数据中心网络之百家讲坛
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据中心网络之百家讲坛相关的知识,希望对你有一定的参考价值。
参考技术A 最近因为写论文的关系,泡知网、泡万方,发现了很多学术界对数据中心网络一些构想,发现里面不乏天才的想法,但日常我们沉迷在各个设备厂商调制好的羹汤中无法自拔,管中窥豹不见全局,还一直呼喊着“真香”,对于网工来说沉溺于自己的一方小小天地不如跳出来看看外界有哪些新的技术和思想,莫听穿林打叶声,何妨吟啸且徐行当前新的数据中心网络拓扑主要分为两类
1、以交换机为核心,网络连接和路由功能由交换机完成,各个设备厂商的“羹汤”全属于这个领域
2、以服务器为核心,主要互联和路由功能放在服务器上,交换机只提供简单纵横制交换功能
第一类方案中包含了能引发我回忆阴影的Fat-Tree,和VL2、Helios、c-Through、OSA等等,这些方案要么采用更多数量交换机,要么融合光交换机进行网络互联,对交换机软件和硬件要求比较高,第二类主要有DCell、Bcube、FiConn、CamCube、MDCube等等,主要推动者是微软,这类方案中服务器一版会通过多网卡接入网络,为了支持各种流量模型,会对服务器进行硬件和软件的升级。
除了这些网络拓扑的变化外,其实对数据中心网络传输协议TCP/IP、网络虚拟化、网络节能机制、DCI网络互联都有很多创新的技术和概念涌现出来。
FatTree 胖树,2008年由UCSD大学发表的论文,同时也是5年前工作中接触的第一种交换机为中心的网络拓扑,当时没有太理解,跟客户为这事掐的火星四溅,再来一次可能结论会有所改变,同时也是这篇论文引发了学术界对数据中心内部网络拓扑设计的广泛而深刻的讨论,他提出了一套组网设计原则来达成几个目的
1、全网采用低端商用交换机来组网、其实就是采用1U的接入交换机,取消框式设备
2、全网无阻塞
3、成本节省,纸面测算的话FatTree 可以降为常规模式组网成本的1/4或1/5
物理拓扑(按照4个pod设计)
FatTree 的设计原则如下
整个网络包含K个POD,每个POD有K/2个Edge和K/2个Agg 交换机,他们各有K的接口,Edge使用K/2个端口下联服务器,Agg适用K/2个端口上联CORE交换机
Edge使用K/2个端口连接服务器,每个服务器占用一个交换端口
CORE层由K/2*K/2共计KK/4个K个端口交换机组成,分为K/2组,每组由K/2ge,第一组K/2台CORE交换机连接各个POD中Agg交换层一号交换机,第二组K/2的CORE交换机连接各POD中Agg的二号交换机,依次类推
K个POD,每个POD有K/2个Edge交换机,每个Edge有K/2端口,服务器总数为K*K/2*K/2=KKK/4
K取值4的话,服务器总数为16台
常规K取值48的话,服务器为27648台
FatTree的路由设计更加有意思,论文中叫两阶段路由算法,首先要说明的是如果使用论文中的算法是需要对交换机硬软件进行修改的,这种两阶段路由算法和交换设备及服务器的IP地址强相关,首先就是IP地址的编制,这里依然按照K=4来设计,规则如下
1、POD中交换机IP为10.pod.switch.1,pod对应POD编号,switch为交换机所在POD编号(Edge从0开始由左至右到k/2-1,Agg从k/2至k-1)
2、CORE交换机IP为10.k.j.i ,k为POD数量,j为交换机在Core层所属组编号,i为交换机在该组中序号
3、服务器IP为10.pod.switch.ID,ID为服务器所在Edge交换机序号,交换机已经占用.1,所以从2开始由左至右到k/2+1
设计完成后交换机和服务器的IP地址会如下分配
对于Edge交换机(以10.2.0.1为例)第一阶段匹配10.2.0.2和10.2.0.3的32位地址,匹配则转发,没有匹配(既匹配0.0.0.0/0)则根据目的地址后8位,也就是ID号,选择对应到Agg的链路,如目标地址为x.x.x.2则选择到10.2.2.1的链路,目标地址为x.x.x.3则选择到10.2.3.1的链路
对于Agg交换机(以10.2.2.1为例)第一阶段匹配本POD中网段10.2.0.0/24和10.2.1.0/24,匹配成功直接转发对应Edge,没有匹配(既匹配0.0.0.0/0)则根据目的地址后8位,也就是ID号确定对应到Core的链路,如目标地址为x.x.x.2则选择到10.4.1.1的链路,目标地址为x.x.x.3则选择到10.4.1.2的链路
对于Core交换机,只有一个阶段匹配,只要根据可能的POD网段进行即可,这里是10.0.0.0/16~10.3.0.0/16对应0、1、2、3四个口进行转发
容错方面论文提到了BFD来防止链路和节点故障,同时还有流量分类和调度的策略,这里就不展开了,因为这种两阶段路由算法要对交换机硬件进行修改,适应对IP后8位ID进行匹配,现实中没有看到实际案例,但是我们可以设想一下这种简单的转发规则再加上固定端口的低端交换机,对于转发效率以及成本的压缩将是极为可观的。尤其这种IP地址规则的设计配合路由转发,思路简直清奇。但是仔细想想,这种按照特定规则的IP编制,把每个二层限制在同一个Edge交换机下,注定了虚拟机是没有办法跨Edge来迁移的,只从这点上来看注定它只能存在于论文之中,但是顺着这个思路开个脑洞,还有什么能够编制呢?就是MAC地址,如果再配上集中式控制那就更好了,于是就有了一种新的一种路由方式PortLand,后续我们单独说。
如此看来FatTree 是典型的Scale-out模式,但是由于一般交换机端口通常为48口,如果继续增加端口数量,会导致成本的非线性增加,底层Edge交换机故障时,难以保障服务质量,还有这种拓扑在大数据的mapreduce模型中无法支持one-to-all和all-to-all模式。
把脑洞开的稍微小一些,我们能否用通用商业交换机+通用路由来做出来一种FatTree变种拓扑,来达到成本节省的目的呢,答案一定是确切的,目前能看到阿里已经使用固定48口交换机搭建自己的变种FatTree拓扑了。
以交换机为中心的网络拓扑如VL2、Helios不再多说,目前看到最好的就是我们熟知的spine-leaf结构,它没有设计成1:1收敛比,而且如果使用super层的clos架构,也可以支撑几万台或者百万台的服务器规模,但是FaTtree依靠网络拓扑取消掉了框式核心交换机,在一定规模的数据中心对于压低成本是非常有效的
聊完交换机为核心的拓扑设计后,再来看看服务器为核心的拓扑,同样这些DCell、Bcube、FiConn、CamCube、MDCube等,不会全讲,会拿DCell来举例子,因为它也是2008年由微软亚洲研究院主导,几乎和FatTree同时提出,开创了一个全新的思路,随后的年份里直到今天一直有各种改进版本的拓扑出现
这种服务器为核心的拓扑,主导思想是在服务器上增加网卡,服务器上要有路由转发逻辑来中转流量数据包,并且采用递推方式进行组网。
DCell的基本单元是DCell0,DCell0中服务器互联由一台T个端口的mini交换机完成,跨DCell的流量要通过服务器网卡互联进行绕转。通过一定数量的Dcell0组成一个DCell1,按照一定约束条件进行递推,组成DCell2以及DCellk
上图例中是一个DCell1的拓扑,包含5个Dcell0,每台服务器2个端口,除连接自己区域的mini交换机外,另一个端口会依次连接其他DCell0中的服务器,来组成全互联的结构,最终有20台服务器组成DCell1,所有服务器按照(m,n)坐标进行唯一标识,m相同的时候直接通过moni交换机交互,当m不同时经由mini交换机中继到互联服务器,例子中红色线为4.0服务器访问1.3服务器的访问路径。
DCell组网规则及递归约束条件如下:
DCellk中包含DCellk-1的数量为GK
DCellk中包含服务器为Tk个,每台服务器k+1块网卡,则有
GK=Tk-1+1
TK=Gk-1 ✕ Tk-1
设DCell0中有4台服务器
DCell1 中有5个DCell0 (G1=5)
Tk1=20台服务器(T1=20)
DCell2 中有21个DCell1 (G2=21)
Tk2=420台服务器(T2=420)
DCell3 中有421个DCell2 (G3=421)
Tk3=176820台服务器(T3=176820)
…
Tk6=3260000台服务器
经过测算DCell3中每台服务器的网卡数量为4,就能组建出包含17万台服务器的数据中心,同样DCell的缺点和优点一样耀眼,这种递归后指数增长的网卡需求量,在每台服务器上可能并不多,但是全量计算的话就太过于惊人了,虽然对比FatTree又再一次降低交换机的采购成本,但是天量的网卡可以想象对于运维的压力,还有关键的问题时高层次DCell间通信占用低层次DCell网卡带宽必然导致低层次DCell经常拥塞。最后还有一个实施的问题,天量的不同位置网卡布线对于施工的准确度以及未知的长度都是一个巨大的挑战。
DCell提出后,随后针对网卡数量、带宽抢占等一系列问题演化出来一批新的网络拓扑,思路无外乎两个方向,一个是增加交换机数量减少单服务网卡数量,趋同于spine-leaf体系,但是它一直保持了服务器多网卡的思路。另一种是极端一些,干脆消灭所有交换机,但是固定单服务器网卡数量,按照矩阵形式组建纯服务器互联结构,感兴趣的同学可以继续探索。
数据中心的路由框架涵盖范围和领域非常多,很多论文都选择其中的一个点进行讨论,比如源地址路由、流量调度、收敛、组播等等,不计划每个展开,也没有太大意义。但是针对之前FatTree的两阶段路由有一个更新的路由框架设计PortLand,它解决了两段路由中虚拟机无法迁移的问题,它的关键技术有以下几点
1、对于FatTree这种高度规范化的拓扑,PortLand设计为采用层次化MAC编址来支持大二层,这种路由框架中,除了虚拟机/物理机实际的MAC外(AMAC),还都拥有一个PortLand规范的伪MAC(PMAC),网络中的转发机制和PMAC强相关,PMAC的编址规则为
pod.position.port.vmid
pod (2字节) 代表虚拟机/服务器所在POD号,position(1字节)虚拟机/服务器所在Edge交换机在POD中编号,port(1字节)虚拟机/服务器连接Edge交换机端口的本地编号,vmid(2字节)服务器在Edge下挂以太网交换机编号,如果只有一台物理机vmid只能为1
2、虚拟机/服务器的编址搞定后,Edge、Aggregate、Core的编址呢,于是PortLand设计了一套拓扑发现机制LDP(location discovery protocol),要求交换机在各个端口上发送LDP报文LDM(location
discovery message)识别自己所处位置,LDM消息包含switch_id(交换机自身mac,与PMAC无关)pod(交换机所属pod号)pos(交换机在pod中的编号)level(Edge为0、Agg为1、Core为2)dir(上联为1,下联为-1),最开始的时候Edge角色会发现连接服务器的端口是没有LDM的,它就知道自己是Edge,Agg和Core角色依次收到LDM后会计算并确定出自己的leve和dir等信息。
3、设计一个fabric manager的集中PortLand控制器,它负责回答Edge交换机pod号和ARP解析,当Edge交换机学习到一个AMAC时,会计算一个PMAC,并把IP/AMAC/PMAC对应关系发送给fabric manager,后续有虚拟机/服务器请求此IP的ARP时,会回复PMAC地址给它,并使用这个PMAC进行通信。
4、由于PMAC的编址和pod、pos、level等信息关联,而所有交换机在LDM的交互过程中知晓了全网的交换机pod、pos、level、dir等信息,当数据包在网络中传播的时候,途径交换机根据PMAC进行解析可得到pod、pos这些信息,根据这些信息即可进行数据包的转发,数据包到达Edge后,Edge交换机会把PMAC改写为AMAC,因为它是知道其对应关系的。当虚拟机迁移后,由fabric manager来进行AMAC和PMAC对应更新和通知Edge交换机即可,论文中依靠虚拟机的免费ARP来触发,这点在实际情况中执行的效率要打一个问号。
不可否认,PortLand的一些设计思路非常巧妙,这种MAC地址重写非常有特色。规则设计中把更多的含义赋给PMAC,并且通过LDP机制设计为全网根据PMAC即可进行转发,再加上集中的控制平面fabric manager,已经及其类似我们熟悉的SDN。但是它对于转发芯片的要求可以看出要求比较低,但是所有的转发规则会改变,这需要业内对于芯片和软件的全部修改,是否能够成功也看市场驱动力吧,毕竟市场不全是技术驱动的。
除了我们熟悉的拓扑和路由框架方面,数据中心还有很多比较有意思的趋势在发生,挑几个有意思的
目前数据中心都是以太网有线网络,大量的高突发和高负载各个路由设架构都会涉及,但是如果使用无线是不是也能解决呢,于是极高频技术在数据中心也有了一定的研究(这里特指60GHZ无线),其吞吐可达4Gbps,通过特殊物理环境、波束成形、有向天线等技术使60GHZ部署在数据中心中,目前研究法相集中在无线调度和覆盖中,技术方案为Flyways,它通过合理的机柜摆放及无线节点空间排布来形成有效的整体系统,使用定向天线和波束成形技术提高连接速率等等新的技术,甚至还有一些论文提出了全无线数据中心,这样对数据中心的建设费用降低是非常有助力的。
数据中心目前应用的还是TCP,而TCP在特定场景下一定会遇到性能急剧下降的TCP incast现象,TCP的拥塞避免和慢启动会造成当一条链路拥塞时其承载的多个TCP流可能会同时触发TCP慢启动,但随着所有的TCP流流量增加后又会迅速达到拥塞而再次触发,造成网络中有时间流量很大,有时间流量又很小。如何来解决
数据中心还有很多应用有典型的组通信模式,比如分布式存储、软件升级等等,这种情况下组播是不是可以应用进来,但是组播在数据中心会不会水土不服,如何解决
还有就是数据中心的多路径,可否从TCP层面进行解决,让一条TCP流负载在不同的链路上,而不是在设备上依靠哈希五元组来对每一条流进行特定链路分配
对于TCPincast,一般通过减少RTO值使之匹配RTT,用随机的超时时间来重启动TCP传输。还有一种时设计新的控制算法来避免,甚至有方案抛弃TCP使用UDP来进行数据传输。
对于组播,数据中心的组播主要有将应用映射为网络层组播和单播的MCMD和Bloom Filter这种解决组播可扩展性的方案
对于多路径,提出多径TCP(MPTCP),在源端将数据拆分成诺干部分,并在同一对源和目的之间建立多个TCP连接进行传输,MPTCP对比传统TCP区别主要有
1、MPTCP建立阶段,要求服务器端向客户端返回服务器所有的地址信息
2、不同自流的源/目的可以相同,也可以不同,各个子流维护各自的序列号和滑动窗口,多个子流到达目的后,由接收端进行组装
3、MPTCP采用AIMD机制维护拥塞窗口,但各个子流的拥塞窗口增加与所有子流拥塞窗口的总和相关
还有部分针对TCP的优化,如D3协议,D3是针对数据中心的实时应用,通过分析数据流的大小和完成时间来分配传输速率,并且在网络资源紧张的时候可以主动断开某些预计无法完成传输的数据流,从而保证更多的数据流能按时完成。
这的数据中心节能不会谈风火水电以及液冷等等技术,从网络拓扑的角度谈起,我们所有数据中心拓扑搭建的过程中,主要针对传统树形拓扑提出了很多“富连接”的拓扑,来保证峰值的时候网络流量的保持性,但是同时也带来了不在峰值条件下能耗的增加,同时我们也知道数据中心流量多数情况下远低于其峰值设计,学术界针对这块设计了不少有脑洞的技术,主要分为两类,一类时降低硬件设备能耗,第二类时设计新型路由机制来降低能耗。
硬件能耗的降低主要从设备休眠和速率调整两个方面来实现,其难点主要时定时机制及唤醒速度的问题,当遇到突发流量交换机能否快速唤醒,人们通过缓存和定时器组合的方式进行。
节能路由机制,也是一个非常有特点的技术,核心思想是通过合理的选择路由,只使用一部分网络设备来承载流量,没有承载流量的设备进行休眠或者关闭。Elastic Tree提出了一种全网范围的能耗优化机制,它通过不断的检测数据中心流量状况,在保障可用性的前提下实时调整链路和网络设备状态,Elastic Tree探讨了bin-packer的贪心算法、最优化算法和拓扑感知的启发算法来实现节能的效果。
通过以上可以看到数据中心发展非常多样化,驱动这些技术发展的根本性力量就是成本,人们希望用最低的成本达成最优的数据中心效能,同时内部拓扑方案的研究已经慢慢成熟,目前设备厂商的羹汤可以说就是市场化选择的产物,但是数据中心网络传输协议、虚拟化、节能机制、SDN、服务链等方向的研究方兴未艾,尤其是应用定制的传输协议、虚拟网络带宽保障机制等等,这些学术方面的研究并不仅仅是纸上谈兵,对于我知道的一些信息来说,国内的阿里在它的数据中心网络拓扑中早已经应用了FatTree的变种拓扑,思科也把数据中心内部TCP重传的技术应用在自己的芯片中,称其为CONGA。
坦白来说,网络从来都不是数据中心和云计算的核心,可能未来也不会是,计算资源的形态之争才是主战场,但是网络恰恰是数据中心的一个难点,传统厂商、学术界、大厂都集中在此领域展开竞争,创新也层出不穷,希望能拓展我们的技术视野,能对我们有一些启发,莫听穿林打叶声、何妨吟啸且徐行~
C讲坛之猜数字游戏的实现
大家好,这次博主将一步步教大家如何用C语言实现简单的猜数字游戏
目标:猜数字游戏
要求:随机生成一个1~100的值
输入猜测值后,如果猜测值大于随机值,会提醒“猜大了”,如果小于测试值,会提醒“猜小了”,如果猜测正确,提醒“恭喜你,猜对了”,此时游戏结束,新的一轮游戏开始。
一.首先我们先设定一个基本框架
#define _CRT_SECURE_NO_WARNINGS 1
//vs编译器使用scanf函数防报错
#include <stdio.h>
int main()
int input=0;
do
menu();//设定一个生成菜单的函数
printf("请选择:>");
scanf("%d",&input);
switch(input)
case 1: game(); break;//设定game函数进行游戏
//输入1开始游戏
case 0: printf("退出游戏");break;
//输入0退出游戏
default:printf("选择错误");break;
//输入其他的值会提醒选择错误
while(input);//用dowhile语句可以跳过判断语句直接生成菜单
return 0;
二. 设定菜单menu函数和游戏game函数
1. 游戏的开始生成一个菜单menu 用以让玩家选择是否开始游戏
void menu()
printf("********************************************\\n");
printf("*********** 1.play ************\\n");
printf("*********** 0.exit ************\\n");
printf("********************************************\\n");
2. 猜数字游戏主体
C语言中使用rand函数生成随机数,关于rand函数的具体使用方法,我们可以借助MSDN上查询一下


由此我们可知rand函数的作用是生成一个随机数,并且调用这个函数需要头文件#include <stdlib.h>。并且从Remarks(注意)可得知,这个随机值的取值范围为0到RAND_MAX,那么问题来了,RAND_MAX的值又是多少呢?
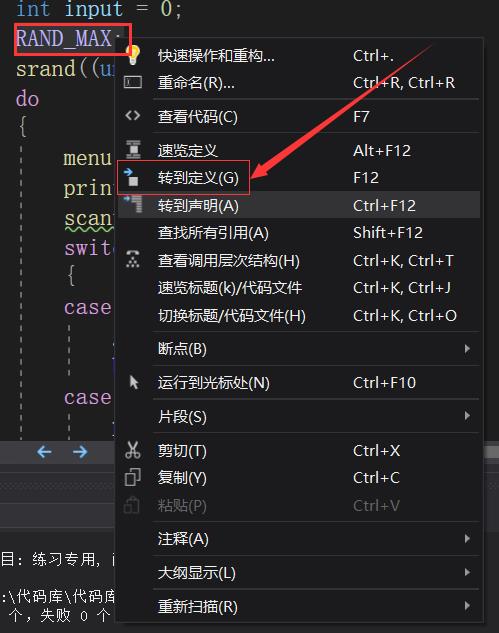
我们在编译器上输入这个值然后按照上图所示的方法点击转到定义

可以看到#define定义的标识符常量RAND_MAX的值为0x7fff,这是一个十六进制的值,通过计算器转化为十进制的值为32767,所以rand函数的最大值为32767。再来看后半句话可知在调用rand之前,需要使用srand函数为伪随机数生成器设置种子,也就是说在使用rand函数之前需要使用srand函数。再次借助MSDN查找srand函数。

也就是说我们要给定srand函数一个值以让rand函数生成一个随机值,这时候似乎变的离谱了起来,我们想要生成一个随机值但又要每次给它设定一个随机值?那要怎么实现我们想要达到的效果呢?我们知道时间是无时无刻变化的,因此我们可以利用“时间”这个随机值,来充当srand函数里的seed。在这里我们需要引入“时间戳”这个概念
时间戳是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数。

任何一个时间都可以转换成一个时间戳,而想要调用时间戳需要使用time函数,我们再次借助MSDN查询time函数。

由此我们可以得知使用time函数需要加上头文件#include <time.h>
于是我们可以得到猜数字游戏的主体game()
void game()
int guess = 0;
int r = rand()%100+1;
//任何大于100的值%上100后的范围为0~99
//+1以后的范围为1~100
while (1)
printf("请输入:>");
scanf("%d", &guess);
if (guess > r)
printf("猜大了\\n");
else if (guess < r)
printf("猜小了\\n");
else
printf("恭喜你 猜对了\\n");
break;
三.猜数字游戏的最终实现
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void menu()
printf("********************************************\\n");
printf("*********** 1.play ************\\n");
printf("*********** 0.exit ************\\n");
printf("********************************************\\n");
void game()
int guess = 0;
int r = rand()%100+1;
while (1)
printf("请输入:>");
scanf("%d", &guess);
if (guess > r)
printf("猜大了\\n");
else if (guess < r)
printf("猜小了\\n");
else
printf("恭喜你 猜对了\\n");
break;
int main()
int input = 0;
srand((unsigned int)time(NULL));
do
menu();
printf("请选择:>");
scanf("%d", &input);
switch (input)
case 1:
game();
break;
case 0:
printf("退出游戏");
break;
default:
printf("选择错误");
break;
while (input);
return 0;
(注意:要将srand((unsigned int)time(NULL))放到主函数里,如果放到game函数里可能会因为生成随机数过快导致不够随机即连续生成相同的随机值)
到这里,猜数字游戏就跟大家分享完啦,谢谢大家的支持呀!
(顺带一提,可以尝试再增加一个菜单来选择猜数字游戏的难度,自行设置猜数字的范围)
以上是关于数据中心网络之百家讲坛的主要内容,如果未能解决你的问题,请参考以下文章
运维百家讲坛第5期:度小满陈存利 - 20年老“司令”聊运维绩效成长