AutoEncoder
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AutoEncoder相关的知识,希望对你有一定的参考价值。
参考技术A 1.简介Autoencoder是一种无监督学习过程,由encode和decode构成,给定输入之后,经过encode将输入编码成code,然后在经过decode将code解码成输出,通过不断地训练,使得输入和输出尽可能相似。通过控制encode的输出维数,可以实现以低维参数学习高维特征,实现了降维。在训练的过程中,主要使用反向传播进行优化,使得输入和输出尽可能相似。
encode和decode两个过程可以理解成互为反函数,在encode过程不断降维,在decode过程提高维度。当AutoEncoder过程中用卷积操作提取特征,相当于encode过程为一个深度卷积神经网络,好多层的卷积池化,那么decode过程就需要进行反卷积和反池化(https://blog.csdn.net/roguesir/article/details/77469665)。
Autoencode并不需要使完全重构输入,只是需要学习到原始图像的重要特征,实现降维,从而有利于可视化或分类。下面使李宏毅机器学习可成长的一个利用autoencode进行text retrieval的例子。
2.应用
2.1文本检索
将每一个文本提取构建成一个向量,那么就可以轻易的根据余弦相似度等方法得到不同文本之间的相似度,找到我们需要的文本,那个,这个向量如何构建呢,最直接的方法就是利用词袋,若世界上一共有1000个词,那个这个文本对应的向量的维度是一千维的,每一个分量的取值为0或1,表示对应的单词在文档中有没有出现。但是这种方法构建的向量复杂,且没有考虑语义信息。Autoencode更好的解决了这个问题。
autoencode可以将向量不断压缩,压缩成一个二维的向量,右上角的图是Hinton在Science上发表的文章的结果图,将文章分为了不同的类别,query对应的类别如图中红点所示,描述的是Energy markets。而右下角所示的LSA并不能起到这种良好的分类效果。
2.2图像搜索
或许可以通过图片在像素上的相似程度来找到相似的图片,但是这样可能会存在问题。如下图,要找到图一的迈克尔杰克逊,但是直接计算像素上的相似性可能得到的相似性图片是后面那几张。
用Autoencode就可以解决这个问题,将图片层层编码成一个code,相当于对原图进行了压缩和特征提取,最后在code上进行处理来比较相似性。
2.3预训练深度神经网络
在进行神经网络训练的时候,通常需要初始化一些参数,如权重等。有一些方法可以实现这些参数的初始化,即pre-training,预训练。那么怎么进行这些参数的初始化呢?autoencode就可以完成这个工作
假如构建了一个如上图右边所示的神经网络,每一层的输入维度分别为784/1000/1000/500,那么在训练第一层的时候可以利用自编码器,如右图所示,将784维的输入输进自编码器,中间encode一千维,使得输出的结果和input越接近越好,这样就将输入转化成了一个一千维的code,就得到了可以用来初始化的第一层的参数W1.这里要注意,encode的code如果要比输入还要大,即这里的1000维大于784维,要小心自编码器将输入完全复制成code的情况,使得输入和输出是完全identity的。这一步将第一层的参数训练好之后就可以进行下一步
在固定第一层的参数的之后,可以得到一个1000维的输入,在输入一个自编码器中,将输入转化为1000维的code,保证输入和输出尽可能相似,此时可以得到第二层的参数W2,如此下去,将W1和W2固定,再通过自编码器可以得到W3,然后继续下图所示的过程。
将前三层参数预训练得到以后,将输出的结果进入最后一层,最后一层的参数可以随机初始化,然后根据最后的误差并利用反向传播算法进行调整。
4.在CNN上的应用
在卷积神经网络中,利用反向传播算法进行学习时,会有反卷积和反池化,就利用到了autoencode。
https://blog.csdn.net/sinat_25346307/article/details/79104612
3.几种自编码器
3.1De-noising auto-encode
https://blog.csdn.net/marsjhao/article/details/73480859
本文只是作者的粗浅的理解,想要了解更多内容可以看一下李宏毅老师的课程https://www.bilibili.com/video/av35932863/?p=24
Pytorch Note43 自动编码器(Autoencoder)
Pytorch Note43 自动编码器(Autoencoder)
全部笔记的汇总贴: Pytorch Note 快乐星球
自动编码器
自动编码器最开始是作为一种数据压缩方法,同时还可以在卷积网络中进行逐层预训练,但是随后更多结构复杂的网络,比如 resnet 的出现使得我们能够训练任意深度的网络,自动编码器就不再使用在这个方面,下面我们讲一讲自动编码器的一个新的应用,这是随着生成对抗模型而出现的,就是使用自动编码器生成数据。
其特点有:
(1)跟数据相关程度很高,这意味着自动编码器只能压缩与训练数据相似的数据.因为使用神经网络提取的特征一般是高度相关于原始的训练集,使用人脸训练出来的自动编码器在压缩自然界动物的图片时表现就会比较差,因为它只学习到了人脸的特征,而没有学习到自然界图片的特征。
(2)压缩后数据是有损的,这是因为在降维的过程中不可避免地要丢失信息。到了2012年,人们发现在卷积神经网络中使用自动编码器做逐层预训练可以训练更深层的网络,但是人们很快发现,良好的初始化策略要比复杂的逐层预训练有效得多,2014年出现的 Batch Normalization技术也使得更深的网络能够被有效训练,到了2015年年底,通过残差(ResNet)基本可以训练任意深度的神经网络。
所以现在自动编码器主要应用在两个方面:第一是数据去噪,第二是进行可视化降维。自动编码器还有一个功能,即生成数据。
自动编码器的一般结构如下
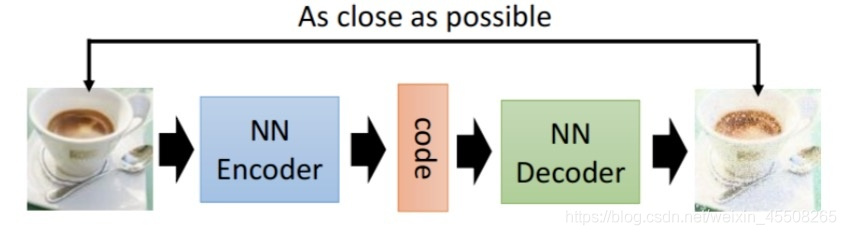
由上面的图片,我们能够看到,第一部分是编码器(encoder),第二部分是解码器(decoder),编码器和解码器都可以是任意的模型,通常我们可以使用神经网络作为我们的编码器和解码器,输入的数据经过神经网络降维到一个编码,然后又通过另外一个神经网络解码得到一个与原始数据一模一样的生成数据,通过比较原始数据和生成数据,希望他们尽可能接近,所以最小化他们之间的差异来训练网络中编码器和解码器的参数。
当训练完成之后,我们如何生成数据呢?非常简单,我们只需要拿出解码器的部分,然后随机传入 code,就可以通过解码器生成各种各样的数据
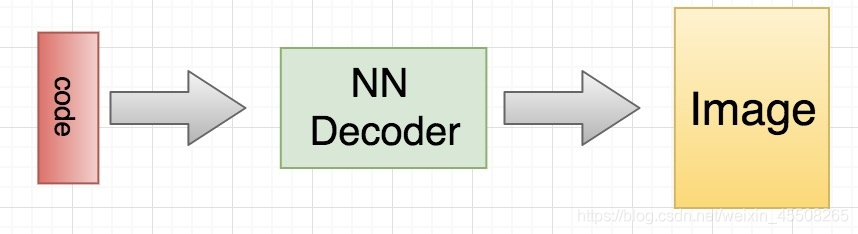
下面我们使用 mnist 数据集来说明一个如何构建一个简单的自动编码器
数据预处理
首先进行数据预处理和迭代器的构建
im_tfs = tfs.Compose([
tfs.ToTensor(),
tfs.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 标准化
])
train_set = MNIST('./mnist', transform=im_tfs, download = True)
train_data = DataLoader(train_set, batch_size=128, shuffle=True)
定义网络
# 定义网络
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(True),
nn.Linear(128, 64),
nn.ReLU(True),
nn.Linear(64, 12),
nn.ReLU(True),
nn.Linear(12, 3) # 输出的 code 是 3 维,便于可视化
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(True),
nn.Linear(12, 64),
nn.ReLU(True),
nn.Linear(64, 128),
nn.ReLU(True),
nn.Linear(128, 28*28),
nn.Tanh()
)
def forward(self, x):
encode = self.encoder(x)
decode = self.decoder(encode)
return encode, decode
这里定义的编码器和解码器都是 4 层神经网络作为模型,中间使用 relu 激活函数,最后输出的 code 是三维,注意解码器最后我们使用 tanh 作为激活函数,因为输入图片标准化在 -1 ~ 1 之间,所以输出也要在 -1 ~ 1 这个范围内,最后我们可以验证一下
net = autoencoder()
x = torch.randn(1, 28*28) # batch size 是 1
code, _ = net(x)
print(code.shape)
torch.Size([1, 3])
可以看到最后得到的 code 就是三维的
criterion = nn.MSELoss(size_average=False)
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
def to_img(x):
'''
定义一个函数将最后的结果转换回图片
'''
x = 0.5 * (x + 1.)
x = x.clamp(0, 1)
x = x.view(x.shape[0], 1, 28, 28)
return x
开始训练
# 开始训练自动编码器
for e in range(100):
for im, _ in train_data:
im = im.view(im.shape[0], -1)
im = Variable(im)
# 前向传播
_, output = net(im)
loss = criterion(output, im) / im.shape[0] # 平均
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e+1) % 20 == 0: # 每 20 次,将生成的图片保存一下
print('epoch: {}, Loss: {:.4f}'.format(e + 1, loss.data[0]))
pic = to_img(output.cpu().data)
if not os.path.exists('./simple_autoencoder'):
os.mkdir('./simple_autoencoder')
save_image(pic, './simple_autoencoder/image_{}.png'.format(e + 1))
训练完成之后我们可以看看生成的图片效果

可以看出,图片还是具有较好的清晰度
可视化
我们可以将编码的分布可视化出来,具体看看随机给一个三维的编码,能够生成图片的分布
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inline
# 可视化结果
view_data = (train_set.train_data[:200].type(torch.FloatTensor).view(-1, 28*28) / 255. - 0.5) / 0.5
view_data = view_data.to(device)
encode, _ = net(view_data) # 提取压缩的特征值
fig = plt.figure(2)
ax = Axes3D(fig) # 3D 图
# x, y, z 的数据值
X = encode.data[:, 0].cpu().numpy()
Y = encode.data[:, 1].cpu().numpy()
Z = encode.data[:, 2].cpu().numpy()
values = train_set.train_labels[:200].numpy() # 标签值
for x, y, z, s in zip(X, Y, Z, values):
c = cm.rainbow(int(255*s/9)) # 上色
ax.text(x, y, z, s, backgroundcolor=c) # 标位子
ax.set_xlim(X.min(), X.max())
ax.set_ylim(Y.min(), Y.max())
ax.set_zlim(Z.min(), Z.max())
plt.show()
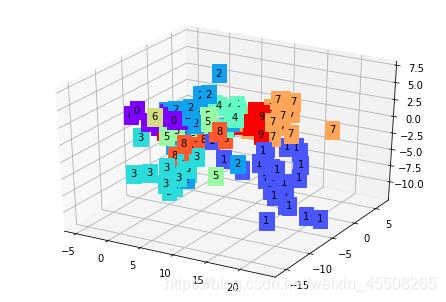
可以看到,不同种类的图片进入自动编码器之后会被编码得不同,而相同类型的图片经过自动编码之后的编码在几何示意图上距离较近,在训练好自动编码器之后,我们可以给一个随机的 code,通过 decoder 生成图片
code = torch.FloatTensor([[1.19, -3.36, 2.06]]) # 给一个 code 是 (1.19, -3.36, 2.06)
decode = net.decoder(code.to(device))
decode_img = to_img(decode).squeeze()
decode_img = decode_img.data.cpu().numpy() * 255
plt.imshow(decode_img.astype('uint8'), cmap='gray') # 生成图片 3

这里我们仅仅使用多层神经网络定义了一个自动编码器,当然你会想到,为什么不使用效果更好的卷积神经网络呢?我们当然可以使用卷积神经网络来定义,下面我们就重新定义一个卷积神经网络来进行 autoencoder
卷积神经网络 Autoencoder
class conv_autoencoder(nn.Module):
def __init__(self):
super(conv_autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, stride=3, padding=1), # (b, 16, 10, 10)
nn.ReLU(True),
nn.MaxPool2d(2, stride=2), # (b, 16, 5, 5)
nn.Conv2d(16, 8, 3, stride=2, padding=1), # (b, 8, 3, 3)
nn.ReLU(True),
nn.MaxPool2d(2, stride=1) # (b, 8, 2, 2)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 16, 3, stride=2), # (b, 16, 5, 5)
nn.ReLU(True),
nn.ConvTranspose2d(16, 8, 5, stride=3, padding=1), # (b, 8, 15, 15)
nn.ReLU(True),
nn.ConvTranspose2d(8, 1, 2, stride=2, padding=1), # (b, 1, 28, 28)
nn.Tanh()
)
def forward(self, x):
encode = self.encoder(x)
decode = self.decoder(encode)
return encode, decode
conv_net = conv_autoencoder()
if torch.cuda.is_available():
conv_net = conv_net.cuda()
optimizer = torch.optim.Adam(conv_net.parameters(), lr=1e-3, weight_decay=1e-5)
对于卷积网络中,我们可以对输入进行上采样,那么对于卷积神经网络,我们可以使用转置卷积进行这个操作,在 pytorch 中使用转置卷积就是上面的操作,torch.nn.ConvTranspose2d() 就可以了,可以在某种意义上看成是反卷积。
# 开始训练自动编码器
for e in range(40):
for im, _ in train_data:
if torch.cuda.is_available():
im = im.cuda()
# 前向传播
_, output = conv_net(im)
loss = criterion(output, im) / im.shape[0] # 平均
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e+1) % 20 == 0: # 每 20 次,将生成的图片保存一下
print('epoch: {}, Loss: {:.4f}'.format(e+1, loss.data))
pic = to_img(output.cpu().data)
if not os.path.exists('./conv_autoencoder'):
os.mkdir('./conv_autoencoder')
save_image(pic, './conv_autoencoder/image_{}.png'.format(e+1))
epoch: 20, Loss: 70.8879 epoch: 40, Loss: 74.8522
最后我们看看结果

跟前面的相比,两者的区别其实并不大,只不过多层感知机的结果会稍微模糊一些
以上是关于AutoEncoder的主要内容,如果未能解决你的问题,请参考以下文章