pymysql操作数据库与索引
Posted 绝渊逢生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pymysql操作数据库与索引相关的知识,希望对你有一定的参考价值。
pymysql操作数据库
简单操作
import pymysql # pip install pymysql
# 连接数据库的参数
conn = pymysql.connect(host= \'localhost\',
user=\'root\',
password = \'123\',
database=\'db3\',
charset = \'utf8\')
# cursor = conn.cursor() # <pymysql.cursors.Cursor object at 0x000000000A0E2C50>,游标对象,默认返回的值是元祖类型
cursor = conn.cursor(cursor = pymysql.cursors.DictCursor) # <pymysql.cursors.DictCursor object at 0x000000000A0E2C88> 返回的值是字典类型
# print(cursor)
sql = "select name from userinfo where id>10"
cursor.execute(sql)
res= cursor.fetchall() # #取出所有的数据 返回的是列表套字典
# res = cursor.fetchone() # 只获取一条数据
# res = cursor.fetchmany(size) # 可指定参数, 取出size条数据 返回的是列表套字典
print(res)
cursor.close()
conn.close()
\'\'\'
[{\'name\': \'丁丁\'}, {\'name\': \'星星\'}, {\'name\': \'格格\'}, {\'name\': \'张野\'}, {\'name\': \'程咬金\'}, {\'name\': \'程咬银\'}, {\'name\': \'程咬铜\'}, {\'name\': \'程咬铁\'}]
\'\'\'
sql的注入问题
import pymysql
user = input(\'输入用户名:\').strip()
password = input(\'输入密码:\').strip()
# 连接数据库的参数
conn = pymysql.connect(host= \'localhost\',
user=\'root\',
password = \'123\',
database=\'db3\',
charset = \'utf8\')
# cursor = conn.cursor() # <pymysql.cursors.Cursor object at 0x000000000A0E2C50>,游标对象,默认返回的值是元祖类型
cursor = conn.cursor(cursor = pymysql.cursors.DictCursor) # <pymysql.cursors.DictCursor object at 0x000000000A0E2C88> 返回的值是字典类型
# print(cursor)
sql = "select * from user where name=\'%s\' and password=\'%s\'"%(user,password)
print(sql)
# exit()
cursor.execute(sql)
res= cursor.fetchall() # #取出所有的数据 返回的是列表套字典
# res = cursor.fetchone() # 只获取一条数据
# res = cursor.fetchmany(size) # 可指定参数, 取出size条数据 返回的是列表套字典
print(res)
if res:
print(\'登录成功!\')
else:
print(\'登录失败!\')
cursor.close()
conn.close()
\'\'\'
输入用户名:zhang\' #
输入密码:123
select * from user where name=\'zhang\' #\' and password=\'123\'
[{\'name\': \'zhang\', \'password\': \'123 \'}]
登录成功!
\'\'\'
\'\'\'
输入用户名:zhang\' or 1=1 #
输入密码:123
select * from user where name=\'zhang\' or 1=1 #\' and password=\'123\'
[{\'name\': \'zhang\', \'password\': \'123 \'}]
登录成功!
\'\'\'
# 输入用户名的时候,输入‘#’将后面的密码验证部分注释掉了,语句变成了select * from user where name=\'zhang\' 或者 select * from user where name=\'zhang\' or 1=1,直接跳过了密码的验证环节,出现了sql语句的注入问题。
sql注入问题解决办法
# 出现sql注入问题主要是我们对用户输入没有做合法性验证,
# 方法1:如果对用户输入的值进行判断或者转译,检查完之后或者转译后就不会出现此类问题了。这样低级安全问题不该出现!
# 方法2:将参数以元组或列表的形式传入execute中,让它帮我们转译和检验;即:cursor.execute(sql,(user,password))
import pymysql
user = input(\'输入用户名:\').strip()
password = input(\'输入密码:\').strip()
# 连接数据库的参数
conn = pymysql.connect(host= \'localhost\',
user=\'root\',
password = \'123\',
database=\'db3\',
charset = \'utf8\')
# cursor = conn.cursor() # <pymysql.cursors.Cursor object at 0x000000000A0E2C50>,游标对象,默认返回的值是元祖类型
cursor = conn.cursor(cursor = pymysql.cursors.DictCursor) # <pymysql.cursors.DictCursor object at 0x000000000A0E2C88> 返回的值是字典类型
# print(cursor)
sql = "select * from user where name=%s and password=%s"
print(sql)
# exit()
cursor.execute(sql,(user,password))
res= cursor.fetchall() # #取出所有的数据 返回的是列表套字典
# res = cursor.fetchone() # 只获取一条数据
# res = cursor.fetchmany(size) # 可指定参数, 取出size条数据 返回的是列表套字典
print(res)
if res:
print(\'登录成功!\')
else:
print(\'登录失败!\')
cursor.close()
conn.close()
\'\'\'
输入用户名:zhang
输入密码:123
select * from user where name=%s and password=%s
[{\'name\': \'zhang\', \'password\': \'123 \'}]
登录成功!
\'\'\'
\'\'\'
输入用户名:zhang\' #
输入密码:123
select * from user where name=%s and password=%s
()
登录失败!
\'\'\'
sql注入问题模板总结
产生的原因:
因为过于相信用户输入的内容, 根本没有做任何的检验
解决的方法:
sql = "select * from user where name=%s and password=%s"
# execute帮我们做字符串拼接,我们无需且一定不能再为%s加引号了
cursor.execute(sql, (user, pwd))
连接:
### 连接数据库的参数
conn = pymysql.connect(host=\'localhost\',user=\'root\',password=\'123qwe\',database=\'test\',charset=\'utf8\')
# cursor = conn.cursor() ### 默认返回的值是元祖类型
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) ### 返回的值是字典类型 (*********)
查:
fetchall() : 取出所有的数据 返回的是列表套字典
fetchone() : 取出一条数据 返回的是字典
fetchmany(size) : 取出size条数据 返回的是列表套字典
利用pymysql操作数据库 (增删改),conn.commit()
# 插入
import pymysql
# 连接数据库的参数
conn = pymysql.connect(host= \'localhost\',
user=\'root\',
password = \'123\',
database=\'db3\',
charset = \'utf8\')
cursor = conn.cursor(cursor = pymysql.cursors.DictCursor)
sql = "insert into user(name,password) values(%s,%s)"
print(sql) # insert into user(name,password) values(%s,%s)
# cursor.execute(sql,("zhang",\'qwe\')) # 插入单条
data=[(\'小王\',\'111\'),(\'小张\',\'222\'),(\'小李\',\'333\'),(\'小张\',\'444\'),]
cursor.executemany(sql,data) # 插入多条
conn.commit()
cursor.close()
conn.close()
# 插入单条情况下
\'\'\'
mysql> select * from user;
+-------+----------+
| name | password |
+-------+----------+
| zhang | 123 |
| wang | qwe |
+-------+----------+
2 rows in set (0.00 sec)
\'\'\'
# 插入多条情况下
\'\'\'
mysql> select * from user;
+--------+----------+
| name | password |
+--------+----------+
| zhang | 123 |
| wang | qwe |
| wang | qwe |
| 小王 | 111 |
| 小张 | 222 |
| 小李 | 333 |
| 小张 | 444 |
+--------+----------+
7 rows in set (0.00 sec)
\'\'\'
# 修改
先给user表增加一个id索引字段;
mysql> alter table user add id int primary key auto_increment FIRST;
Query OK, 0 rows affected (0.50 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from user;
+----+--------+----------+
| id | name | password |
+----+--------+----------+
| 1 | zhang | 123 |
| 2 | wang | qwe |
| 3 | wang | qwe |
| 4 | 小王 | 111 |
| 5 | 小张 | 222 |
| 6 | 小李 | 333 |
| 7 | 小张 | 444 |
+----+--------+----------+
7 rows in set (0.00 sec)
# 进行修改操作 将 id=6 的记录的 name 字段的名字修改为 ‘小李子’
import pymysql
# 连接数据库的参数
conn = pymysql.connect(host= \'localhost\',
user=\'root\',
password = \'123\',
database=\'db3\',
charset = \'utf8\')
cursor = conn.cursor(cursor = pymysql.cursors.DictCursor)
sql = "update user set name = %s where id = %s"
cursor.execute(sql,(\'小李子\',6)) # 插入多条
conn.commit()
cursor.close()
conn.close()
\'\'\'
mysql> select * from user;
+----+-----------+----------+
| id | name | password |
+----+-----------+----------+
| 1 | zhang | 123 |
| 2 | wang | qwe |
| 3 | wang | qwe |
| 4 | 小王 | 111 |
| 5 | 小张 | 222 |
| 6 | 小李子 | 333 |
| 7 | 小张 | 444 |
+----+-----------+----------+
7 rows in set (0.00 sec)
\'\'\'
# 删除
import pymysql
# 连接数据库的参数
conn = pymysql.connect(host= \'localhost\',
user=\'root\',
password = \'123\',
database=\'db3\',
charset = \'utf8\')
cursor = conn.cursor(cursor = pymysql.cursors.DictCursor)
sql = "delete from user where id>%s"
cursor.execute(sql,6) # 插入多条
conn.commit()
cursor.close()
conn.close()
\'\'\'
mysql> select * from user;
+----+-----------+----------+
| id | name | password |
+----+-----------+----------+
| 1 | zhang | 123 |
| 2 | wang | qwe |
| 3 | wang | qwe |
| 4 | 小王 | 111 |
| 5 | 小张 | 222 |
| 6 | 小李子 | 333 |
+----+-----------+----------+
6 rows in set (0.00 sec)
\'\'\'
索引
1.为何要有索引
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了
2.什么是索引?
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能
非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
3.索引使用的优缺点
若索引太多,应用程序的性能可能会受到影响。而索引太少,对查询性能又会产生影响,要找到一个平衡点,这对应用程序的性能至关重要。当然索引也并不是越多越好,我曾经遇到过这样一个问题:某台MySQL服务器iostat显示磁盘使用率一直处于100%,经过分析后发现是由于开发人员添加了太多的索引,在删除一些不必要的索引之后,磁盘使用率马上下降为20%。可见索引的添加也是非常有技术含量的。下面会细讲创建索引的优缺点
优点:提高查询效率;缺点:加了索引之后,会占用大量的磁盘空间,创建索引时会消耗大量时间。
4.索引原理
B+树
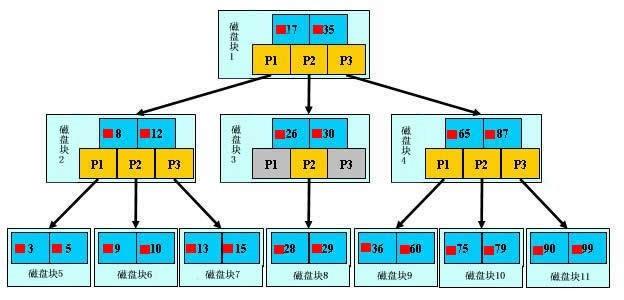
本质是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据
# 插入3000,000条数据做实验 哈哈哈哈 !!!!
import pymysql
# 连接数据库的参数
conn = pymysql.connect(host= \'localhost\',
user=\'root\',
password = \'123\',
database=\'db3\',
charset = \'utf8\')
cursor = conn.cursor(cursor = pymysql.cursors.DictCursor)
l=[]
for i in range(3000000):
res=(f\'小张{i}\',str(i))
l.append(res)
sql = "insert into user(name,password) values(%s,%s)"
cursor.executemany(sql,l) # 插入多条
conn.commit()
cursor.close()
conn.close()
\'\'\'
| 1033019 | 小张2829 | 2829 |
| 1033020 | 小张2830 | 2830 |
| 1033021 | 小张2831 | 2831 |
| 1033022 | 小张2832 | 2832 |
| 1033023 | 小张2833 | 2833 |
| 1033024 | 小张2834 | 2834 |
| 1033025 | 小张2835 | 2835 |
| 1033026 | 小张2836 | 2836 |
| 1033027 | 小张2837 | 2837 |
| 1033028 | 小张2838 | 2838 |
| 1033029 | 小张2839 | 2839 |
| 1033030 | 小张2840 | 2840 |
| 1033031 | 小张2841 | 2841 |
| 1033032 | 小张2842 | 2842 |
| 1033033 | 小张2843 | 2843 |
| 1033034 | 小张2844 | 2844 |
| 1033035 | 小张2845 | 2845 |
| 1033036 | 小张2Ctrl-C -- sending "KILL QUERY 1" to server ...
846 Ctrl-C -- query aborted.
| 2846 |
+---------+---------------+----------+
3000006 rows in set (2.46 sec)
\'\'\'
5.索引的种类
索引的种类:(**************************)
主键索引: 加速查找 + 不能重复 + 不能为空 primary key
唯一索引: 加速查找 + 不能重复 unique(name)
联合唯一索引:unique(name, email)
例子:
zekai 123@qq.com
zekai 123@qq.cmm
普通索引: 加速查找 index (name)
联合索引: index (name, email)
6.索引的创建
主键索引
主键索引:表设置了主键的情况下,才能设置auto_increment,否则报错;删除主键,主键设置有auto_increment情况下,先将其删除,否则无法删除主键primary key;
新增主键索引:
create table xxx(
id int auto_increment ,
primary key(id)
)
改:
# change不仅可以修改字段类型和约束条件,还可以修改字段名字;
alter table xxx change id id int auto_increment primary key;
# 只能修改字段类型和约束条件
alter table xxx modify id int auto_increment primary key; # 同上
alter table t1 add primary key (id);
删除主键索引:
mysql> alter table t1 drop primary key;
唯一索引
唯一索引:
1.新增:
create table t2(
id int primary key auto_increment,
name varchar(32) not null default \'\',
unique u_name (name) # 为了后续删除方便,unique(唯一索引)单写一行,并起别名(u_name),否则后续无法删除;
)charset utf8;
2.增:
CREATE UNIQUE INDEX 索引名 ON 表名 (字段名) ;
create unique index ix_name on t2(name);
3.改:
alter table t2 add unique index ix_name (name)
4.删除:
alter table t2 drop index u_name;
普通索引
普通索引:
1.新增:
create table t3(
id int primary key auto_increment ,
name varchar(32) not null default \'\',
index u_name (name) # 为了后续删除方便,indexe(普通索引)单写一行,并起别名(u_name),否则后续无法删除;
)charset utf8;
2.增:
CREATE INDEX 索引名 ON 表名 (字段名) ;
create index ix_name on t3(name);
3.改:
alter table t3 add index ix_name (name)
4.删除:
alter table t3 drop index u_name;
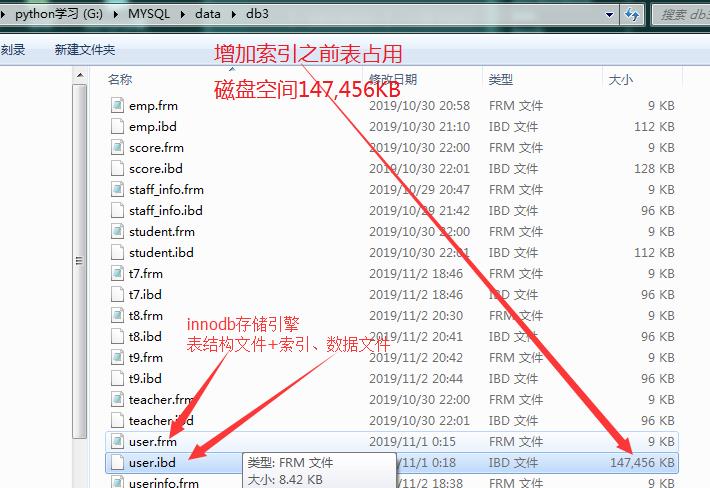


索引的优缺点:
通过以上图片中 *.ibd文件可知:
1.索引加快了查询速度
2.但加了索引之后,会占用大量的磁盘空间
3.当数据量大时,给某个字段创建索引会花费大量时间。
7.不会命中索引的情况
没命中索引,会降低SQL的查询效率;
1.SQl语句中,进行四则运算;
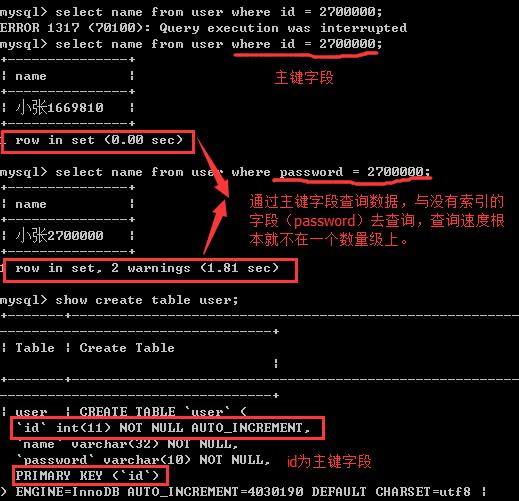
mysql> desc user;
+----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(32) | NO | | NULL | |
| password | varchar(10) | NO | | NULL | |
+----------+-------------+------+-----+---------+----------------+
3 rows in set (0.01 sec)
mysql> select count(*) from user where id=1500000;
+----------+
| count(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
# 索引字段id,参与了计算,无法拿到一个明确的值去索引树中查找,每次都得临时计算一下。
mysql> select count(*) from user where id*3=1500000;
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (2.00 sec)
2.使用函数
mysql> alter table user add index ix_name_psw(name,password); # 给name,password建立联合索引;
Query OK, 0 rows affected (18.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from user where reverse(name)=\'小张1\'; # 使用函数
Empty set (1.40 sec) # 使用函数用时1.4s
mysql> select * from user where name=\'小张1\'; # 未使用函数
+---------+---------+----------+
| id | name | password |
+---------+---------+----------+
| 1030191 | 小张1 | 1 |
+---------+---------+----------+
1 row in set (0.00 sec) # 未用函数用时0.0s
3.查询时,使用字段的类型不一致;
mysql> select * from user where name=\'小张8888\'; # 定义name是字符串类型,用字符串查询;
+---------+------------+----------+
| id | name | password |
+---------+------------+----------+
| 1039078 | 小张8888 | 8888 |
+---------+------------+----------+
1 row in set (0.00 sec)
mysql> select * from user where name=8888; # 定义name是字符串类型,用整型查询;
Empty set, 65535 warnings (1.91 sec)
4.排序(order by)条件为索引,select字段不是索引字段
mysql> desc user;
+----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(32) | NO | MUL | NULL | |
| password | varchar(10) | NO | | NULL | |
+----------+-------------+------+-----+---------+----------------+
3 rows in set (0.01 sec)
# 有索引的情况下,默认这一列是已经排过序的,order by直接按照索引的排序往下走,所以速度快些。
mysql> select name from user order by name; # 排序字段(有索引)与select字段一样
+---------------+
| name |
+---------------+
| wang |
| wang |
| zhang |
|....... |
........
.......
......
| 小张1000023 |
| 小张1000024 |
| 小张1000025 |
| 小Ctrl-C -- sending "KILL QUERY 2" to server ...
张Ctrl-C -- query aborted.
1000026 |
+---------------+
3000006 rows in set (1.89 sec)
# password没有索引,order by 要重新排序
mysql> select name from user order by password desc; # 排序字段(没索引)与select字段(有索引)不一样
+---------------+
| name |
+---------------+
| 小张0 |
| 小张1 |
| 小张10 |
| 小张100 |
| 小张100001 |
| 小张1000010 |
| 小张1Ctrl-C -- sending "KILL QUERY 2" to server ...
00Ctrl-C -- query aborted.
0011 |
+---------------+
3000006 rows in set (6.06 sec) # 明显查询时间延长;
特别的:如果对主键排序,则速度还是很快:
select * from tb1 order by id desc;
5.组合索引最左前缀
什么时候会创建联合索引?
根据公司的业务场景, 在最常用的几列上添加索引
select * from user where name=\'zekai\' and email=\'zekai@qq.com\';
如果遇到上述业务情况, 错误的做法:
index ix_name (name),
index ix_psw(password)
正确的做法:
index ix_name_psw(name, password)
如果组合索引为:index ix_name_psw(name, password)
where name=\'小张\' and password=\'xxxx\' -- 命中索引
where name=\'小张\' -- 命中索引
where password=222 -- 未命中索引
例子:
index (a,b,c,d)
where a=2 and b=3 and c=4 and d=5 --->命中索引
# 最左前缀匹配,几个字段建立联合索引,命中索引必须是从最左边字段连续的几个字段。
where a=2 and c=3 and d=4 ----> 未命中
8.explain (显示检测报告)
explain通过显示信息,判断我们写的SQL语句是否用到了我们添加的的这个字段的索引,给我们一份报告,我们我们通过报告结果去优化自己写的SQL语句。
方法1:
mysql> explain select * from user where name=\'小张1\' and password=1; # 以表格形式展示
方法2:
# 命中索引
mysql> explain select * from user where name=\'小张\'\\G # 末尾不用加分号
# 以报告单的形式显示
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user
type: ref
possible_keys: ix_name_psw
key: ix_name_psw
key_len: 98
ref: const
rows: 1 # 扫描的长度,3000,000行数据值扫描了一行就拿到了数据。
Extra: Using where; Using index
1 row in set (0.00 sec)
# 命中索引
mysql> explain select * from user where name=\'小张\' and password=222\\G # 末尾不用加分号
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user
type: ref # 索引指向 all
possible_keys: ix_name_psw # 可能用到的索引
key: ix_name_psw # 确实用到的索引
key_len: 98 # 索引长度
ref: const
rows: 1 # 扫描的长度,3000,000行数据值扫描了一行就拿到了数据。
Extra: Using where; Using index # 使用到了索引
1 row in set (0.00 sec)
# 之前已经对name和password建立了联合索引,但是单独使用password作为查询条件,并没有命中索引,扫描行数就会增加;
mysql> select * from user where password=222;
+---------+-----------+----------+
| id | name | password |
+---------+-----------+----------+
| 5 | 小张 | 222 |
| 1030412 | 小张222 | 222 |
+---------+-----------+----------+
2 rows in set, 2 warnings (1.60 sec)
mysql> explain select * from user where password=222\\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user
type: index
possible_keys: NULL # 表示没有使用到索引
key: ix_name_psw
key_len: 130
ref: NULL
rows: 2742817 # 没有命中索引的扫描行数。
Extra: Using where; Using index
1 row in set (0.00 sec)
9.索引覆盖
当where里的条件与select查询条件相同时,就产生了索引覆盖。
mysql> select id from user where id=2450000;
+---------+
| id |
+---------+
| 2450000 |
+---------+
1 row in set (0.01 sec)
慢日志管理
根据公司业务场景,设置慢日志查询。比如我们写的SQL语句超过了阈值(自定义时间),那么我们通过这个日子可以查看到底是哪些SQL语句查询时超过了阈值,从而对其进行优化。
慢日志
- 执行时间 > 10
- 未命中索引
- 日志文件路径
配置:
- 内存
show variables like \'%slow%\';
show variables like \'%long%\';
set global 变量名 = 值
- 配置文件
mysqld --defaults-file=\'E:\\wupeiqi\\mysql-5.7.16-winx64\\mysql-5.7.16-winx64\\my-default.ini\'
my.conf内容:
slow_query_log = ON
slow_query_log_file = D:/....
注意:修改配置文件之后,需要重启服务
慢查询日志:
查看慢SQL的相关变量
mysql> show variables like \'%slow%\';
+---------------------------+----------------------------------------+
| Variable_name | Value |
+---------------------------+----------------------------------------+
| log_slow_admin_statements | OFF |
| log_slow_slave_statements | OFF |
| slow_launch_time | 2 |
| slow_query_log | OFF # 默认关闭慢SQl查询日志,现在改成on |
| slow_query_log_file | G:\\MYSQL\\data\\WIN-KIJ962UBO3B-slow.log | # 慢SQL记录的位置
+---------------------------+----------------------------------------+
5 rows in set (0.00 sec)
查看长SQL的相关变量
mysql> show variables like \'%long%\';
+--------------------------------------------------------+-----------+
| Variable_name | Value |
+--------------------------------------------------------+-----------+
| long_query_time | 10.000000 |
| performance_schema_events_stages_history_long_size | 10000 |
| performance_schema_events_statements_history_long_size | 10000 |
| performance_schema_events_waits_history_long_size | 10000 |
+--------------------------------------------------------+-----------+
4 rows in set (0.00 sec)
配置慢SQL的变量:
set global 变量名 = 值
1.设置慢查询开启模式
set global slow_query_log = on;
2.设置慢查询记录文件位置(在文件路径的文件夹自动生成)
set global slow_query_log_file="G:\\MYSQL\\data\\WIN-KIJ962UBO3B-slow.log";
3.修改慢查询的阈值
set global long_query_time=1;
# 配置慢查询日志操作:
mysql> set global slow_query_log = on;
Query OK, 0 rows affected (0.00 sec)
mysql>set global slow_query_log_file="G:\\MYSQL\\data\\WIN-KIJ962UBO3B-slow.log";
Query OK, 0 rows affected (0.04 sec)
mysql>set global long_query_time=1;
Query OK, 0 rows affected (0.00 sec)
查看慢日志设置是否成功: # 记得要重新启动客户端
mysql> use db3;
Database changed
mysql> show variables like \'%slow%\';
+---------------------------+-------------------------------------+
| Variable_name | Value |
+---------------------------+-------------------------------------+
| log_slow_admin_statements | OFF |
| log_slow_slave_statements | OFF |
| slow_launch_time | 2 |
| slow_query_log | ON |
| slow_query_log_file | G:MYSQLdataWIN-KIJ962UBO3B-slow.log |
+---------------------------+-------------------------------------+
5 rows in set (0.00 sec)
mysql> show variables like \'%long%\';
+--------------------------------------------------------+----------+
| Variable_name | Value |
+--------------------------------------------------------+----------+
| long_query_time | 1.000000 |
| performance_schema_events_stages_history_long_size | 10000 |
| performance_schema_events_statements_history_long_size | 10000 |
| performance_schema_events_waits_history_long_size | 10000 |
+--------------------------------------------------------+----------+
4 rows in set (0.00 sec)
此时在"G:\\MYSQL\\data\\";路径下会生成一个WIN-KIJ962UBO3B-slow.log文件,将sql语句查询超过1s的记录下来;
mysql> select * from user where password=222;
+---------+-----------+----------+
| id | name | password |
+---------+-----------+----------+
| 5 | 小张 | 222 |
| 1030412 | 小张222 | 222 |
+---------+-----------+----------+
2 rows in set, 2 warnings (1.50 sec) # 超过阈值1s
查看"G:\\MYSQL\\data\\WIN-KIJ962UBO3B-slow.log" 文件内是否保存超过1s的sql语句;
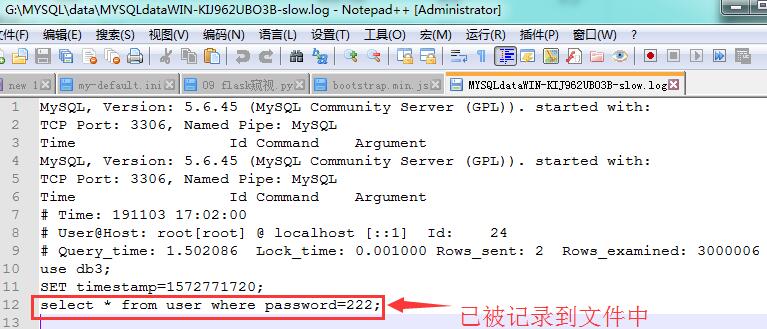
以后我们对超过阈值的sql语句进行优化,就可以打开该文件逐个分析优化了。
MySQL日志管理
========================================================
错误日志: 记录 MySQL 服务器启动、关闭及运行错误等信息
二进制日志: 又称binlog日志,以二进制文件的方式记录数据库中除 SELECT 以外的操作
查询日志: 记录查询的信息
慢查询日志: 记录执行时间超过指定时间的操作
中继日志: 备库将主库的二进制日志复制到自己的中继日志中,从而在本地进行重放
通用日志: 审计哪个账号、在哪个时段、做了哪些事件
事务日志或称redo日志: 记录Innodb事务相关的如事务执行时间、检查点等
========================================================
一、bin-log
1. 启用
# vim /etc/my.cnf
[mysqld]
log-bin[=dir\\[filename]]
# service mysqld restart
2. 暂停
//仅当前会话
SET SQL_LOG_BIN=0;
SET SQL_LOG_BIN=1;
3. 查看
查看全部:
# mysqlbinlog mysql.000002
按时间:
# mysqlbinlog mysql.000002 --start-datetime="2012-12-05 10:02:56"
# mysqlbinlog mysql.000002 --stop-datetime="2012-12-05 11:02:54"
# mysqlbinlog mysql.000002 --start-datetime="2012-12-05 10:02:56" --stop-datetime="2012-12-05 11:02:54"
按字节数:
# mysqlbinlog mysql.000002 --start-position=260
# mysqlbinlog mysql.000002 --stop-position=260
# mysqlbinlog mysql.000002 --start-position=260 --stop-position=930
4. 截断bin-log(产生新的bin-log文件)
a. 重启mysql服务器
b. # mysql -uroot -p123 -e \'flush logs\'
5. 删除bin-log文件
# mysql -uroot -p123 -e \'reset master\'
二、查询日志
启用通用查询日志
# vim /etc/my.cnf
[mysqld]
log[=dir\\[filename]]
# service mysqld restart
三、慢查询日志
启用慢查询日志
# vim /etc/my.cnf
[mysqld]
log-slow-queries[=dir\\[filename]]
long_query_time=n
# service mysqld restart
MySQL 5.6:
slow-query-log=1
slow-query-log-file=slow.log
long_query_time=3
查看慢查询日志
测试:BENCHMARK(count,expr)
SELECT BENCHMARK(50000000,2*3);
查询优化注意事项:常见的SQL语句查询与优化
以上是关于pymysql操作数据库与索引的主要内容,如果未能解决你的问题,请参考以下文章