怎样给访问量过大的mysql数据库减压
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了怎样给访问量过大的mysql数据库减压相关的知识,希望对你有一定的参考价值。
单机mysql数据库的优化一、服务器硬件对MySQL性能的影响
①磁盘寻道能力(磁盘I/O),我们现在上的都是SAS15000转的硬盘。MySQL每秒钟都在进行大量、复杂的查询操作,对磁盘的读写量可想而知。
所以,通常认为磁盘I/O是制约MySQL性能的最大因素之一,对于日均访
问量在100万PV以上的Discuz!论坛,由于磁盘I/O的制约,MySQL的性能会非常低下!解决这一制约因素可以考虑以下几种解决方案:
使用RAID1+0磁盘阵列,注意不要尝试使用RAID-5,MySQL在RAID-5磁盘阵列上的效率不会像你期待的那样快。
②CPU 对于MySQL应用,推荐使用DELL R710,E5620 @2.40GHz(4 core)* 2 ,我现在比较喜欢DELL R710,也在用其作Linuxakg 虚拟化应用;
③物理内存对于一台使用MySQL的Database Server来说,服务器内存建议不要小于2GB,推荐使用4GB以上的物理内存,不过内存对于现在的服务器而言可以说是一个可以忽略的问题,工作中遇到高端服务器基本上内存都超过了32G。
我们工作中用得比较多的数据库服务器是HP DL580G5和DELL R710,稳定性和性能都不错;特别是DELL R710,我发现许多同行都是采用它作数据库的服务器,所以重点推荐下。
二、MySQL的线上安装我建议采取编译安装的方法,这样性能上有较大提升,服务器系统我建议用64bit的Centos5.5,源码包的编译参数会默
认以Debgu模式生成二进制代码,而Debug模式给MySQL带来的性能损失是比较大的,所以当我们编译准备安装的产品代码时,一定不要忘记使用“—
without-debug”参数禁用Debug模式。而如果把—with-mysqld-ldflags和—with-client-ldflags二
个编译参数设置为—all-static的话,可以告诉编译器以静态方式编译和编译结果代码得到最高的性能。使用静态编译和使用动态编译的代码相比,性能
差距可能会达到5%至10%之多。我参考了简朝阳先生的编译参数,特列如下,供大家参考
./configure
–prefix=/usr/local/mysql –without-debug –without-bench
–enable-thread-safe-client –enable-assembler –enable-profiling
–with-mysqld-ldflags=-all-static –with-client-ldflags=-all-static
–with-charset=latin1 –with-extra-charset=utf8,gbk –with-innodb
–with-csv-storage-engine –with-federated-storage-engine
–with-mysqld-user=mysql –without-我是怎么了ded-server
–with-server-suffix=-community
–with-unix-socket-path=/usr/local/mysql/sock/mysql.sock
三、MySQL自身因素当解决了上述服务器硬件制约因素后,让我们看看MySQL自身的优化是如何操作的。对 MySQL自身的优化主要是对其配置文件my.cnf中的各项参数进行优化调整。下面我们介绍一些对性能影响较大的参数。
下面,我们根据以上硬件配置结合一份已经优化好的my.cnf进行说明:
#vim /etc/my.cnf
以下只列出my.cnf文件中[mysqld]段落中的内容,其他段落内容对MySQL运行性能影响甚微,因而姑且忽略。
[mysqld]
port = 3306
serverid = 1
socket = /tmp/mysql.sock
skip-locking
#避免MySQL的外部锁定,减少出错几率增强稳定性。
skip-name-resolve
#禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求!
back_log = 384
#back_log参数的值指出在MySQL暂时停止响应新请求之前的短时间内多少个请求可以被存在堆栈中。
如果系统在一个短时间内有很多连接,则需要增大该参数的值,该参数值指定到来的TCP/IP连接的侦听队列的大小。不同的操作系统在这个队列大小上有它自
己的限制。 试图设定back_log高于你的操作系统的限制将是无效的。默认值为50。对于Linux系统推荐设置为小于512的整数。
key_buffer_size = 384M
#key_buffer_size指定用于索引的缓冲区大小,增加它可得到更好的索引处理性能。对于内存在4GB左右的服务器该参数可设置为256M或384M。注意:该参数值设置的过大反而会是服务器整体效率降低!
max_allowed_packet = 4M
thread_stack = 256K
table_cache = 614K
sort_buffer_size = 6M
#查询排序时所能使用的缓冲区大小。注意:该参数对应的分配内存是每连接独占,如果有100个连接,那么实际分配的总共排序缓冲区大小为100 × 6 = 600MB。所以,对于内存在4GB左右的服务器推荐设置为6-8M。
read_buffer_size = 4M
#读查询操作所能使用的缓冲区大小。和sort_buffer_size一样,该参数对应的分配内存也是每连接独享。
join_buffer_size = 8M
#联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每连接独享。
myisam_sort_buffer_size = 64M
table_cache = 512
thread_cache_size = 64
query_cache_size = 64M
#指定MySQL查询缓冲区的大小。可以通过在MySQL控制台观察,如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不
够
的情况;如果Qcache_hits的值非常大,则表明查询缓冲使用非常频繁,如果该值较小反而会影响效率,那么可以考虑不用查询缓
冲;Qcache_free_blocks,如果该值非常大,则表明缓冲区中碎片很多。
tmp_table_size = 256M
max_connections = 768
#指定MySQL允许的最大连接进程数。如果在访问论坛时经常出现Too Many Connections的错误提 示,则需要增大该参数值。
max_connect_errors = 1000
wait_timeout = 10
#指定一个请求的最大连接时间,对于4GB左右内存的服务器可以设置为5-10。
thread_concurrency = 8
#该参数取值为服务器逻辑CPU数量*2,在本例中,服务器有2颗物理CPU,而每颗物理CPU又支持H.T超线程,所以实际取值为4*2=8;这个目前也是双四核主流服务器配置。
skip-networking
#开启该选项可以彻底关闭MySQL的TCP/IP连接方式,如果WEB服务器是以远程连接的方式访问MySQL数据库服务器则不要开启该选项!否则将无法正常连接!
table_cache=1024
#物理内存越大,设置就越大。默认为2402,调到512-1024最佳
innodb_additional_mem_pool_size=4M
#默认为2M
innodb_flush_log_at_trx_commit=1
#设置为0就是等到innodb_log_buffer_size列队满后再统一储存,默认为1
innodb_log_buffer_size=2M
#默认为1M
innodb_thread_concurrency=8
#你的服务器CPU有几个就设置为几,建议用默认一般为8
key_buffer_size=256M
#默认为218,调到128最佳
tmp_table_size=64M
#默认为16M,调到64-256最挂
read_buffer_size=4M
#默认为64K
read_rnd_buffer_size=16M
#默认为256K
sort_buffer_size=32M
#默认为256K
thread_cache_size=120
#默认为60
query_cache_size=32M
※值得注意的是:
很多情况需要具体情况具体分析
一、如果Key_reads太大,则应该把my.cnf中Key_buffer_size变大,保持Key_reads/Key_read_requests至少1/100以上,越小越好。
二、如果Qcache_lowmem_prunes很大,就要增加Query_cache_size的值。
很多时候我们发现,通过参数设置进行性能优化所带来的性能提升,可能并不如许多人想象的那样产生质的飞跃,除非是之前的设置存在严重不合理的情况。我们
不能将性能调优完全依托于通过DBA在数据库上线后进行的参数调整,而应该在系统设计和开发阶段就尽可能减少性能问题。
【51CTO独家特稿】如果单MySQL的优化始终还是顶不住压力时,这个时候我们就必须考虑MySQL的高可用架构(很多同学也爱说成是MySQL集群)了,目前可行的方案有:
一、MySQL Cluster
优势:可用性非常高,性能非常好。每份数据至少可在不同主机存一份拷贝,且冗余数据拷贝实时同步。但它的维护非常复杂,存在部分Bug,目前还不适合比较核心的线上系统,所以这个我不推荐。
二、DRBD磁盘网络镜像方案
优势:软件功能强大,数据可在底层快设备级别跨物理主机镜像,且可根据性能和可靠性要求配置不同级别的同步。IO操作保持顺序,可满足数据库对数据一致
性的苛刻要求。但非分布式文件系统环境无法支持镜像数据同时可见,性能和可靠性两者相互矛盾,无法适用于性能和可靠性要求都比较苛刻的环境,维护成本高于
MySQL Replication。另外,DRBD也是官方推荐的可用于MySQL高可用方案之一,所以这个大家可根据实际环境来考虑是否部署。
三、MySQL Replication
在实际应用场景中,MySQL
Replication是使用最为广泛的一种提高系统扩展性的设计手段。众多的MySQL使用者通过Replication功能提升系统的扩展性后,通过
简单的增加价格低廉的硬件设备成倍
甚至成数量级地提高了原有系统的性能,是广大MySQL中低端使用者非常喜欢的功能之一,也是许多MySQL使用者选择MySQL最为重要的原因。
比较常规的MySQL Replication架构也有好几种,这里分别简单说明下
MySQL Replication架构一:常规复制架构--Master-slaves,是由一个Master复制到一个或多个Salve的架构模式,主要用于读压力大的应用数据库端廉价扩展解决方案,读写分离,Master主要负责写方面的压力。
MySQL Replication架构二:级联复制架构,即Master-Slaves-Slaves,这个也是为了防止Slaves的读压力过大,而配置一层二级 Slaves,很容易解决Master端因为附属slave太多而成为瓶劲的风险。
MySQL Replication架构三:Dual Master与级联复制结合架构,即Master-Master-Slaves,最大的好处是既可以避免主Master的写操作受到Slave集群的复制带来的影响,而且保证了主Master的单点故障。
以上就是比较常见的MySQL replication架构方案,大家可根据自己公司的具体环境来设计 ,Mysql 负载均衡可考虑用LVS或Haproxy来做,高可用HA软件我推荐Heartbeat。
MySQL
Replication的不足:如果Master主机硬件故障无法恢复,则可能造成部分未传送到slave端的数据丢失。所以大家应该根据自己目前的网络
规划,选择自己合理的Mysql架构方案,跟自己的MySQL
DBA和程序员多沟涌,多备份(备份我至少会做到本地和异地双备份),多测试,数据的事是最大的事,出不得半点差错 参考技术A
以MySQL为例,碎片的存在十分影响性能
MySQL 的碎片是 MySQL 运维过程中比较常见的问题,碎片的存在十分影响数据库的性能,本文将对 MySQL 碎片进行一次讲解。
判断方法:
MySQL 的碎片是否产生,通过查看
show table status from table_nameG;
这个命令中 Data_free 字段,如果该字段不为 0,则产生了数据碎片。
产生的原因:
1. 经常进行 delete 操作
经常进行 delete 操作,产生空白空间,如果进行新的插入操作,MySQL将尝试利用这些留空的区域,但仍然无法将其彻底占用,久而久之就产生了碎片;
演示:
创建一张表,往里面插入数据,进行一个带有 where 条件或者 limit 的 delete 操作,删除前后对比一下 Data_free 的变化。
删除前:

删除后:
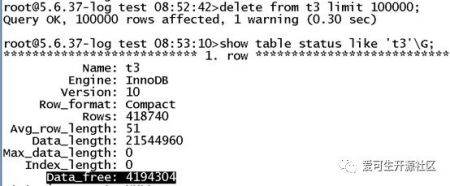
Data_free 不为 0,说明有碎片;
2. update 更新
update 更新可变长度的字段(例如 varchar 类型),将长的字符串更新成短的。之前存储的内容长,后来存储是短的,即使后来插入新数据,那么有一些空白区域还是没能有效利用的。
演示:
创建一张表,往里面插入一条数据,进行一个 update 操作,前后对比一下 Data_free 的变化。
CREATE TABLE `t1` ( `k` varchar(3000) DEFAULT NULL ) ENGINE=MyISAM DEFAULT CHARSET=utf8;
更新语句:update t1 set k='aaa';
更新前长度:223 Data_free:0
更新后长度:3 Data_free:204
Data_free 不为 0,说明有碎片;
产生影响:
1. 由于碎片空间是不连续的,导致这些空间不能充分被利用;
2. 由于碎片的存在,导致数据库的磁盘 I/O 操作变成离散随机读写,加重了磁盘 I/O 的负担。
清理办法:
MyISAM:optimize table 表名;(OPTIMIZE 可以整理数据文件,并重排索引)
Innodb:
1. ALTER TABLE tablename ENGINE=InnoDB;(重建表存储引擎,重新组织数据)
2. 进行一次数据的导入导出
碎片清理的性能对比:
引用我之前一个生产库的数据,对比一下清理前后的差异。
SQL执行速度:
select count(*) from test.twitter_11;
修改前:1 row in set (7.37 sec)
修改后:1 row in set (1.28 sec)
结论:
通过对比,可以看到碎片清理前后,节省了很多空间,SQL执行效率更快。所以,在日常运维工作中,应对碎片进行定期清理,保证数据库有稳定的性能。
MySQL Insert数据量过大导致报错 MySQL server has gone away
接手了同事的项目,其中有一个功能是保存邮件模板(包含图片),同事之前的做法是把图片进行base64编码然后存在mysql数据库中(字段类型为mediumtext)
然后保存三张图片(大概400k)的时候报错
MySQL server has gone away
然后查看官方文档https://dev.mysql.com/doc/ref...
得知可能是以下几个原因
服务器超时
服务器断开
向服务器发送不正确或太大的查询
INSERT或者 REPLACE是插入大量行
开始以为是服务器超时导致的,在网上搜的解决办法(好吧,先试一下 ,发现还是不行):
<?php
$dbh = new PDO('mysql:host=localhost;dbname=test', $user, $pass, array(
PDO::ATTR_PERSISTENT => true
));
?>
Note:
如果想使用持久连接,必须在传递给 PDO 构造函数的驱动选项数组中设置 PDO::ATTR_PERSISTENT 。如果是在对象初始化之后用 PDO::setAttribute() 设置此属性,则驱动程序将不会使用持久连接。
直接在Navicat上执行sql语句,报错 [Err] 1153 - Got a packet bigger than ‘max_allowed_packet‘ bytes
搜索得知:当MySQL客户端或mysqld服务器收到大于max_allowed_packet字节的信息包时,将发出“信息包过大”错误,并关闭连接。对于某些客户端,如果通信信息包过大,在执行查询期间,可能会遇到“丢失与MySQL服务器的连接”错误。
客户端和服务器均有自己的max_allowed_packet变量,因此,如你打算处理大的信息包,必须增加客户端和服务器上的该变量。一般情况下,服务器默认max-allowed-packet为1MB
这下问题精确定位了,就是max_allowed_packet配置的问题,
查一下配置 show VARIABLES like ‘%max_allowed_packet%‘; 发现是1048576(1024*1024),也就是1MB,
但是我的图片才400K,不应该啊,然后网上一查:Base64-encoded 数据要比原始数据多占用 33% 左右的空间。
还是不确定,直接strlen()返回base64字符串长度1451334,utf8编码下英文字符1字符占1字节,所以base64编码后是1451334B(这个是我自己的理解),大于1MB
修改max_allowed_packet配置 set global max_allowed_packet = 410241024;
发现问题完美解决
原文地址:https://segmentfault.com/a/1190000015934052
以上是关于怎样给访问量过大的mysql数据库减压的主要内容,如果未能解决你的问题,请参考以下文章