
简介
什么是MongoDB?
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统;
在高负载的情况下,添加更多的节点,可以保证服务器性能;
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案;
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。
MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组;
主要特点
MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易,模式灵活,读写速度快;
你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序;
你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性; 如果负载的增加(需要更多的存储空间和更强的处理能力),它可以分布在计算机网络中的其他节点上这就是所谓的分片 水平扩展;
Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组; 地理位置索引;
MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段;
Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作;
Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理;
Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作;
GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件;
MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可;
MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言;
MongoDB安装简单,高可用;
优点
高可扩展性,架构灵活,水平扩展;
分布式计算,模式灵活,读写速度快(同样压力下Mongo比Mysql快成百上千倍);
没有复杂关系;
半结构化数据,直接将json数据存到库不做
类似mysql那样当中的转化(固定的行,列组织);
吐槽点
不支持事务,mysql优势就在支持事务;
硬件数量要求多
吃内存
CPU消耗大
函数不够丰富
丢失数据
BSON
二进制JSON,JSON文档的二进制编码存储格式
BSON有Json没有的Data和BinData
MongoDB中document以BSON形式存放
逻辑结构
| Mongodb逻辑结构 | mysql逻辑结构 |
|---|---|
| 库database | 库 |
| 集合(collection | 表 |
| 文档(document) | 数据行 |
原理
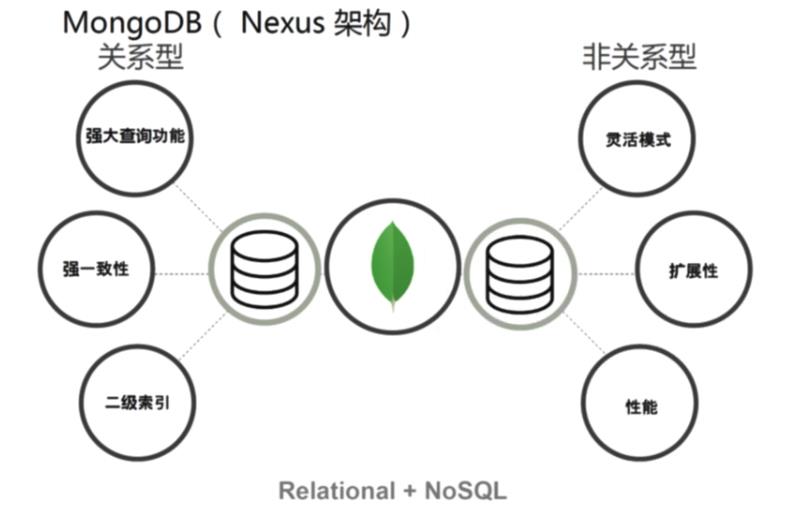
关系与非关系对比
部署MongoDB
准备环境
(1)redhat或cnetos6.2以上系统,mongo4必须centos7.2
(2)系统开发包完整
(3)ip地址和hosts文件解析正常
(4)iptables防火墙&SElinux关闭
(5)关闭大页内存机制
root用户下
在vi /etc/rc.local最后添加如下代码
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
或者临时关闭
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
为什么要关闭?
加速内存分配, mongo官方要求
Transparent Huge Pages (THP) 是一种Linux内存管理系统,可通过使用较大的内存页面来减少具有大量内存的计算机上的翻译后备缓冲区(TLB)查找的开销。 具有稀疏而不是连续的内存访问模式; ** 您应该在Linux机器上禁用THP,以确保MongoDB的最佳性能;**
安装Mongo
官网下载地址:https://www.mongodb.com/try/download
# 创建mongo用户
useradd mongod
echo 123 |passwd --stdin mongod
# 创建目录结构
mkdir -p /mongodb/{conf,log,data,bin}
# 解压软件到指定位置
tar xf mongodb-linux-x86_64-rhel70-3.4.24.tgz -C /mongodb/
cp -a /mongodb/mongodb-linux-x86_64-rhel70-3.4.24/bin/* /mongodb/bin/
# 修改目录权限
chown -R mongod:mongod /mongodb
# 设置用户环境变量
su - mongod
tail -2 .bash_profile
export PATH
export PATH=/mongodb/bin:$PATH
source .bash_profile
启动服务
你可以再命令行中执行mongo安装目录中的bin目录执行mongod命令来启动mongdb服务;
注意:如果你的数据库目录不是/data/db,可以通过 --dbpath 来指定;
mongod --dbpath=/mongodb/data --logpath=/mongodb/log/mongodb.log --port=27017 --logappend --fork
// 有警告就处理下
cat >> /etc/security/limits.conf <<EOF
* soft nproc 65530
* hard nproc 65530
* soft nofile 65530
* hard nofile 65530
EOF
ulimit -n 65535
ulimit -u 20480
// 链接mongo
mongo // 默认连接本机test数据库
配置文件启动mongo
vim /mongodb/conf/mongo.conf
logpath=/mongodb/log/mongodb.log
dbpath=/mongodb/data
port=27017
logappend=true
fork=true
Yaml模式启动
--系统日志有关
systemLog:
destination: file
path: "/mongodb/log/mongodb.log" --日志位置
logAppend: true --日志以追加模式记录
--数据存储有关
storage:
journal:
enabled: true
dbPath: "/mongodb/data" --数据路径的位置
-- 进程控制
processManagement:
fork: true --后台守护进程
pidFilePath: <string> --pid文件的位置,一般不用配置,可以去掉这行,自动生成到data中
--网络配置有关
net:
bindIp: <ip> -- 监听地址,如果不配置这行是监听在0.0.0.0
port: <port> -- 端口号,默认不配置端口号,是27017
-- 安全验证有关配置
security:
authorization: enabled --是否打开用户名密码验证
------------------以下是复制集与分片集群有关----------------------
replication:
oplogSizeMB: <NUM>
replSetName: "<REPSETNAME>"
secondaryIndexPrefetch: "all"
sharding:
clusterRole: <string>
archiveMovedChunks: <boolean>
---for mongos only
replication:
localPingThresholdMs: <int>
sharding:
configDB: <string>
---
yaml example
cat > /mongodb/conf/mongo.conf <<EOF
systemLog:
destination: file
path: "/mongodb/log/mongodb.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "/mongodb/data/"
processManagement:
fork: true
net:
port: 27017
bindIp: 192.168.0.4,127.0.0.1
EOF
命令参数详解
--logpath # 日志文件路径
--master # 指定为主机器
--slave # 指定为从机器
--source # 指定主机器的IP地址
--pologSize # 指定日志文件大小不超过64M.因为resync是非常操作量大且耗时,最好通过设置一个足够大的oplogSize来避免resync(默认的 oplog大小是空闲磁盘大小的5%)。
--logappend # 日志文件末尾添加
--port # 启用端口号
--fork # 在后台运行
--only # 指定只复制哪一个数据库
--slavedelay # 指从复制检测的时间间隔
--auth # 是否需要验证权限登录(用户名和密码)
-h [ --help ] # show this usage information
--version # show version information
-f [ --config ] arg # configuration file specifying additional options
--port arg # specify port number
--bind_ip arg # local ip address to bind listener - all local ips
bound by default
-v [ --verbose ] # be more verbose (include multiple times for more
verbosity e.g. -vvvvv)
--dbpath arg (=/data/db/) # directory for datafiles 指定数据存放目录
--quiet # quieter output 静默模式
--logpath arg # file to send all output to instead of stdout 指定日志存放目录
--logappend # appnd to logpath instead of over-writing 指定日志是以追加还是以覆盖的方式写入日志文件
--fork # fork server process 以创建子进程的方式运行
--cpu # periodically show cpu and iowait utilization 周期性的显示cpu和io的使用情况
--noauth # run without security 无认证模式运行
--auth # run with security 认证模式运行
--objcheck # inspect client data for validity on receipt 检查客户端输入数据的有效性检查
--quota # enable db quota management 开始数据库配额的管理
--quotaFiles arg # number of files allower per db, requires --quota 规定每个数据库允许的文件数
--appsrvpath arg # root directory for the babble app server
--nocursors # diagnostic/debugging option 调试诊断选项
--nohints # ignore query hints 忽略查询命中率
--nohttpinterface # disable http interface 关闭http接口,默认是28017
--noscripting # disable scripting engine 关闭脚本引擎
--noprealloc # disable data file preallocation 关闭数据库文件大小预分配
--smallfiles # use a smaller default file size 使用较小的默认文件大小
--nssize arg (=16) # .ns file size (in MB) for new databases 新数据库ns文件的默认大小
--diaglog arg # 0=off 1=W 2=R 3=both 7=W+some reads 提供的方式,是只读,只写,还是读写都行,还是主要写+部分的读模式
--sysinfo # print some diagnostic system information 打印系统诊断信息
--upgrade # upgrade db if needed 如果需要就更新数据库
--repair # run repair on all dbs 修复所有的数据库
--notablescan # do not allow table scans 不运行表扫描
--syncdelay arg (=60) # seconds between disk syncs (0 for never) 系统同步刷新磁盘的时间,默认是60s
Replication options:
--master # master mode 主复制模式
--slave # slave mode 从复制模式
--source arg # when slave: specify master as <server:port> 当为从时,指定主的地址和端口
--only arg # when slave: specify a single database to replicate 当为从时,指定需要从主复制的单一库
--pairwith arg # address of server to pair with
--arbiter arg # address of arbiter server 仲裁服务器,在主主中和pair中用到
--autoresync # automatically resync if slave data is stale 自动同步从的数据
--oplogSize arg # size limit (in MB) for op log 指定操作日志的大小
--opIdMem arg # size limit (in bytes) for in memory storage of op ids指定存储操作日志的内存大小
Sharding options:
--configsvr # declare this is a config db of a cluster 指定shard中的配置服务器
--shardsvr # declare this is a shard db of a cluster 指定shard服务器
其他配置参数含义
--quiet # 安静输出
--port arg # 指定服务端口号,默认端口27017
--bind_ip arg # 绑定服务IP,若绑定127.0.0.1,则只能本机访问,不指定默认本地所有IP
--logpath arg # 指定MongoDB日志文件,注意是指定文件不是目录
--logappend # 使用追加的方式写日志
--pidfilepath arg # PID File 的完整路径,如果没有设置,则没有PID文件
--keyFile arg # 集群的私钥的完整路径,只对于Replica Set 架构有效
--unixSocketPrefix arg # UNIX域套接字替代目录,(默认为 /tmp)
--fork # 以守护进程的方式运行MongoDB,创建服务器进程
--auth # 启用验证
--cpu # 定期显示CPU的CPU利用率和iowait
--dbpath arg # 指定数据库路径
--diaglog arg # diaglog选项 0=off 1=W 2=R 3=both 7=W+some reads
--directoryperdb # 设置每个数据库将被保存在一个单独的目录
--journal # 启用日志选项,MongoDB的数据操作将会写入到journal文件夹的文件里
--journalOptions arg # 启用日志诊断选项
--ipv6 # 启用IPv6选项
--jsonp # 允许JSONP形式通过HTTP访问(有安全影响)
--maxConns arg # 最大同时连接数 默认2000
--noauth # 不启用验证
--nohttpinterface # 关闭http接口,默认关闭27018端口访问
--noprealloc # 禁用数据文件预分配(往往影响性能)
--noscripting # 禁用脚本引擎
--notablescan # 不允许表扫描
--nounixsocket # 禁用Unix套接字监听
--nssize arg (=16) # 设置信数据库.ns文件大小(MB)
--objcheck # 在收到客户数据,检查的有效性,
--profile arg # 档案参数 0=off 1=slow, 2=all
--quota # 限制每个数据库的文件数,设置默认为8
--quotaFiles arg # number of files allower per db, requires --quota
--rest # 开启简单的rest API
--repair # 修复所有数据库run repair on all dbs
--repairpath arg # 修复库生成的文件的目录,默认为目录名称dbpath
--slowms arg (=100) # value of slow for profile and console log
--smallfiles # 使用较小的默认文件
--syncdelay arg (=60) # 数据写入磁盘的时间秒数(0=never,不推荐)
--sysinfo # 打印一些诊断系统信息
--upgrade # 如果需要升级数据库
#Replicaton 参数
--fastsync # 从一个dbpath里启用从库复制服务,该dbpath的数据库是主库的快照,可用于快速启用同步
--autoresync # 如果从库与主库同步数据差得多,自动重新同步,
--oplogSize arg # 设置oplog的大小(MB)
#主/从参数
--master # 主库模式
--slave # 从库模式
--source arg # 从库 端口号
--only arg # 指定单一的数据库复制
--slavedelay arg # 设置从库同步主库的延迟时间
#Replica set(副本集)选项:
--replSet arg # 设置副本集名称
#Sharding(分片)选项
--configsvr # 声明这是一个集群的config服务,默认端口27019,默认目录/data/configdb
--shardsvr # 声明这是一个集群的分片,默认端口27018
--noMoveParanoia # 关闭偏执为moveChunk数据保存
配置文件参数详解
# 简单示例
# 数据库数据存放目录
dbpath=/usr/local/mongodb/data
# 数据库日志存放目录
logpath=/usr/local/mongodb/logs/mongodb.log
# 以追加的方式记录日志
logappend = true
# 端口号 默认为27017
port=27017
# 以后台方式运行进程
fork=true
# 开启用户认证
auth=true
# 关闭http接口,默认关闭http端口访问
#nohttpinterface=true
# mongodb所绑定的ip地址
#bind_ip = 127.0.0.1
# 启用日志文件,默认启用
journal=true
# 这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为false
quiet=true
启动关闭
// 启动
$mongod -f /mongodb/conf/mongo.conf
// 关闭
mongod -f /mongodb/conf/mongo.conf --shutdown
加入systemd
cat > /etc/systemd/system/mongod.service <<EOF
[Unit]
Description=mongodb
After=network.target remote-fs.target nss-lookup.target
[Service]
User=mongod
Type=forking
ExecStart=/mongodb/bin/mongod --config /mongodb/conf/mongo.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/mongodb/bin/mongod --config /mongodb/conf/mongo.conf --shutdown
PrivateTmp=true
[Install]
WantedBy=multi-user.target
EOF
systemctl start mongod
systemctl stop mongod
systemctl restart mongod
MongoDB工具
监控
MongoDB提供了网络和系统监控工具Munin,它作为一个插件应用于MongoDB中;
Gangila是MongoDB高性能的系统监视的工具,它作为一个插件应用于MongoDB中;
基于图形界面的开源工具 Cacti, 用于查看CPU负载, 网络带宽利用率,它也提供了一个应用于监控 MongoDB 的插件;
GUI
# Fang of Mongo – 网页式,由Django和jQuery所构成。
# Futon4Mongo – 一个CouchDB Futon web的mongodb山寨版
# Mongo3 – Ruby写成。
# MongoHub – 适用于OSX的应用程序。
# Opricot – 一个基于浏览器的MongoDB控制台, 由php撰写而成。
# Database Master — Windows的mongodb管理工具
# RockMongo — 最好的PHP语言的MongoDB管理工具,轻量级, 支持多国语言.
MongoDB应用案例
# Craiglist上使用MongoDB的存档数十亿条记录。
# FourSquare,基于位置的社交网站,在Amazon EC2的服务器上使用MongoDB分享数据。
# Shutterfly,以互联网为基础的社会和个人出版服务,使用MongoDB的各种持久性数据存储的要求。
# bit.ly, 一个基于Web的网址缩短服务,使用MongoDB的存储自己的数据。
# spike.com,一个MTV网络的联营公司, spike.com使用MongoDB的。
# Intuit公司,一个为小企业和个人的软件和服务提供商,为小型企业使用MongoDB的跟踪用户的数据。
# sourceforge.net,资源网站查找,创建和发布开源软件免费,使用MongoDB的后端存储。
# etsy.com ,一个购买和出售手工制作物品网站,使用MongoDB。
# 纽约时报,领先的在线新闻门户网站之一,使用MongoDB。
# CERN,著名的粒子物理研究所,欧洲核子研究中心大型强子对撞机的数据使用MongoDB。
MongoDB后台管理Shell
如果你需要进入MongoDB后台管理,你需要先打开mongodb装目录的下的bin目录,然后执行mongo命令文件;
MongoDB Shell是MongoDB自带的交互式javascript shell,用来对MongoDB进行操作和管理的交互式环境。
当你进入mongoDB后台后,它默认会链接到 test 文档(数据库):
# 启动mongod服务后,再执行mongo就会进入下面命令行
mongo
MongoDB shell version: 3.0.6
connecting to: test
Welcome to the MongoDB shell.
# 新版本MongDB增加了安全性设计,推荐用户创建使用数据库时进行验证。如果用户想建立简单连接,则会提示警示信息
#创建管理员账号并设置密码:
>use admin
switched to db admin
> db.createUser( {user: "firstadmin",pwd: "123456",roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]});
Successfully added user: {
"user" : "firstadmin",
"roles" : [
{
"role" : "userAdminAnyDatabase",
"db" : "admin"
}
]
}
# 由于它是一个JavaScript shell,还可以运行一些简单的算术运算
> 1+1
2
> 10000+20000
30000
# 我们可以插入一些简单的数据,并对插入数据进行检索
> db.youmen.insert({x:10})
# 这个命令表示将数字10插入到youmen集合的x字段中
WriteResult({ "nInserted" : 1 })
> db.youmen.find()
{ "_id" : ObjectId("5eec1c706808f6fb8fbda718"), "x" : 10 }
MongoDB Web用户界面
MongoDB 提供了简单的 HTTP 用户界面。 如果你想启用该功能,需要在启动的时候指定参数 --rest 。
mongod --dbpath=/data/db --rest
# MongoDB 的 Web 界面访问端口比服务的端口多1000。
# 如果你的MongoDB运行端口使用默认的27017,你可以在端口号为28017访问web用户界面,即地址为:http://localhost:28017
基本操作
默认存在的库
> show databases;
admin 0.000GB
local 0.000GB
数据库对象(库(database),表(collection),行(document))
DB级别命令
db 显示当前数据库
db.getName() 显示当前数据库
db.[TAB] 类似于linux中的tab功能补全
db.help() db级别的命令使用帮助
db.version() 查看当前db版本
db.stats() 显示当前数据库状态
db.getMongo() 查看当前数据库的连接机器地址
collection级别
> db.Collection_name.xxx xxx操作
> db.createCollection("youmen")
> db.getCollection("youmen")
test.youmen
> db.youmen.drop()
> show tables;
document级别
db.t1.insert()
复制集有关(replication set)
查看复制集状态
rs.status(); //查看整体复制集状态
rs.isMaster(); //查看当前是否是主节点
rs.conf(); //查看复制集配置信息
添加删除节点
rs.remove("ip:port"); //删除一个节点
rs.add("ip:port"); //新增从节点
rs.addArb("ip:port"); //新增仲裁节点
freeze()和stepDown单位都是秒。
rs.stepDown() //副本集角色切换(不要人为随便操作)
rs.freeze(300) //锁定从,使其不会转变成主库
rs.slaveOk() //设置副本节点可读:在副本节点执行
>rs.printSlaveReplicationInfo() //查看副本节点(监控主从延时)
source: 10.9.119.18:28018
syncedTo: Sat Apr 17 2021 13:28:11 GMT+0800 (CST)
0 secs (0 hrs) behind the primary
source: 10.9.119.18:28019
syncedTo: Sat Apr 17 2021 13:28:11 GMT+0800 (CST)
0 secs (0 hrs) behind the primary
分片集群(sharding cluster)
sh.status(); 分片集群整体状态查看
use admin
db.runCommand({ isdbgrid : 1}) 判断是否Shard集群
db.runCommand({ listshards : 1}) 列出所有分片信息
db.printShardingStatus() 查看分片的详细信息
列出开启分片的数据库
use config
db.databases.find( { "partitioned": true } ) 或者 db.databases.find() //列出所有数据库分片情况
db.collections.find().pretty() 查看分片的片键
删除分片节点(谨慎)
sh.getBalancerState() 确认blance是否在工作
db.runCommand( { removeShard: "shard2" } ) 删除shard2节点(谨慎)
删除操作一定会立即触发blancer!!!
库的操作
use local 创建数据库:当use的时候,系统就会自动创建一个数据库。如果use之后没有创建任何集合,系统就会删除这个数据库。
db.dropDatabase() 删除数据库
集合的操作
方法一:创建集合
> use app
switched to db app
> db.createCollection(\'a\') 创建集合
{ "ok" : 1 }
> db.createCollection(\'b\') 创建集合
{ "ok" : 1 }
> show collections 查看库当前集合
a
b
> db.getCollectionNames() 查看库当前集合
[ "a", "b" ]
方法二:当插入一个文档的时候,一个集合就会自动创建
> use app1
switched to db app1
> db.app1.insert({id:"18",name:"youmen",age:"22",gender:"male",address:"bj"})
WriteResult({ "nInserted" : 1 })
> show collections
app1
查询数据
> db.app1.find({id:"18"}) // 方法一
{ "_id" : ObjectId("607b1968252509b70b4f24c8"), "id" : "18", "name" : "youmen", "age" : "22", "gender" : "male", "address" : "bj" }
> db.app1.find({id:"18"}).pretty()
{
"_id" : ObjectId("607b1968252509b70b4f24c8"),
"id" : "18",
"name" : "youmen",
"age" : "22",
"gender" : "male",
"address" : "bj"
}
删除集合
> db.app1.drop()
true
> show collections
app
app2
重命名集合
> show collections
app
app2
> db.app2.renameCollection("app1") // 重命名
{ "ok" : 1 }
> show collections
app
app1
文档的操作
批量插入数据
for(i=0;i<10000;i++){db.app.insert({"uid":i,"name":"youmen","age":22,"date":new Date()})}
查询集合中的记录数
db.app.find() // 默认每页显示20条记录,当显示不下的的情况下,可以用it迭代命令查询下一页数据。
设置每页显示数据的大小:
> DBQuery.shellBatchSize=50 //每页显示50条记录
> db.app.findOne() //查看第1条记录
> db.app.count() //查询总的记录数
删除集合中的记录数
db.app.distinct("name") //查询去掉当前集合中某列的重复数据,去重
db.app.remove({}) //删除集合中所有记录
查看集合存储信息
db.app.stats() //详细信息
db.app.dataSize() //集合中数据的原始大小
db.app.totalIndexSize() //集合中索引数据的原始大小
db.app.totalSize() //集合中索引+数据压缩存储之后的大小 字节为单位
db.app.storageSize() //集合中数据压缩存储的大小
常用的命令
show dbs 查询所有数据库
show tables 查看所有的collection
use local 切换数据库
MongoDB概念解析
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
通过下图实例,我们也可以直观的了解Mongo中的一些概念
数据库
一个mongodb中可以建立多个数据库;
MongoDB的默认数据库为"db",该数据库存储在data目录中;
MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中;
"show dbs" 命令可以显示所有数据的列表;
> show dbs
local 0.078GB
test 0.078GB
# db显示当前数据库对象或集合
> db
test
# use命令,连接到一个指定的数据库
> use local
switched to db local
> db
local
数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串;
# 不能是空字符串("")。
# 不得含有\' \'(空格)、.、$、/、\\和\\0 (空字符)。
# 应全部小写。
# 最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库;
admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器;
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
文档(Document)
文档是一组键值(key-value)对(即 BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点;
一个简单的文档例子如下:
{"site":"www.youmen.com", "name":"幽梦"}
下表列出了RDBMS与MongoDB对应的术语
| RDBMS | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
| 数据库服务和客户端 | |
| Mysqld/Oracle | mongod |
| mysql/sqlplus | mongo |
需要注意的是
# 1. 文档中的键/值对是有序的;
# 2. 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档);
# 3. MongoDB区分类型和大小写;
# 4. MongoDB的文档不能有重复的键;
# 5. 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符;
# 文档键命名规范:
# 键不能含有\\0 (空字符)。这个字符用来表示键的结尾;
# .和$有特别的意义,只有在特定环境下才能使用;
# 以下划线"_"开头的键是保留的(不是严格要求的);
集合
集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表格。
集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
比如,我们可以将以下不同数据结构的文档插入到集合中:
{"site":"www.baidu.com"}
{"site":"www.google.com","name":"Google"}
{"site":"www.youmen.com","name":"幽梦","num":5}
当第一个文档被插入时,集合就会合法的集合名
# 集合名不能是空字符串""。
# 集合名不能含有\\0字符(空字符),这个字符表示集合名的结尾。
# 集合名不能以"system."开头,这是为系统集合保留的前缀。
# 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
Capped Collections
Capped collections 就是固定大小的collection。
它有很高的性能以及队列过期的特性(过期按照插入的顺序). 有点和 "RRD" 概念类似。
Capped collections 是高性能自动的维护对象的插入顺序。它非常适合类似记录日志的功能和标准的 collection 不同,你必须要显式的创建一个capped collection,指定一个 collection 的大小,单位是字节。collection 的数据存储空间值提前分配的。
Capped collections 可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存的,所以当我们更新Capped collections 中文档的时候,更新后的文档不可以超过之前文档的大小,这样话就可以确保所有文档在磁盘上的位置一直保持不变。
由于 Capped collection 是按照文档的插入顺序而不是使用索引确定插入位置,这样的话可以提高增添数据的效率。MongoDB 的操作日志文件 oplog.rs 就是利用 Capped Collection 来实现的。
要注意的是指定的存储大小包含了数据库的头信息。
db.createCollection("mycoll", {capped:true, size:100000})
在 capped collection 中,你能添加新的对象。
能进行更新,然而,对象不会增加存储空间。如果增加,更新就会失败 。
使用 Capped Collection 不能删除一个文档,可以使用 drop() 方法删除 collection 所有的行。
删除之后,你必须显式的重新创建这个 collection;
在32bit机器中,capped collection 最大存储为 1e9( 1X109)个字节。
元数据
数据库的信息是存储在集合中。它们使用了系统的命名空间:
dbname.system.*
在MongoDB数据库中名字空间 <dbname>.system.* 是包含多种系统信息的特殊集合(Collection),如下:
| 集合命名空间 | 描述 |
|---|---|
| dbname.system.namespaces | 列出所有名字空间。 |
| dbname.system.indexes | 列出所有索引。 |
| dbname.system.profile | 包含数据库概要(profile)信息。 |
| dbname.system.users | 列出所有可访问数据库的用户。 |
| dbname.local.sources | 包含复制对端(slave)的服务器信息和状态。 |
对于修改系统集合中的对象有如下限制。
在{{system.indexes}}插入数据,可以创建索引。但除此之外该表信息是不可变的(特殊的drop index命令将自动更新相关信息)。
{{system.users}}是可修改的。 {{system.profile}}是可删除的。
MongoDB数据类型
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
下面说明几种重要的数据类型
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
# 前 4 个字节表示创建 **unix** 时间戳,格林尼治时间 **UTC** 时间,比北京时间晚了 8 个小时
# 接下来的 3 个字节是机器标识码
# 紧接的两个字节由进程 id 组成 PID
# 最后三个字节是随机

MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间:
> var newObject = ObjectId()
> newObject.getTimestamp()
ISODate("2020-06-19T02:44:34Z")
Objectid转换为字符串
> newObject.str
5eec2692383608904cb30cb6
字符串
BSON 字符串都是 UTF-8 编码
时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。 时间戳值是一个 64 位的值。其中:
# 前32位是一个 time_t 值(与Unix新纪元相差的秒数)
# 后32位是在某秒中操作的一个递增的`序数`
在单个 mongod 实例中,时间戳值通常是唯一的。
在复制集中, oplog 有一个 ts 字段。这个字段中的值使用BSON时间戳表示了操作时间。
BSON 时间戳类型主要用于 MongoDB 内部使用。在大多数情况下的应用开发中,你可以使用 BSON 日期类型。
日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。
> var mydate1 = new Date()
> mydate1
ISODate("2020-06-19T02:49:22.128Z")
> var mydate2 = ISODate()
> mydate2
ISODate("2020-06-19T02:47:44.664Z")
# 这样创建的时间是日期类型,可以使用 JS 中的 Date 类型的方法。
# 返回一个时间类型的字符串:
> var mydate1str = mydate1.toString()
> mydate1str
Fri Jun 19 2020 10:49:22 GMT+0800 (CST)
> typeof mydate1str
string
OR
> Date()
Fri Jun 19 2020 10:53:15 GMT+0800 (CST)
用户管理
** 验证库是建立用户时use到的库(db 查看),在使用用户时, 要加上验证库才能登陆
对于管理员用户,必须在admin下创建**
步骤:
1. 建用户时,use到的库,就是此用户的验证库
2. 登录时,必须明确指定验证库才能登录
3. 通常,管理员用的验证库是admin,普通用户的验证库一般是所管理的库设置为验证库
4. 如果直接登录到数据库,不进行use,默认的验证库是test,生产不建议使用test库
查看用户
use admin
db.system.users.find().pretty()
删除用户
use app
db.dropUser("app02")
创建语法
db.createUser
{
user: "<name>",
pwd: "<cleartext password>",
roles: [
{ role: "<role>",
db: "<database>" } | "<role>",
...
]
}
基本语法说明:
user:用户名
pwd:密码
roles:
role:角色名 //role:root(超级管理员),dbAdmin(库管理员),readWrite(读写),read(只读)
db:作用对象(库)
用户管理Example
创建超级管理员
必须use admin再去创建
use admin
db.createUser(
{
user: "root",
pwd: "admin",
roles: [ { role: "root", db: "admin" } ]
}
)
验证用户
db.auth(\'root\',\'admin\')
配置文件中,加入以下配置
security:
authorization: enabled
重启mongodb
mongod -f /mongodb/conf/mongo.conf --shutdown
mongod -f /mongodb/conf/mongo.conf
登录验证
mongo -uroot -padmin admin
或者
mongo -uroot -padmin 10.9.119.18/admin
或者
mongo
use admin
db.auth(\'root\',\'admin\')
创建库管理用户
use app
db.createUser(
{
user: "app",
pwd: "admin",
roles: [ { role: "dbAdmin", db: "app" } ]
}
)
// 认证
> db.auth(\'app\',\'admin\')
1
// 登录测试
mongo -uapp -padmin app
创建对app数据库,读、写权限的用户
use app
db.createUser(
{
user: "app01",
pwd: "app01",
roles: [ { role: "readWrite", db: "app" } ]
}
)
认证
> db.auth(\'app01\',\'app01\')
1
登录测试
mongo -uapp01 -papp01 app
创建对app数据库读写权限的用户并对test数据库具有读权限
use app
db.createUser(
{
user: "app02",
pwd: "app02",
roles: [ { role: "readWrite", db: "app" },
{ role: "read", db: "test" }
]
}
)
认证
> db.auth(\'app02\',\'app02\')
1
登录测试
mongo -uapp02 -papp02 app