大数据MapReduce入门之倒排索引
Posted 大神笨蛋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据MapReduce入门之倒排索引相关的知识,希望对你有一定的参考价值。
在上一篇博客中我们讲解了MapReduce的原理以及map和reduce的作用,相信你理解了他们的原理,今天讲解的是mapreduce 的另一个就是倒排索引。
什么是倒排索引呢?倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件。
我们通过一个例子来讲解一下:
有3个文本文件,上面的内容分别为:
data01.TXT ---------I love Beijing and i love Shanghai
data02.TXT----------I love China
data03.TXT----------Beijing is the capital of China
现在我们需要统计每个文档中每个单词出现的次数,并且加上他的索引值也就是在哪个文档,想要实现的结果就是下面的形式:
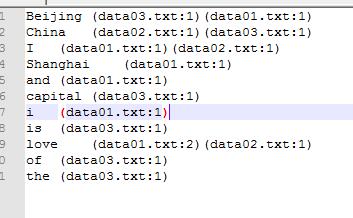
如果只是使用wordcount那种方式的话,我们来屡一下思路,按照最后的输出格式,我们肯定要将单词作为key,单词的索引(文件名)和他在文件中出现的次数作为value值,那么在map中我们的输出格式就必须为key (单词)value(文件名+次数),但是这样的话,我们就无法统计他在每个文件中出现的次数的总和,他在map中的输出格式只能是下面这种形式。
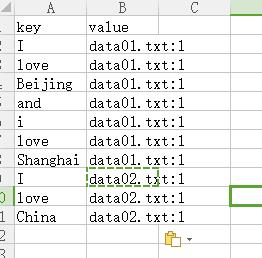
而以这种形式来在reduce中进行计算时,你只能将所有文本中相同的单词数量统计,而无法统计一个文本中单词出现的数量。最后输出的结果只能为下面这种形式。
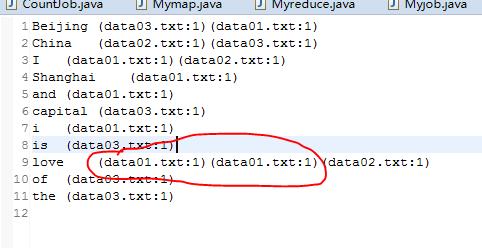
我们发现love在data01.TXT中出现了两次,可是他却分开了,这就是wordcount无法实现的功能。这是我们就需要使用倒排索引的方式,将索引值(文件名)作为key值进行提取,这里我们需要学一个新内容叫做,Combine,那么Combine的作用和原理是什么呢?Combine就是一个相当于本地结合的东西,就是在map和reduce之间,在map将内容提交给reduce时,进行本地的Key结合,将本地文件这里就是同一个文本的相同的key汇成一个块,再将这个块传给reduce。下面我们来看看具体的流程:
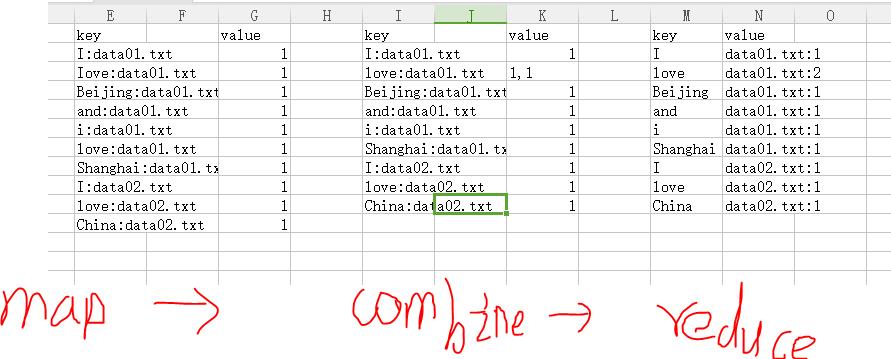
上面的就是数据的走向,下面来看看代码:
Map:
package com.zll.wordcount; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; public class WordcountMap extends Mapper<LongWritable,Text,Text,Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String s = value.toString(); String[] split = s.split(" "); InputSplit inputSplit = context.getInputSplit(); String fileName = ((FileSplit) inputSplit).getPath().toString(); String lujin = fileName.substring(fileName.lastIndexOf("/")+1); for (String str:split) { context.write(new Text(str+":"+lujin),new Text("1")); } } }
Combine:
package com.zll.wordcount; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.ArrayList; import java.util.List; public class WordcountCombine extends Reducer<Text,Text,Text,Text> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { int count=0; for (Text s1:values) { String str=s1.toString(); count=count+Integer.parseInt(s1.toString()); } String text=key.toString(); String[] split = text.split(":"); context.write(new Text(split[0]),new Text(split[1]+":"+count)); } }
Reduce:
package com.zll.wordcount; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.ArrayList; import java.util.List; public class WordcountReduce extends Reducer<Text,Text,Text,Text> { @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { String zhi=""; for (Text s1:values) { zhi=zhi+"("+s1.toString()+")"; } context.write(key,new Text(zhi)); } }
Job:
package com.zll.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class WordcountJob extends Configured implements Tool { public static void main(String[] args) { WordcountJob wordcountJob=new WordcountJob(); try { ToolRunner.run(wordcountJob, null); } catch (Exception e) { // TODO 自动生成的 catch 块 e.printStackTrace(); } } @Override public int run(String[] args) throws Exception { Configuration configuration=new Configuration(); configuration.set("fs.defaultFS","hdfs://192.168.153.11:9000"); Job job=Job.getInstance(configuration); job.setJarByClass(WordcountJob.class); job.setMapperClass(WordcountMap.class); job.setReducerClass(WordcountReduce.class); job.setCombinerClass(WordcountCombine.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); FileInputFormat.addInputPath(job,new Path("/hadoop/data")); FileOutputFormat.setOutputPath(job,new Path("/hadoop/outdata")); job.waitForCompletion(true); return 0; } }
以上是关于大数据MapReduce入门之倒排索引的主要内容,如果未能解决你的问题,请参考以下文章