从Hadoop HA到Zookeeper到Kafka(了解篇)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从Hadoop HA到Zookeeper到Kafka(了解篇)相关的知识,希望对你有一定的参考价值。
Kafka基于Zookeeper协调的分布式日志系统,可以当做MQ。主要就是做:日志收集系统、消息系统。
还有就是用于用户活动跟踪:记录web用户或者app用户的各种活动,相信大家都感受到了吧。
上篇我们已经提到,消息系统的两种传递模式:点对点、订阅/发布。这里将不再赘述。
【对比】
| 名称 | Column 2 |
|---|---|
| RabbitMQ | 使用Erlang编写的一个开源的消息队列,适合企业级的开发,同时实现了Broker构架,对路由、负载均衡或者数据持久化都有很好的支持 |
| Redis | 基于Key-value的Nosql数据库,本身也支持MQ功能,可以当做轻量级的队列服务来使用。 |
| ZeroMQ | 据说是最快的消息队列系统,针对大吞吐量的需求场景,能够实现RabbitMQ不擅长的高级、复杂的队列,但是技术上比较难一点 |
| ActiveMQ | 这个咱们上篇文章已经初步探究了一下,是Apache下的一个子项目,类似ZeroMQ,能够代理任何点对点的技术实现队列;同时,类似RabbitMQ以少量的代码高效的实现更高级的应用。 |
| Kafka/Jafka | KafKa也是Apache下的一个子项目,是一个高性能的跨语言分布式发布/订阅消息队列系统。kafka相对于ActiveMQ是一个非常轻量级的消息系统,还是一个良好的分布式系统。Jafka是kafka演化而来的。 |
【为了搭建kafka,这里得先拓展一下zookeeper安装】
问, 为什么要安装Zookeeper呢?
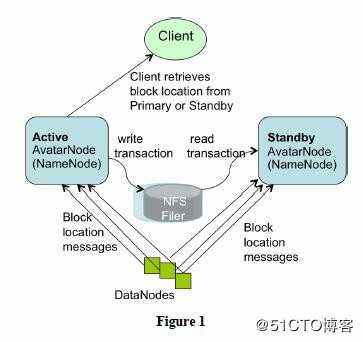
答:在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SPOF:A Single Point of Failure)。 对于只有一个 NameNode 的集群,如果 NameNode 机器出现故障(比如宕机或是软件、硬件 升级),那么整个集群将无法使用,直到 NameNode 重新启动。
HDFS 的 HA 功能通过配置 Active/Standby 两个 NameNodes 实现在集群中对 NameNode 的 热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方 式将 NameNode 很快的切换到另外一台机器。
在典型HA集群中,使用两台单独的机器配置未NameNodes。任意时间点,确保NameNodes中只有一个出去Active状态,其他处在等待状态。其中ActiveNameNode负责集群中的所有客户端操作,StandbyNameNode充当备机,主程序出现问题是能够快速的切换。
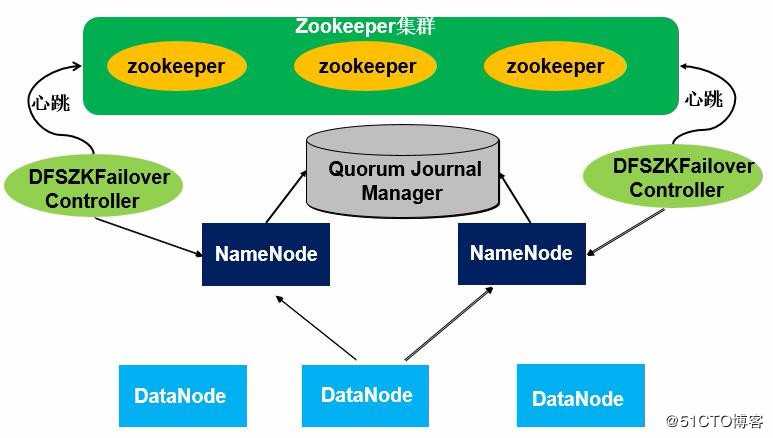
为实现同步Active【激活】与Standby【等待】两个NameNode的元数据信息需要一个共享存储系统,这个系统可以是NFS、QJM或者是Zookeeper。为了实现快速切换, Standby 节点获取集群的最新文件块信息也是很有必要的。为了实现这一目标,DataNode 需 要配置 NameNodes 的位置,并同时给他们发送文件块信息以及心跳检测。
参考:《ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群 》
【集群】
Hadoop的HA集群的搭建依赖于Zookeeper。因此这里先拓展一下Zookeeper的安装。
【PS,鉴于我这里只有一个虚拟机,因此Zookeeper和Hadoop我都不安装了。以后用到再学吧,并不是我懒啊(或许是真的懒)。】
以上是关于从Hadoop HA到Zookeeper到Kafka(了解篇)的主要内容,如果未能解决你的问题,请参考以下文章
(超详细)基于Zookeeper的Hadoop HA集群的搭建
Hadoop HA + HBase环境搭建————zookeeper和hadoop环境搭建