返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html
1.关于ProxySQL路由的简述
当ProxySQL收到前端app发送的SQL语句后,它需要将这个SQL语句(或者重写后的SQL语句)发送给后端的mysql Server,然后收到SQL语句的MySQL Server执行查询,并将查询结果返回给ProxySQL,再由ProxySQL将结果返回给客户端(如果设置了查询缓存,则先缓存查询结果)。
ProxySQL可以实现多种方式的路由:基于ip/port、username、schema、SQL语句。其中基于SQL语句的路由是按照规则进行匹配的,匹配方式有hash高效匹配、正则匹配,还支持更复杂的链式规则匹配。
本文将简单演示基于端口、用户和schema的路由,然后再详细介绍基于SQL语句的路由规则。不过需要说明的是,本文只是入门,为后面ProxySQL的高级路由方法做铺垫。
在阅读本文之前,请确保:
- 已经理解ProxySQL的多层配置系统,可参考:ProxySQL的多层配置系统
- 会操作ProxySQL的Admin管理接口,可参考:ProxySQL的Admin管理接口
- 已经配置好了后端节点、mysql_users等。可参考:ProxySQL管理后端节点
如果想速成,可参考;ProxySQL初试读写分离
本文涉及到的实验环境如下:
| 角色 | 主机IP | server_id | 数据状态 |
|---|---|---|---|
| Proxysql | 192.168.100.21 | null | 无 |
| Master | 192.168.100.22 | 110 | 刚安装的全新MySQL实例 |
| Slave1 | 192.168.100.23 | 120 | 刚安装的全新MySQL实例 |
| Slave2 | 192.168.100.24 | 130 | 刚安装的全新MySQL实例 |
该实验环境已经在前面的文章中搭建好,本文不再赘述一大堆的内容。环境的搭建请参考前面给出的1、2、3。
2.ProxySQL基于端口的路由
我前面写了一篇通过MySQL Router实现MySQL读写分离的文章,MySQL Router实现读写分离的方式就是通过监听不同端口实现的:一个端口负责读操作,一个端口负责写操作。这样的路由逻辑非常简单,配置起来也很方便。
虽然基于端口实现读写分离配置起来非常简单,但是缺点也很明显:必须在前端app的代码中指定端口号码。这意味着MySQL的一部分流量权限被开发人员掌控了,换句话说,DBA无法全局控制MySQL的流量。此外,修改端口号时,app的代码也必须做出相应的修改。
虽说有缺点,但为了我这个ProxySQL系列文章的完整性,本文还是要简单演示ProxySQL如何基于端口实现读写分离。
首先修改ProxySQL监听SQL流量的端口号,让其监听在不同端口上。
admin> set mysql-interfaces=\'0.0.0.0:6033;0.0.0.0:6034\';
admin> save mysql variables to disk;
然后重启ProxySQL。
[root@xuexi ~]# service proxysql stop
[root@xuexi ~]# service proxysql start
[root@xuexi ~]# netstat -tnlp | grep proxysql
tcp 0 0 0.0.0.0:6032 0.0.0.0:* LISTEN 27572/proxysql
tcp 0 0 0.0.0.0:6033 0.0.0.0:* LISTEN 27572/proxysql
tcp 0 0 0.0.0.0:6034 0.0.0.0:* LISTEN 27572/proxysql
监听到不同端口,再去修改mysql_query_rules表。这个表是ProxySQL的路由规则定制表,后文会非常详细地解释该表。
例如,插入两条规则,分别监听在6033端口和6034端口,6033端口对应的hostgroup_id=10是负责写的组,6034对应的hostgroup_id=20是负责读的组。
insert into mysql_query_rules(rule_id,active,proxy_port,destination_hostgroup,apply)
values(1,1,6033,10,1), (2,1,6034,20,1);
load mysql query rules to runtime;
save mysql query rules to disk;
这样就配置结束了,是否很简单?
其实除了基于端口进行分离,还可以基于监听地址(修改字段proxy_addr即可),甚至可以基于客户端地址(修改字段client_addr字段即可,该用法可用于采集数据、数据分析等)。
无论哪种路由方式,其实都是在修改mysql_query_rules表,所以下面先解释下这个表。
3.mysql_query_rules表
可以通过show create table mysql_query_rules语句查看定义该表的语句。
下面是我整理出来的字段属性。
| COLUMN | TYPE | NULL? | DEFAULT |
|-----------------------|---------|----------|------------|
| rule_id (pk) | INTEGER | NOT NULL | |
| active | INT | NOT NULL | 0 |
| username | VARCHAR | | |
| schemaname | VARCHAR | | |
| flagIN | INT | NOT NULL | 0 |
| client_addr | VARCHAR | | |
| proxy_addr | VARCHAR | | |
| proxy_port | INT | | |
| digest | VARCHAR | | |
| match_digest | VARCHAR | | |
| match_pattern | VARCHAR | | |
| negate_match_pattern | INT | NOT NULL | 0 |
| re_modifiers | VARCHAR | | \'CASELESS\' |
| flagOUT | INT | | |
| replace_pattern | VARCHAR | | |
| destination_hostgroup | INT | | NULL |
| cache_ttl | INT | | |
| reconnect | INT | | NULL |
| timeout | INT | | |
| retries | INT | | |
| delay | INT | | |
| mirror_flagOU | INT | | |
| mirror_hostgroup | INT | | |
| error_msg | VARCHAR | | |
| sticky_conn | INT | | |
| multiplex | INT | | |
| log | INT | | |
| apply | INT | NOT NULL | 0 |
| comment | VARCHAR | | |
各个字段的意义如下:有些字段不理解也无所谓,后面会分析一部分比较重要的。
- rule_id:规则的id。规则是按照rule_id的顺序进行处理的。
- active:只有该字段值为1的规则才会加载到runtime数据结构,所以只有这些规则才会被查询处理模块处理。
- username:用户名筛选,当设置为非NULL值时,只有匹配的用户建立的连接发出的查询才会被匹配。
- schemaname:schema筛选,当设置为非NULL值时,只有当连接使用
schemaname作为默认schema时,该连接发出的查询才会被匹配。(在MariaDB/MySQL中,schemaname等价于databasename)。 - flagIN,flagOUT:这些字段允许我们创建"链式规则"(chains of rules),一个规则接一个规则。
- apply:当匹配到该规则时,立即应用该规则。
- client_addr:通过源地址进行匹配。
- proxy_addr:当流入的查询是在本地某地址上时,将匹配。
- proxy_port:当流入的查询是在本地某端口上时,将匹配。
- digest:通过digest进行匹配,digest的值在
stats_mysql_query_digest.digest中。 - match_digest:通过正则表达式匹配digest。
- match_pattern:通过正则表达式匹配查询语句的文本内容。
- negate_match_pattern:设置为1时,表示未被
match_digest或match_pattern匹配的才算被成功匹配。也就是说,相当于在这两个匹配动作前加了NOT操作符进行取反。 - re_modifiers:RE正则引擎的修饰符列表,多个修饰符使用逗号分隔。指定了
CASELESS后,将忽略大小写。指定了GLOBAL后,将替换全局(而不是第一个被匹配到的内容)。为了向后兼容,默认只启用了CASELESS修饰符。 - replace_pattern:将匹配到的内容替换为此字段值。它使用的是RE2正则引擎的Replace。注意,这是可选的,当未设置该字段,查询处理器将不会重写语句,只会缓存、路由以及设置其它参数。
- destination_hostgroup:将匹配到的查询路由到该主机组。但注意,如果用户的
transaction_persistent=1(见mysql_users表),且该用户建立的连接开启了一个事务,则这个事务内的所有语句都将路由到同一主机组,无视匹配规则。 - cache_ttl:查询结果缓存的时间长度(单位毫秒)。注意,在ProxySQL 1.1中,cache_ttl的单位是秒。
- reconnect:目前不使用该功能。
- timeout:被匹配或被重写的查询执行的最大超时时长(单位毫秒)。如果一个查询执行的时间太久(超过了这个值),该查询将自动被杀掉。如果未设置该值,将使用全局变量
mysql-default_query_timeout的值。 - retries:当在执行查询时探测到故障后,重新执行查询的最大次数。如果未指定,则使用全局变量
mysql-query_retries_on_failure的值。 - delay:延迟执行该查询的毫秒数。本质上是一个限流机制和QoS,使得可以将优先级让位于其它查询。这个值会写入到
mysql-default_query_delay全局变量中,所以它会应用于所有的查询。将来的版本中将会提供一个更高级的限流机制。 - mirror_flagOUT和mirror_hostgroup:mirroring相关的设置,目前mirroring正处于实验阶段,所以不解释。
- error_msg:查询将被阻塞,然后向客户端返回
error_msg指定的信息。 - sticky_conn:当前还未实现该功能。
- multiplex:如果设置为0,将禁用multiplexing。如果设置为1,则启用或重新启用multiplexing,除非有其它条件(如用户变量或事务)阻止启用。如果设置为2,则只对当前查询不禁用multiplexing。默认值为
NULL,表示不会修改multiplexing的策略。 - log:查询将记录日志。
- apply:当设置为1后,当匹配到该规则后,将立即应用该规则,不会再评估其它的规则(注意:应用之后,将不会评估
mysql_query_rules_fast_routing中的规则)。 - comment:注释说明字段,例如描述规则的意义。
4.基于mysql username进行路由
基于mysql user的配置方式和基于端口的配置是类似的。
需要注意,在插入mysql user到mysql_users表中时,就已经指定了默认的路由目标组,这已经算是一个路由规则了(只不过是默认路由目标)。当成功匹配到mysql_query_rules中的规则时,这个默认目标就不再生效。所以,通过默认路由目标,也能简单地实现读写分离。
例如,在后端MySQL Server上先创建好用于读、写分离的用户。例如,root用户用于写操作,reader用户用于读操作。
# 在master节点上执行:
grant all on *.* to root@\'192.168.100.%\' identified by \'P@ssword1!\';
grant select,show databases,show view on *.* to reader@\'192.168.100.%\' identified by \'P@ssword1!\';
然后将这两个用户添加到ProxySQL的mysql_users表中,并创建两条规则分别就有这两个用户进行匹配。
insert into mysql_users(username,password,default_hostgroup)
values(\'root\',\'P@ssword1!\',10),(\'reader\',\'P@ssword1!\',20);
load mysql users to runtime;
save mysql users to disk;
delete from mysql_query_rules; # 为了测试,先清空已有规则
insert into mysql_query_rules(rule_id,active,username,destination_hostgroup,apply)
values(1,1,\'root\',10,1),(2,1,\'reader\',20,1);
load mysql query rules to runtime;
save mysql query rules to disk;
当然,在上面演示的示例中,mysql_query_rules中基于username的规则和mysql_users中这两个用户的默认规则是重复了的。
5.基于数据库名称进行路由
ProxySQL支持基于schemaname进行路由。这在一定程度上实现了简单的sharding功能。例如,将后端MySQL集群中的节点A和节点B定义在不同主机组中,ProxySQL将所有对于DB1库的查询路由到节点A所在的主机组,将所有对DB2库的查询路由到节点B所在的主机组。
只需配置一个schemaname字段就够了,好简单,是不是感觉很爽。但想太多了,ProxySQL的schemaname字段只是个鸡肋,要实现分库sharding,只能通过正则匹配、查询重写的方式来实现。
例如,原语句如下,用于找出浙江省的211大学。
select * from zhongguo.university where prov=\'Zhejiang\' and high=211;
按省份分库后,通过ProxySQL的正则替换,将语句改写为如下SQL语句:
select * from Zhejiang.university where 1=1 high=211;
然后还可以将改写后的SQL语句路由到指定的主机组中,实现真正的分库。
这些内容比较复杂、也比较高级,在后面的文章中我会详细解释。
6.基于SQL语句路由
从这里开始,开始介绍ProxySQL路由规则的核心:基于SQL语句的路由。
ProxySQL接收到前端发送的SQL语句后,首先分析语句,然后从mysql_query_rules表中寻找是否有匹配该语句的规则。如果先被username或ip/port类的规则匹配并应用,则按这些规则路由给后端,如果是被基于SQL语句的规则匹配,则启动正则引擎进行正则匹配,然后路由给对应的后端组,如果规则中指定了正则替换字段,则还会重写SQL语句,然后再发送给后端。
ProxySQL支持两种类型的SQL语句匹配方式:match_digest和match_pattern。在解释这两种匹配方式之前,有必要先解释下SQL语句的参数化。
6.1 SQL语句分类:参数化
什么是参数化?
select * from tbl where id=?
这里将where条件语句中字段id的值进行了参数化,也就是上面的问号?。
我们在客户端发起的SQL语句都是完整格式的语句,但是SQL优化引擎出于优化的目的需要考虑很多事情。例如,如何缓存查询结果、如何匹配查询缓存中的数据并取出,等等。将SQL语句参数化是优化引擎其中的一个行为,对于那些参数相同但参数值不同的查询语句,SQL语句认为这些是同类查询,同类查询的SQL语句不会重复去编译而增加额外的开销。
例如,下面的两个语句,就是同类SQL语句:
select * from tbl where id=10;
select * from tbl where id=20;
将它们参数化后,结果如下:
select * from tbl where id=?;
通俗地讲,这里的"?"就是一个变量,任何满足这个语句类型的值都可以传递到这个变量中。
所以,对参数化进行一个通俗的定义:对于那些参数相同、参数值不同的SQL语句,使用问号"?"去替换参数值,替换后返回的语句就是参数化的结果。
无论是MySQL、SQL Server还是Oracle(这个不确定),优化引擎内部都会将语句进行参数化。例如,下面是SQL Server的执行计划,其中"@1"就是所谓的问号"?"。
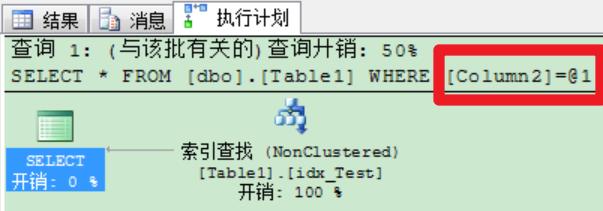
ProxySQL也支持参数化。当前端发送SQL语句到达ProxySQL后,ProxySQL会将其参数化并分类。例如,下面是sysbench测试过程中,ProxySQL统计的参数化语句。
+----+----------+------------+-------------------------------------------------------------+
| hg | sum_time | count_star | digest_text |
+----+----------+------------+-------------------------------------------------------------+
| 2 | 14520738 | 50041 | SELECT c FROM sbtest1 WHERE id=? |
| 1 | 3142041 | 5001 | COMMIT |
| 1 | 2270931 | 5001 | SELECT c FROM sbtest1 WHERE id BETWEEN ? AND ?+? ORDER BY c |
| 1 | 2021320 | 5003 | SELECT c FROM sbtest1 WHERE id BETWEEN ? AND ?+? |
| 1 | 1768748 | 5001 | UPDATE sbtest1 SET k=k+? WHERE id=? |
| 1 | 1697175 | 5003 | SELECT SUM(K) FROM sbtest1 WHERE id BETWEEN ? AND ?+? |
| 1 | 1346791 | 5001 | UPDATE sbtest1 SET c=? WHERE id=? |
| 1 | 1263259 | 5001 | DELETE FROM sbtest1 WHERE id=? |
| 1 | 1191760 | 5001 | INSERT INTO sbtest1 (id, k, c, pad) VALUES (?, ?, ?, ?) |
| 1 | 875343 | 5005 | BEGIN |
+----+----------+------------+-------------------------------------------------------------+
ProxySQL的mysql_query_rules表中有三个字段,能基于参数化后的SQL语句进行三种不同方式的匹配:
- digest:将参数化后的语句进行hash运算得到一个hash值digest,可以对这个hash值进行精确匹配。匹配效率最高。
- match_digest:对digest值进行正则匹配。
- match_pattern:对原始SQL语句的文本内容进行正则匹配。
如果要进行SQL语句的重写(即正则替换),或者对参数值匹配,则必须采用match_pattern。如果可以,尽量采用digest匹配方式,因为它的效率更高。
6.2 路由相关的几个统计表
在ProxySQL的stats库中,包含了几个统计表。
admin> show tables from stats;
+--------------------------------------+
| tables |
+--------------------------------------+
| global_variables |
| stats_memory_metrics |
| stats_mysql_commands_counters | <--已执行查询语句的统计信息
| stats_mysql_connection_pool | <--连接池信息
| stats_mysql_connection_pool_reset | <--重置连接池统计数据
| stats_mysql_global | <--全局统计数据
| stats_mysql_prepared_statements_info |
| stats_mysql_processlist | <--模拟show processlist的结果
| stats_mysql_query_digest | <--本文解释
| stats_mysql_query_digest_reset | <--本文解释
| stats_mysql_query_rules | <--本文解释
| stats_mysql_users | <--各mysql user前端和ProxySQL的连接数
| stats_proxysql_servers_checksums | <--ProxySQL集群相关
| stats_proxysql_servers_metrics | <--ProxySQL集群相关
| stats_proxysql_servers_status | <--ProxySQL集群相关
+--------------------------------------+
这些表的内容、解释我已经翻译,参见:ProxySQL的stats库。本文介绍其中3个和路由、规则相关的表。
6.2.1 stats_mysql_query_digest
这个表对于分析SQL语句至关重要,是分析语句性能、定制路由规则指标的最主要来源。
刚才已经解释过什么是SQL语句的参数化,还说明了ProxySQL会将参数化后的语句进行hash计算得到它的digest,这个统计表中记录的就是每个参数化分类后的语句对应的统计数据,包括该类语句的执行次数、所花总时间、所花最短、最长时间,还包括语句的文本以及它的digest。
如下图:

以下是各个字段的意义:
- hostgroup:查询将要路由到的目标主机组。如果值为-1,则表示命中了查询缓存,直接从缓存取数据返回给客户端。
- schemaname:当前正在执行的查询所在的schema名称。
- username:MySQL客户端连接到ProxySQL使用的用户名。
- digest:一个十六进制的hash值,唯一地代表除了参数值部分的查询语句。
- digest_text:参数化后的SQL语句的文本。注意,如果重写了SQL语句,则这个字段是显示的是重写后的字段。换句话说,这个字段是真正路由到后端,被后端节点执行的语句。
- count_star:该查询(参数相同、值不同)总共被执行的次数。
- first_seen:unix格式的timestamp时间戳,表示该查询首次被ProxySQL路由出去的时间点。
- last_seen:unix格式的timestamp时间戳,到目前为止,上一次该查询被ProxySQL路由出去的时间点。
- sum_time:执行该类查询所花的总时间(单位微秒)。在想要找出程序中哪部分语句消耗时间最长的语句时非常有用,此外根据这个结果还能提供一个如何提升性能的良好开端。
- min_time, max_time:执行该类查询的时间范围。min_time表示的是目前为止执行该类查询所花的最短时间,max_time则是目前为止,执行该类查询所花的最长时间,单位都是微秒。
注意,该表中的查询所花时长是指ProxySQL从接收到客户端查询开始,到ProxySQL准备向客户端发送查询结果的时长。因此,这些时间更像是客户端看到的发起、接收的时间间隔(尽管客户端到服务端数据传输也需要时间)。更精确一点,在执行查询之前,ProxySQL可能需要更改字符集或模式,可能当前后端不可用(当前后端执行语句失败)而找一个新的后端,可能因为所有连接都繁忙而需要等待空闲连接,这些都不应该计算到查询执行所花时间内。
其中hostgroup、digest、digest_text、count_start、{sum,min,max}_time这几列最常用。
例如:
admin> select hostgroup hg,count_star,sum_time,digest,digest_text from stats_mysql_query_digest;
+----+------------+----------+--------------------+------------------------+
| hg | count_star | sum_time | digest | digest_text |
+----+------------+----------+--------------------+------------------------+
| 10 | 4 | 2412 | 0xADB885E1F3A7A5C2 | select * from test2.t1 |
| 10 | 6 | 4715 | 0x57497F236587B138 | select * from test1.t1 |
+----+------------+----------+--------------------+------------------------+
从中分析,两个语句都路由到了hostgroup=10的组中,第一个语句执行了4次,这4次总共花费了2412微秒(即2.4毫秒),第二个语句执行了6次,总花费4.7毫秒。还给出了这两个语句参数化后的digest值,以及参数化后的SQL文本。
6.2.2 stats_mysql_query_digest_reset
这个表的表结构和stats_mysql_query_digest是完全一样的,只不过每次从这个表中检索数据(随便检索什么,哪怕where 1=0),都会重置stats_mysql_query_digest表中已统计的数据。
6.2.3 stats_mysql_query_rules
这个表只有两个字段:
rule_id:对应的是规则号码。hits,对应的是每个规则被命中了多少次。
6.3 基于SQL语句路由:digest
digest匹配规则是对digest进行精确匹配。
例如,从stats_mysql_query_digest中获取两个对应的digest值。注意,现在它们的hostgroup_id=10。
admin> select hostgroup hg,count_star,sum_time,digest,digest_text from stats_mysql_query_digest;
+----+------------+----------+--------------------+------------------------+
| hg | count_star | sum_time | digest | digest_text |
+----+------------+----------+--------------------+------------------------+
| 10 | 4 | 2412 | 0xADB885E1F3A7A5C2 | select * from test2.t1 |
| 10 | 6 | 4715 | 0x57497F236587B138 | select * from test1.t1 |
+----+------------+----------+--------------------+------------------------+
插入两条匹配这两个digest的规则:
insert into mysql_query_rules(rule_id,active,digest,destination_hostgroup,apply)
values(1,1,"0xADB885E1F3A7A5C2",20,1),(2,1,"0x57497F236587B138",10,1);
然后测试
mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e "select * from test1.t1;"
mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e "select * from test2.t1;"
再去查看规则的路由命中情况:
admin> select * from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 1 |
| 2 | 1 |
+---------+------+
查看路由的目标:
admin> select hostgroup hg,count_star cs,digest,digest_text from stats_mysql_query_digest;
+----+----+--------------------+------------------------+
| hg | cs | digest | digest_text |
+----+----+--------------------+------------------------+
| 20 | 1 | 0xADB885E1F3A7A5C2 | select * from test2.t1 |
| 10 | 1 | 0x57497F236587B138 | select * from test1.t1 |
+----+----+--------------------+------------------------+
可见,基于digest的精确匹配规则已经生效。
6.4 基于SQL语句路由:match_digest
match_digest是对digest做正则匹配,但注意match_pattern字段中给的规则不是hash值,而是SQL语句的文本匹配规则。
ProxySQL支持两种正则引擎:
- 1.PCRE
- 2.RE2
老版本中默认的正则引擎是RE2,现在默认的正则引擎是PCRE。可从变量mysql-query_processor_regex获知当前的正则引擎是RE2还是PCRE:
Admin> select @@mysql-query_processor_regex;
+-------------------------------+
| @@mysql-query_processor_regex |
+-------------------------------+
| 1 |
+-------------------------------+
其中1代表PCRE,2代表RE2。
在mysql_query_rules表中有一个字段re_modifiers,它用于定义正则引擎的修饰符,默认已经设置caseless,表示正则匹配时忽略大小写,所以select和SELECT都能匹配。此外,还可以设置global修饰符,表示匹配全局,而非匹配第一个,这个在重写SQL语句时有用。
(RE2引擎无法同时设置caseless和global,即使它们都设置了也不会生效。所以,将默认的正则引擎改为了PCRE)
在进行下面的实验之前,先把mysql_query_rules表清空,并将规则的统计数据也清空。
delete from mysql_query_rules;
select * from stats_mysql_query_digest_reset;
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)
values (1,1,"^select .* test2.*",20,1),(2,1,"^select .* test1.*",10,1);
load mysql query rules to runtime;
save mysql query rules to disk;
然后分别执行:
mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e "select * from test1.t1;"
mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e "select * from test2.t1;"
查看规则匹配结果:
admin> select * from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 1 |
| 2 | 1 |
+---------+------+
admin> select hostgroup hg,count_star cs,digest,digest_text dt from stats_mysql_query_digest;
+----+----+--------------------+------------------------+
| hg | cs | digest | dt |
+----+----+--------------------+------------------------+
| 10 | 1 | 0x57497F236587B138 | select * from test1.t1 |
| 20 | 1 | 0xADB885E1F3A7A5C2 | select * from test2.t1 |
+----+----+--------------------+------------------------+
显然,命中规则,且按照期望进行路由。
如果想对match_digest取反,即不被正则匹配的SQL语句才命中规则,则设置mysql_query_rules表中的字段negate_match_pattern=1。同样适用于下面的match_pattern匹配方式。
6.5 基于SQL语句路由:match_pattern
和match_digest的匹配方式类似,但match_pattern是基于原始SQL语句进行匹配的,包括参数值。有两种情况必须使用match_pattern:
- 重写SQL语句,即同时设置了replace_pattern字段。
- 对参数的值进行匹配。
如果想对match_pattern取反,即不被正则匹配的SQL语句才命中规则,则设置mysql_query_rules表中的字段negate_match_pattern=1。
例如:
## 清空规则以及规则的统计数据
delete from mysql_query_rules;
select * from stats_mysql_query_digest_reset where 1=0;
insert into mysql_query_rules(rule_id,active,match_pattern,destination_hostgroup,apply)
values(1,1,"^select .* test2.*",20,1),(2,1,"^select .* test1.*",10,1);
load mysql query rules to runtime;
save mysql query rules to disk;
执行查询:
mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e "select * from test1.t1;"
mysql -uroot -pP@ssword1! -h127.0.0.1 -P6033 -e "select * from test2.t1;"
然后查看匹配结果:
admin> select * from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 1 |
| 2 | 1 |
+---------+------+
admin> select hostgroup hg,count_star cs,digest,digest_text dt from stats_mysql_query_digest;
+----+----+--------------------+------------------------+
| hg | cs | digest | dt |
+----+----+--------------------+------------------------+
| 20 | 1 | 0xADB885E1F3A7A5C2 | select * from test2.t1 |
| 10 | 1 | 0x57497F236587B138 | select * from test1.t1 |
+----+----+--------------------+------------------------+
再来看看匹配参数值(虽然几乎不会这样做)。这里要测试的语句如下:
mysql -uroot -p123456 -h127.0.0.1 -P6033 -e "select * from test1.t1 where name like \'malong%\';"
mysql -uroot -p123456 -h127.0.0.1 -P6033 -e "select * from test2.t1 where name like \'xiaofang%\';"
现在插入两条规则,对参数"malong%"和"xiaofang"进行匹配。
## 清空规则以及规则的统计数据
delete from mysql_query_rules;
select * from stats_mysql_query_digest_reset where 1=0;
insert into mysql_query_rules(rule_id,active,match_pattern,destination_hostgroup,apply)
values(1,1,"malong",20,1),(2,1,"xiaofang",10,1);
load mysql query rules to runtime;
save mysql query rules to disk;
执行上面的两个查询语句,然后查看匹配结果:
admin> select * from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 1 |
| 2 | 1 |
+---------+------+
admin> select hostgroup hg,count_star cs,digest,digest_text dt from stats_mysql_query_digest;
+----+----+--------------------+------------------------------------------+
| hg | cs | digest | dt |
+----+----+--------------------+------------------------------------------+
| 20 | 1 | 0x0C624EDC186F0217 | select * from test1.t1 where name like ? |
| 10 | 1 | 0xA38442E236D915A7 | select * from test2.t1 where name like ? |
+----+----+--------------------+------------------------------------------+
已按预期进行路由。
7.实用的读写分离
一个极简单却大有用处的读、写分离功能:将默认路由组设置为写组,然后再插入下面两个select语句的规则。
# 10为写组,20为读组
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)
VALUES (1,1,\'^SELECT.*FOR UPDATE$\',10,1),
(2,1,\'^SELECT\',20,1);
但需要注意的是,这样的规则只适用于小环境下的读写分离,对于稍复杂的环境,需要对不同语句进行开销分析,对于开销大的语句需要制定专门的路由规则。在之后的文章中我会稍作分析。
8.总结
ProxySQL能通过ip、port、client_ip、username、schemaname、digest、match_digest、match_pattern实现不同方式的路由,方式可谓繁多。特别是基于正则匹配的灵活性,使得ProxySQL能满足一些比较复杂的环境。
总的来说,ProxySQL主要是通过digest、match_digest和match_pattern进行规则匹配的。在本文中,只是介绍了匹配规则的基础以及简单的用法,为进军后面的文章做好铺垫。