大数据开发这么学习?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据开发这么学习?相关的知识,希望对你有一定的参考价值。
分享大数据学习路线:
第一阶段为JAVASE+mysql+JDBC
主要学习一些Java语言的概念,如字符、bai流程控制、面向对象、进程线程、枚举反射等,学习MySQL数据库的安装卸载及相关操作,学习JDBC的实现原理以及Linux基础知识,是大数据刚入门阶段。
第二阶段为分布式理论简介
主要讲解CAP理论、数据分布方式、一致性、2PC和3PC、大数据集成架构。涉及的知识点有Consistency一致性、Availability可用性、Partition
tolerance分区容忍性、数据量分布、2PC流程、3PC流程、哈希方式、一致性哈希等。
第三阶段为数据存储与计算(离线场景)
主要讲解协调服务ZK(1T)、数据存储hdfs(2T)、数据存储alluxio(1T)、数据采集flume、数据采集logstash、数据同步Sqoop(0.5T)、数据同步datax(0.5T)、数据同步mysql-binlog(1T)、计算模型MR与DAG(1T)、hive(5T)、Impala(1T)、任务调度Azkaban、任务调度airflow等。
第四部分为数仓建设
主要讲解数仓仓库的历史背景、离线数仓项目-伴我汽车(5T)架构技术解析、多维数据模型处理kylin(3.5T)部署安装、离线数仓项目-伴我汽车升级后加入kylin进行多维分析等;
第五阶段为分布式计算引擎
主要讲解计算引擎、scala语言、spark、数据存储hbase、redis、kudu,并通过某p2p平台项目实现spark多数据源读写。
第六阶段为数据存储与计算(实时场景)
主要讲解数据通道Kafka、实时数仓druid、流式数据处理flink、SparkStreaming,并通过讲解某交通大数让你可以将知识点融会贯通。
第七阶段为数据搜索
主要讲解elasticsearch,包括全文搜索技术、ES安装操作、index、创建索引、增删改查、索引、映射、过滤等。
第八阶段为数据治理
主要讲解数据标准、数据分类、数据建模、图存储与查询、元数据、血缘与数据质量、Hive Hook、Spark Listener等。
第九阶段为BI系统
主要讲解Superset、Graphna两大技术,包括基本简介、安装、数据源创建、表操作以及数据探索分析。
第十阶段为数据挖掘
主要讲解机器学习中的数学体系、Spark Mlib机器学习算法库、Python scikit-learn机器学习算法库、机器学习结合大数据项目。
对大数据分析有兴趣的小伙伴们,不妨先从看看大数据分析书籍开始入门!B站上有很多的大数据教学视频,从基础到高级的都有,还挺不错的,知识点讲的很细致,还有完整版的学习路线图。也可以自己去看看,下载学习试试。
1、语言基础
Java:多理解和实践在Java虚拟机的内存管理、以及多线程、线程池、设计模式、并行化就可以,不需要深入掌握。
Linux:系统安装、基本命令、网络配置、Vim编辑器、进程管理、Shell脚本、虚拟机的菜单熟悉等等。
Python:基础语法,数据结构,函数,条件判断,循环等基础知识。
2、环境准备
这里介绍在windows电脑搭建完全分布式,1主2从。
VMware虚拟机、Linux系统(Centos6.5)、Hadoop安装包,这里准备好Hadoop完全分布式集群环境。
3、MapReduce
MapReduce分布式离线计算框架,是Hadoop核心编程模型。
4、HDFS1.0/2.0
HDFS能提供高吞吐量的数据访问,适合大规模数据集上的应用。
5、Yarn(Hadoop2.0)
Yarn是一个资源调度平台,主要负责给任务分配资源。
6、Hive
Hive是一个数据仓库,所有的数据都是存储在HDFS上的。使用Hive主要是写Hql。
7、Spark
Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
8、SparkStreaming
Spark Streaming是实时处理框架,数据是一批一批的处理。
9、SparkHive
Spark作为Hive的计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计算,可以提高Hive查询的性能。
10、Storm
Storm是一个实时计算框架,Storm是对实时新增的每一条数据进行处理,是一条一条的处理,可以保证数据处理的时效性。
11、Zookeeper
Zookeeper是很多大数据框架的基础,是集群的管理者。
12、Hbase
Hbase是一个Nosql数据库,是高可靠、面向列的、可伸缩的、分布式的数据库。
13、Kafka
kafka是一个消息中间件,作为一个中间缓冲层。
14、Flume
Flume常见的就是采集应用产生的日志文件中的数据,一般有两个流程。
一个是Flume采集数据存储到Kafka中,方便Storm或者SparkStreaming进行实时处理。
另一个流程是Flume采集的数据存储到HDFS上,为了后期使用hadoop或者spark进行离线处理。
第二阶段:数据挖掘算法
1、中文分词
开源分词库的离线和在线应用
2、自然语言处理
文本相关性算法
3、推荐算法
基于CB、CF,归一法,Mahout应用。
4、分类算法
NB、SVM
5、回归算法
LR、DecisionTree
6、聚类算法
层次聚类、Kmeans
7、神经网络与深度学习
NN、Tensorflow 参考技术B 首先我们要学习Java语言和Linux操作系统。
Java 只需要学习Java的标准版JavaSE就可以了;Linux因为大数据相关软件都是在Linux上运行的,所以Linux要学习的扎实一些。
下面进行大数据课程的学习,可以按照我的顺序,一步一步进行学习。
Hadoop、Zookeeper、Mysql、Sqoop、Hive、Oozie、Hbase、Kafka、Spark、Flink 参考技术C
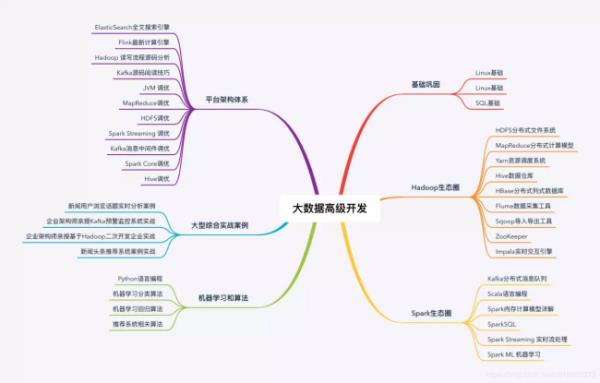
大数据思维导图
可以的话点个赞哦。
参考技术D你好,大数据开发学习的路线,按照顺序学习就是可以的,另外学习方法上就是3多,多思考、多问、多敲键盘,学习是一个重复的过程,希望你早日学有所成!

大数据开发学什么
为什么迁移学习的前景这么大?为什么PyTorch这么火?

图:pixabay
机器学习的未来是非常光明的,为什么这么讲?因为导致机器学习大发展的激励因素几乎是一致的——大厂商们热切地开源各种工具,开始在更快的硬件领域投资,改变他们原先基于广告的商业模式。那些疯狂的科学家们(tinkerers)发明出了以前闻所未闻的应用程序。私人、公共、科学、闲置和不可利用的数据,可互换性越来越高。那么我们讨论一些实际的事情吧:我们到底怎样利用最近机器学习上的提升——那些可用的、预先训练的机器学习模型呢?
与迁移学习相关的任务需要一小部分潜在的能力,来区分不可见的数据。例如,无论你弹吉他还是钢琴,你都会比没有玩过这些乐器的人更好地选择和弦。从机器学习的角度来说,这意味着你可以复制别人的训练工作,并将其快速应用到分类照片。
吴恩达曾在2016年的神经信息处理系统大会(NIPS2016)上,总结概括了机器学习的高速发展。
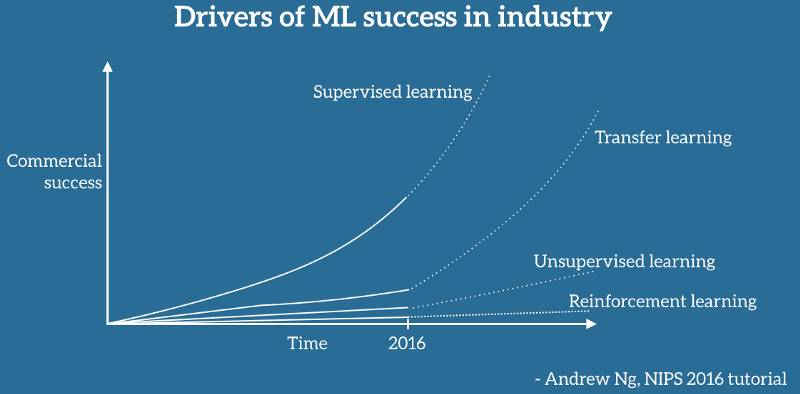
特别需要说明的是,迁移学习在决定机器学习技术的所有方面都有所改进。
人力效率:如果你想要输出最后的信号,使模型可解释,易处理,并具有鲁棒性,你需要专家。得益于学术研究,各种架构在相关任务中不断进行测试,爆炸式增长。
计算效率:目前,以最先进的论文而言,在2到8个GPU的群集上进行训练通常大约需要两周。但是,通过迁移学习,你可以节省很多调整内部参数的过程。
数据效率:如果对大数据集进行训练,在大多数情况下,需要更少域的特定数据。

迁移学习被广泛用于区分具体的图像类别。普渡大学的Alfredo Canziani和Eugenio Culurciello曾在2016年5月发表过一篇名为《深度神经网络模型实际应用分析》的论文,该论文比较了在imagenet数据集上计算时,主要架构的计算效率。
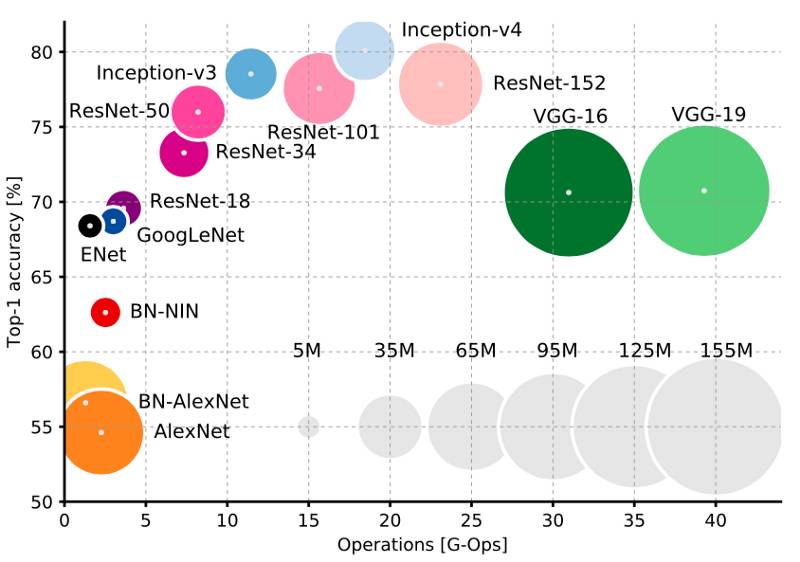
具体来说,根据你的设备限制,你可以进一步将计算成本分为训练时间、推理时间和内存需求。我们需要深入挖掘,给出非常具体的约束。
首先,新的数据经常出现;其次,这些图像也具有潜在的专有性。因此,再训练过程必须在本地的中层GPU上进行,以保证可靠性。从用户的角度来看,如果在一致的时间内给出一致的结果,再训练就是可靠的。因此,基线基准测试将使用一个简单的优化方法,有利于收敛的数据效率。再其次,每个预测需要几乎实时地发生,因此我们还要关注推理时间。最后,我们关注图像(或图像的一部分)的确切类别作为决策的输入。这样,我们将top-1 accuracy考虑在内。
现在,为了降低专家的成本,随着不断发展的数据集,将计算时间与硬性约束相适应,让我们研究一下最令人垂涎的工具之一——PyTorch。
为什么PyTorch这么火爆呢?
框架合理完整、简洁、完全在代码中定义,并易于调试。只需要添加一行代码,就可以从torchvision软件包加载6种框架:AlexNet、DenseNets、Inception、SqueezeNet和VGG。
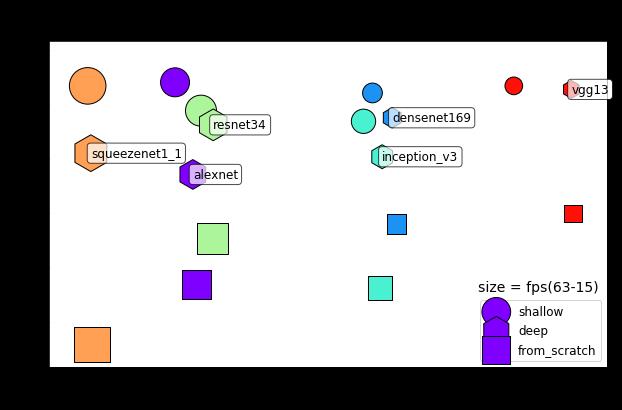
图表中的模型仅在最终层(浅),整个参数集(深)或从其初始化状态(从零开始)进行了再训练。在所有运行中,双K80 GPU大约运行在75%。
数据显示,SqueezeNet 1.1是高效的计算架构。因为想分成再训练和静态层次比较难,所以只是基于浅层再训练模型的结论太随意了。例如,VGG13的最终分类器具有8194个参数,而ResNet34的最终层比较窄,具有1026个参数。因此,只有对学习策略的超参数搜索才能使给定目标的比较真正有效。
需要注意的是,在相同训练时间下,与浅层再训练相比,深层再训练时间的精确度要低得多。在其他任务中,其他模型也遇到了相似的事情。从前一个局部最优化的角度来看,更深层次的卷积平均(小误差梯度)发生缓慢,并且在比随机初始化的情况下更不平滑。因此,参数可能最终在过渡阶段并列。如果未知的特征与原始数据不同,这种间歇性混乱应该是特别真实的,下图就是一个例子:有时候有蚂蚁靠近,有时你观察到整个蚁群。

因此,事实上,你可能会建议提高深层再训练的学习率,或者在某种程度上使用规模不变网络(scale invariant networks)。
为了评估由推理和再训练时间组成的计算效率,这是一个很好的开始。如果你想进一步提高再训练效率,你可以忽略数据增强,从未训练层中提取结果。当然,结论将会随着类别数、前面提到的其他因素,以及其他具体的限制而不同。
编译自:towards datascience
文章做了不改变原意的修改
 欢迎加入
欢迎加入
雷克大会官方预热视频
关注“机器人圈”后不要忘记置顶哟
↓↓↓点击阅读原文查看更多好内容
以上是关于大数据开发这么学习?的主要内容,如果未能解决你的问题,请参考以下文章