MySQL
Posted JasonJI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL相关的知识,希望对你有一定的参考价值。
mysql体系结构
实例
mysqld在启动时,自动派生master thread ------>生成工作的线程(read write 资源管理 等线程)
预分配内存区域
mysqld三层结构
DML:数据操作语言
DDL:数据库对象定义语言
DCL:数据控制语言
mysql三层结构
连接层
1、提供连接协议(TCP/IP socket)
2、验证的功能
3、提供一个专门的连接线程(接收用户发来的SQL,执行完成之后返回最终结果,但是没有能力“看懂”SQL,会将SQL语句丢给下一层)
SQL层
1、接收上层发来语句
2、语法检查模块进行语法检查
3、语义的检查模块检查语义,分辨SQL语句的类型,将不同种类的语句交给不同的解析器。
4、解析器接收到SQL语句,进行解析操作,得到SQL的执行计划(explain)
5、优化器负责基于“成本”,找到消耗成本最低的执行计划。
6、执行器会基于优化器的选择,执行SQL语句,得到获取数据方法,交由下一层继续处理。
7、将二进制或者16进制数据,结构化成表
8、查询缓存:SQL语句的hash值+数据结果 ------>redis
存储引擎层
根据上层次获取数据的方法,把数据提取出来
权限管理
主机范围
10.0.0.% <----->10.0.0.1-10.0.0.254
10.0.0.5%<-----> 10.0.0.50-10.0.0.59
用户名@\'主机范围\' 主机范围被称之为白名单
grant all privileges on *.* to app@\'10.0.0.%\' identified by \'123\';
grant 权限 on 权限作用范围 to 用户 identified by \'密码\'
举例,授权给bbs项目的用户一些权限
grant create,update,insert,select ,CREATE VIEW on bbs.* to bbsuser@\'192.168.12.%\' identified by \'123\';
all privileges


SELECT, INSERT, UPDATE, DELETE, CREATE, RELOAD,
SHUTDOWN, PROCESS, FILE, REFERENCES, INDEX, ALTER,
SHOW DATABASES, SUPER, CREATE TEMPORARY TABLES, DROP
LOCK TABLES, EXECUTE, REPLICATION SLAVE, REPLICATION CLIENT,
CREATE VIEW, SHOW VIEW, CREATE ROUTINE,
ALTER ROUTINE, CREATE USER, EVENT, TRIGGER, CREATE TABLESPACE
开发可能用到的权限
create update insert select CREATE VIEW CREATE ROUTINE SHOW VIEW CREATE TEMPORARY TABLES ALTER
客户端工具中自带命令
1、\\h 或 help 或 ?
不知道某条语句如何书写时可查看完整写法,比如select语句你忘了整体结构,可以help select即可查看select完整语法结构
2、source
加载事先写好的MySQL文件,自动执行文件内的SQL操作
如何防止对数据的操作操作
使用TRIGGER触发器,在用户对数据库进行增删改的的时候自动触发,控制用户前后行为,主从复制
伪删除(灰度处理)
我们知道无论是对数据库还是数据,最好都不要轻易的删除,那么这个时候就会想到用伪删除的方式来实现相同的效果。
1.给每条数据额外增加一个status字段,用来表示该条数据的状态信息即用update替代真正的delete
2.使用中间件自动拦截来达到相同的效果即灰度处理
索引即执行计划
B树
也叫二叉搜索树,
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
这里我们需要知道的是,二分法的优缺点,优点是提高了查找效率,缺点是每一个被查找条件项被查找的概率并不相等,比如位于数据的首位项,用二分法效率就会很低,那么如何实现没想数据的查找概率都是平等的呢?下面的B+树和B*树就很好的解决了这个问题,并在范围查找方面进行了一定的优化处理

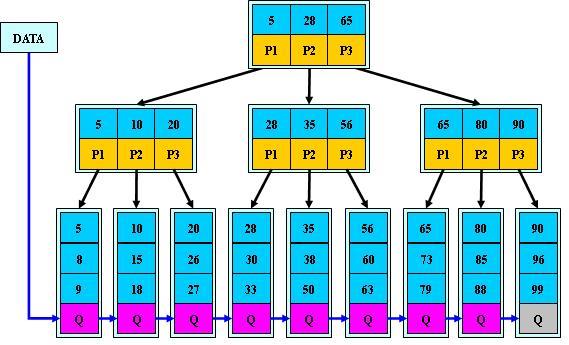
B+树
为所有叶子结点增加一个链指针,当查询语句是范围查询时,能规避掉走根节点和枝节点的消耗,直接从叶子节点的链指针走到下一行
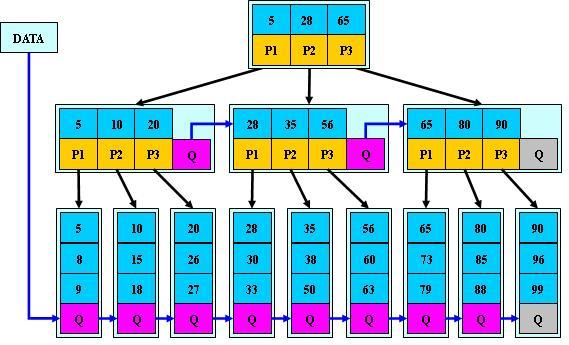
B*树
是B+的变体,在B+树的枝结点再增加指向兄弟的指针,优化范围查询
MySQL查询数据
两种方式
全表扫描、索引扫描
通过explain命令的type可以看到,ALL的话就是全表扫描。
mysql在使用全表扫描时的性能是极其差的,所以MySQL尽量避免出现全表扫描
全表扫描什么时候出现?
1、业务确实要获取所有数据
2、不走索引,导致的全表扫描
2.1 没索引
2.2 索引创建有问题
2.3 语句有问题
如何查看查询类型
索引扫描有很多种级别,也是通过explain type能看到
type : 表示MySQL在表中找到所需行的方式,又称“访问类型”
常见类型如下:
index, range, ref, eq_ref, const system, Null
从左到右,性能从最差到最好,我们认为至少要达到range级别
1、index
Full Index Scan,index与ALL区别为index类型只遍历索引树
2、range
索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行。
显而易见的索引范围扫描是带有between或者where子句里带有<,>查询。
where条件后 > < >= <= in or between and
我们在使用索引是,最低应当达到range
alter table city add index idx_popu(population); explain select * from city where population >5000000; explain select * from city where countrycode in ("CHN","JPN");
当mysql使用索引去查找一系列值时,例如IN()和OR列表,也会显示range(范围扫描),当然性能上面是有差异的。
explain select * from test where countrycode in (\'chn\',\'jpn\');
改写为:
explain select * from city where countrycode=\'chn\' union select * from city where countrycode=\'jpn\';
3、ref
使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配某个单独值的记录行
explain select * from test where countrycode=\'chn\';
4、eq_ref
类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,
就是多表连接中使用primary key或者 unique key作为关联条件
A join B
on A.sid=B.sid
5、const、system
当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。
如将主键置于where列表中,MySQL就能将该查询转换为一个常量
explain select * from city where id=1000;
6、NULL
MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,
例如从一个索引列里选取最小值可以通过单独索引查找完成。
数据库索引的设计原则
为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引。
那么索引设计原则又是怎样的?
选择唯一性索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。
例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。
如果使用姓名的话,可能存在同名现象,从而降低查询速度。
主键索引和唯一键索引,在查询中使用是效率最高的。
注意:如果重复值较多,可以考虑采用联合索引
经常需要排序、分组和联合操作的字段建立索引
经常需要ORDER BY、GROUP BY、DISTINCT和UNION等操作的字段,排序操作会浪费很多时间。
如果为其建立索引,可以有效地避免排序操作。
常作为查询条件的字段建立索引
如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此,
为这样的字段建立索引,可以提高整个表的查询速度。
3.1 经常查询
3.2 列值的重复值少
注:如果经常作为条件的列,重复值特别多,可以建立联合索引。
尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和BLOG类型的字段,进行全文检索
会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。
不走索引的情况
1) 没有查询条件,或者查询条件没有建立索引
select * from tab; 全表扫描。
select * from tab where 1=1;
(1)select * from tab;
SQL改写成以下语句:
selec * from tab order by price limit 10 需要在price列上建立索引
(2)
select * from tab where name=\'zhangsan\' name列没有索引
改:
1、换成有索引的列作为查询条件
2、将name列建立索引
2) 查询结果集是原表中的大部分数据,应该是30%以上。
查询的结果集,超过了总数行数30%,优化器觉得就没有必要走索引了。
假如:tab表 id,name id:1-100w ,id列有索引
select * from tab where id>500000;
如果业务允许,可以使用limit控制。
什么是业务: 产品的功能 + 用户的行为
怎么改写 ?
结合业务判断,有没有更好的方式。如果没有更好的改写方案
尽量不要在mysql存放这个数据了。放到redis里面。
3) 索引本身失效,统计数据不真实
索引有自我维护的能力。
对于表内容变化比较频繁的情况下,有可能会出现索引失效。
4) 查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等)
例子:
错误的例子:select * from test where id-1=9;
正确的例子:select * from test where id=10;
5)隐式转换导致索引失效
这一点应当引起重视.也是开发中经常会犯的错误.
这样会导致索引失效:
例如用户的手机号字段,你用的是varchar类型来存储,那么在以手机号为筛选条件时,手机号应该写为字符串形式,而不是数值形式,虽然两者都能得出结果,但是如果数据库里面的类型与你输入的类型不一致,mysql会帮你自动转换,但是这个自动就需要用到的函数来实现,所以就不会走索引~~~
以上是关于MySQL的主要内容,如果未能解决你的问题,请参考以下文章