NoSQL
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NoSQL相关的知识,希望对你有一定的参考价值。
NoSQL
1 SQL
结构化的查询语言。SQL经常会用在我们的关系型数据库中(mysql/oracle/sql server/db2)。譬如我们之前使用的DDL/DML/DQL/DCL..
2 为什么要学习NOSQL
非结构化的查询语言。NOSQL经常会用在我们的非关系型的数据中。
谈一谈这个东西 “互联网”。
特点: 多样化、数据量激增、实时变化、……………….
在这样子的一种互联网的背景下,对于我们的软件来讲,它要求我们软件具有 高并发。多样性,还要能够进行海量的数据处理。这个时候我们就要思考我们的项目,具不具备高并发,多样性,还有海量的数据库处理能力? 如果我们的项目不满足当中的需求,这个时候我们就要优化或者重构我们的项目的架构。
我们就必须了解我们的互联网的机构:
阿里巴巴第一代产品,他的项目架构LAMP(Linux + Apache + Mybatis +php)
2.1 单一的msql数据库
了解下当前我们项目的架构: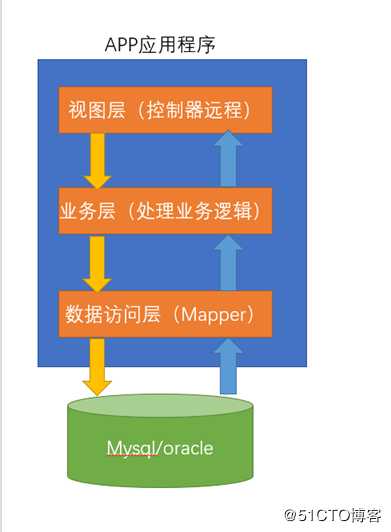
分析一下:
优点: 方便,搭建容易。
缺点: 1.仓库的容器有限。2.数据的总量在不断的增加,那么一台数据库很明显不能满足我们需求。3.这个数据我们既可以读,也可以写。这个时候对数据库的读写性能有要求了。
4.当仓库中的数据量比较多情况下,对数据库中的数据进行分类存放。分类存放之后,为了方便别人去快速的读取我们的数据。这个时候我们的数据库通常会创建索引(B+TREE),方便查询的速度,问题是,你创建了索引拿你就要开辟空间来保存索引,本身空间就有限。你还要对索引进行维护,也要消耗我们数据库的性能。
总结:我们上面的这种架构只能说是“自娱自乐”。满足不了大并发,多样性,海量数据的需求。
2.2 Memcached(缓存) + mysql + 垂直拆分
随着我们数据量的不断的增加,我们所有的上面架构的网站,都会开始出现性能下降的问题。
为了改善当前的状态,提升系统的性能。程序员就开始思索,我能不能不把所有的数据都放在数据库中,或者,我能不能把不经常发生改变的数据,第一次从数据库中取出来之后,我就放入到一个文件中。第二次在去访问的时候,我们就直接从文件中去取数据,这样子一来,数据库的性能就有一定的改善。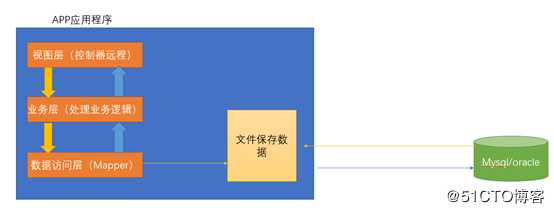
但是呢这种架构存在问题。文件不能进行共享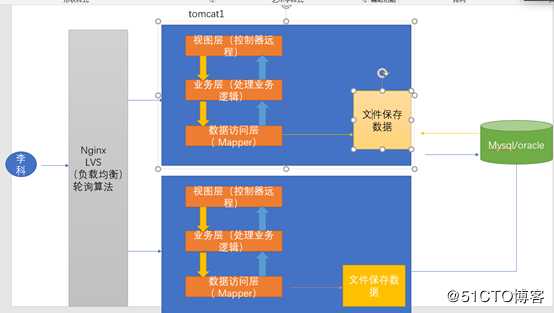
我们就要想办法让文件中的数据进行数据的共享。会使用一个分布式的缓存框架,这个缓存框架就叫做memechached./ehcache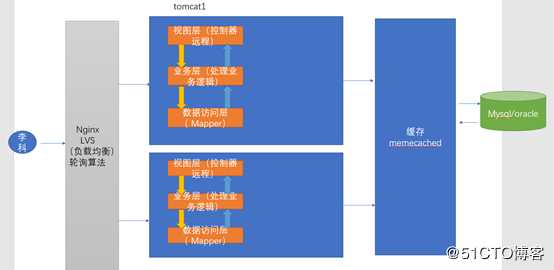
我所有的数据都保存到了一个数据库中,所以数据库的存储压力非常的大,这个时候我们就可以进行垂直拆分,我们对数据库进行拆分。譬如我们电子商务网站,按照我们业务模块分析,可以分成我们卖家和买家,也可以分成我们的商品,订单,支付,库存….等等模块。
我们就把以前所有的信息都保存到一个数据库中,现在我把这个数据库拆分成买家库和买家库,和商品库,订单库,支付库……………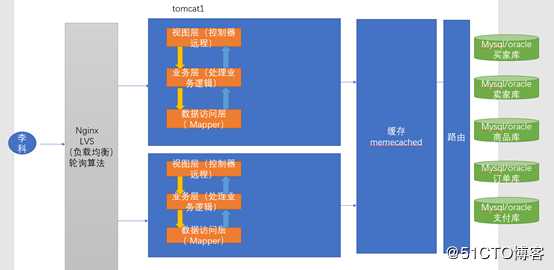
2.3 Mysql的主从复制和读写分离
随着我们数据量爆炸式的增,譬如我们双十一的那一天,我们系统的并发量非常的大,卖家库承受的鸭梨非常大。这个时候为了缓解我们卖家库的压力,因此我们可以采用主从复制,读写分离这样子的一种思想。
我们发现买家库既要读数据也要写数据,因此它的性能会受到一定影响,因此我们为了解决这样子的一个问题。我们就新增两个数据库,现在总共有买家库有了三个,一个主库,和二个从库,主库负责写数据,从库负责读数据。这就是,读写分离。。。。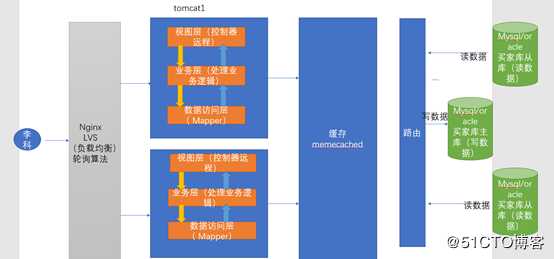
总结一下,为什么至少要两个从库。两个从库的目的是如果,有一个从库宕机,另外一个从库还能用。如果我的主库也宕机了。这个时候还能写吗?为了系统容灾备份。保证数据的完整性,以及缓存数据的一致性。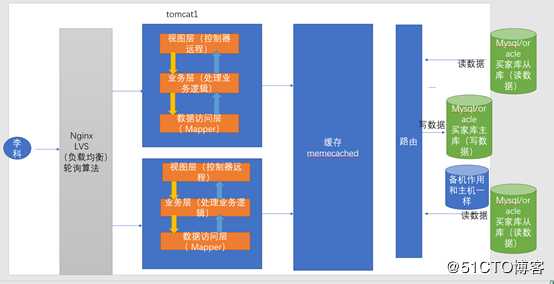
为了保持数据的一致性,因此我们就采用了另外的一种方案。叫做主从复制。。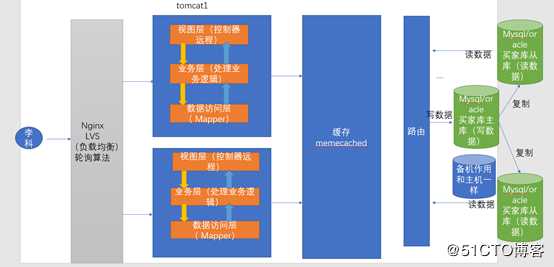
2.4 分库分表+水平拆分+mysql集群
双十一那一天,数据库非常非常的大,在同一秒中,数据的并发可能会达到几万甚至是十几万此,很明显,如果我们采用上面这种架构的化,还是不能满足我们学习,那么这个时候,我们又要改善我们数据库这一块的架构。一个满足不了我们的需求,我们搞一群这样子的东西来满足我们需求,我们就称之为mysql的集群。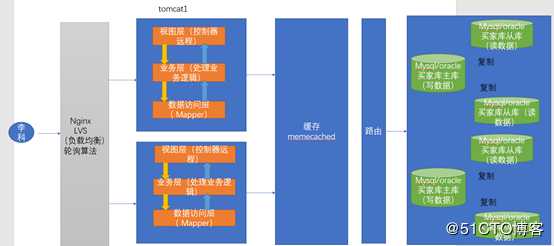
分表指的是,我们知道表是数据库中用来保存数据的地方。表自生有容量大小,通常情况下,如果表中的数据达到了500万行数据的化,这个表就已经很大了。这个时候我们在用select 去查询数据库,会要等待很长的时间。所以我们通常在做设计的时候譬如我们1亿条用户数据的话。以前我们把这1亿3条数据都保存到了用户表中,这个时候你要从这里面查询zhangsan这个用户话,时间非常的长。这个时候我们通常会这样子做:我们就做三个表,分别是user1,user2,user3 然后user1保存索引为0 到3千万的数据 user1就保存3千万到6千万的数据,user3就保存6千万到我们1亿的数据,这个时候我要查询时候,你譬如我要查询索引为2千万,这个时候我们就去user1这个表中去查询数据。也就是说,user1,user2,user3这三个表可以在同一个库中,也可能不在同一个库中。
分析这样子的一个问题:
主库在复制数据到从库的过程,这个时候有人从,从库去读取数据,这个时候会不会造成数据的不一致的问题?
譬如早期的数据采用的myISAM这样子的数据库引擎,而这样子的数据库的引擎,它采用的是表锁的概念。主库在复制数据到表中的时候,它会给这个表上一把锁。别人就读不了了。但是这样子做效率是不高。
后期为了提升数据库本省的效率,后面数据库的引擎变成INNODB引擎,而这个引擎采用的是行锁,行锁通常之锁定一行数据。
结论:能不能避免数据的完全一致,不能。只能做到相对一致。
2.5 Mysql数据的瓶颈
我们知道mysql是关系型的数据库,它采用的是sql(结构化的查询语言)来进行数据库的操作。你譬如说创建一个库,创建一张表。你譬如说创建一个库,用来保存学生信息的话,我们经常会在这个库中,创建一个学生表(students)来保存学生的信息。
但是如果说,遇到下面的场景。譬如我们要求你保存 视频信息,和大文本信息到数据到数据库。如果说数据库保存了1000部小说,1000部电影。然后我们在执行select .肯定会卡死或者说等待相当长的时间。如果们能有一个保存视频,大文本的数据,问题也解决了。
遇到下面的场景:要你设计一套数据库用来描述你们生物机电院系关系。第一个设计不容器把,即使设计出来,查询也很复杂。我解决这个问题,最好的方法是不是就是画图。如果我们有保存这种图型的数据问题不就解决了。
场景:我们电商网站中,经常有用户,商品,订单详情,订单。这样子的四张表、
我要描述,某一个用户下了那些订单,每个订单上面有那些商品。设计到四张表的链表查询。如果并发量非常非常大的时候,10000个用户通是完成上述操作的话,效率非常的低。数据库的性能也非常的低。
如果我们这样子实现这样子的一种格式或者说,我们能从数据库中,读取这种格式的数据,我们问题不就解决了。
{
Username: ‘李科’,
Age: ‘19’,
Sex: ‘男’,
Orders:[
{
orderId: ‘001’,
ordertime: ‘2020-04-20’,
product: [
{
productid: 1
name: ‘篮球’,
price: 30,
num: 1
}
]
}
]
}
总结一下,我们刚刚所说的几个场景,很明显,关系型的数据库,不能解决上面的问题。
所以为了解决上面的问题,我们就引入非关系型数据库的学习。所以我们为了解决上面的问题,我们就要学习NOSQL数据库。
作业:
http://try.redis.io/ 这是在线的工具
http://www.redis.cn/ 中文网址
以上是关于NoSQL的主要内容,如果未能解决你的问题,请参考以下文章