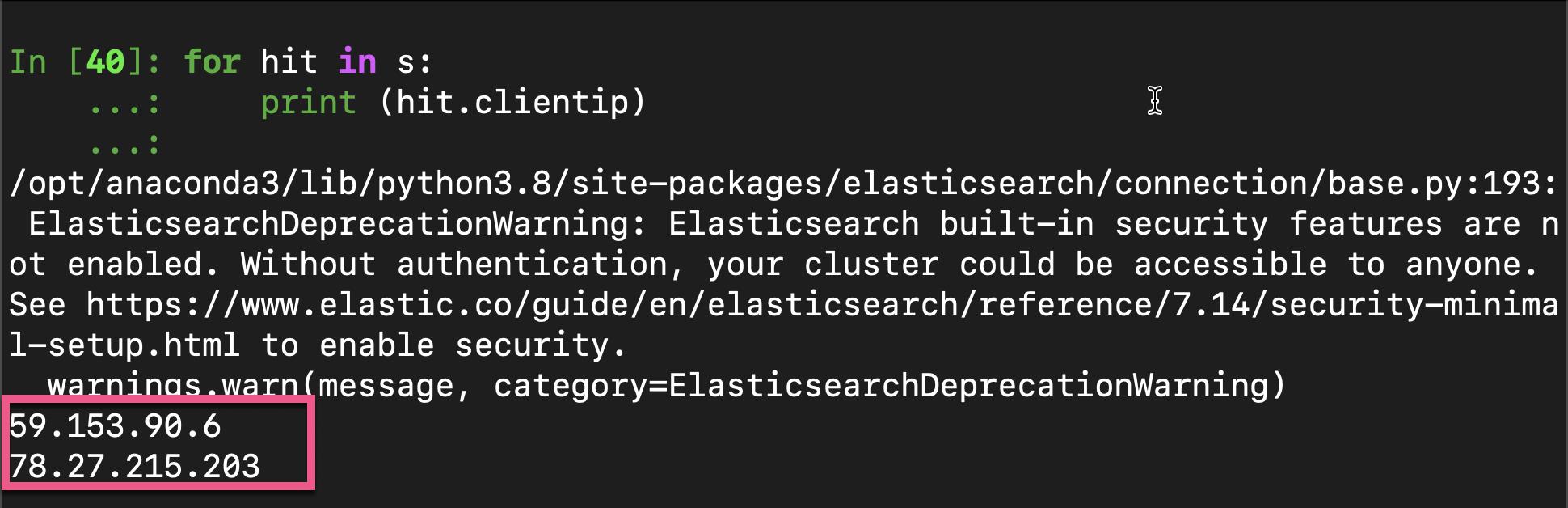
好了,今天的展示就到这里。在某种程度上,elasticsearch-dsl 库给我们开发者带来更多的方便及便捷。
更多关于 elasticsearch-dsl 的资料,请参考官方文档:https://elasticsearch-dsl.readthedocs.io/en/latest/ 及源码 https://github.com/elastic/elasticsearch-dsl-py
以上是关于ElasticSearch Python Client ReadTimeout 解决办法的主要内容,如果未能解决你的问题,请参考以下文章