安装Hadoop
Posted 陌默安
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了安装Hadoop相关的知识,希望对你有一定的参考价值。
安装前
1,更新apt
sudo apt-get update
会让你输入密码(自己登录Ubuntu的时候设置的),输入密码不会显示在终端面板上,确定自己敲对之后点回车就行。
2,安装SSH服务器

sudo apt-get install openssh-server
安装过程中有个Y/N? 选Y
如果出现

解决一:
sudo rm /var/cache/apt/archives/lock sudo rm /var/lib/dpkg/lock sudo rm /var/lib/dpkg/lock-frontend
解决二:
ps -e | grep apt
会出现类似这样结果

这时我们只需要杀死apt-get进程就好了(找不到还是用解决一强制解锁吧-_-||)
sudo kill 【进程号(如701)】
3,登录本机
ssh localhost
出现yes or no ? yes
输入密码(你自己知道)
4,利用ssh-keygen生成密钥(主要用来设置下次登录不用输密码)
cd ~/.ssh/
ssh-keygen -t rsa
三下回车
cat ./id_rsa.pub >> authorized_keys
5,安装JAVA环境
sudo apt-get install default-jre default-jdk
1)打开环境变量配置文件
vim ~/.bashrc 按I键 在开头插入 export JAVA_HOME=/usr/lib/jvm/default-java Esc键保存 输入 :wq 退出
如果没有安装vim 参考地址:https://blog.csdn.net/lixinghua666/article/details/82289809
vim基本使用:https://www.cnblogs.com/msq2000/p/11781332.html
sudo apt install vim
2)使变量生效
source ~/.bashrc
3)检查
echo $JAVA_HOME
出现

安装Hadoop
1)下载hadoop-2.7.1.tar.gz 下载地址:链接: https://pan.baidu.com/s/1Nkp4hQEMWblKqdBvj-lUZA 密码: yy18
参考地址:https://blog.csdn.net/se7en_q/article/details/47258007
https://www.cnblogs.com/bybdz/p/9534079.html
2)我把文件放在了共享文件夹/media/sf_gx下,解压,放到/usr/local下
sudo tar -zxf /media/sf_gx/hadoop-2.7.1_64bit.tar.gz -C /usr/local
3)改名
cd /usr/local sudo mv ./hadoop-2.7.1 ./hadoop
4)修改权限(msq是我的用户名,根据你的实际情况修改)
sudo chown -R msq ./hadoop
5)在/usr/local/hadoop/目录下,建立tmp、hdfs/name、hdfs/data目录
cd /usr/local/hadoop mkdir tmp mkdir hdfs mkdir hdfs/data mkdir hdfs/name
6)Hadoop配置
进入/usr/local/hadoop/etc/hadoop目录,配置 hadoop-env.sh等。涉及的配置文件如下:
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
(1)配置core-site.xml
添加如下配置:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
(2)配置hdfs-site.xml
添加如下配置
<configuration>
<!—hdfs-site.xml-->
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>
(3)配置mapred-site.xml
这个文件初始时是没有的,有一个模板文件,mapred-site.xml.template
所以需要拷贝一份,并重命名为mapred-site.xml
添加如下配置:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(4)配置yarn-site.xml
添加如下配置:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>msq</value>
</property>
</configuration>
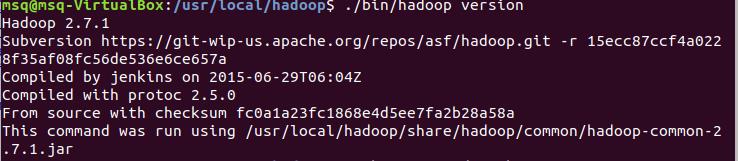
7)进入hadoop 查看版本信息
cd /usr/local/hadoop ./bin/hadoop version
8)启动hadoop
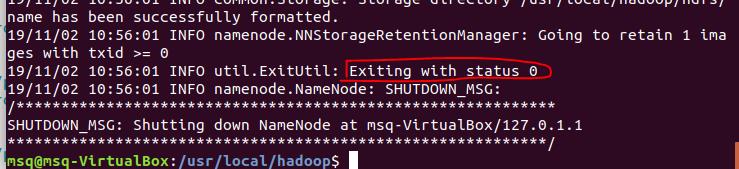
(1)格式化namenode
/usr/local/hadoop/bin/hdfs namenode -format
出现0代表成功
(2)启动NameNode 和 DataNode 守护进程(#是超级用户 $是一般用户)
$ ./sbin/start-dfs.sh
(3)启动ResourceManager 和 NodeManager 守护进程
$ ./sbin/start-yarn.sh
9)检查是否启动成功
jps
出现
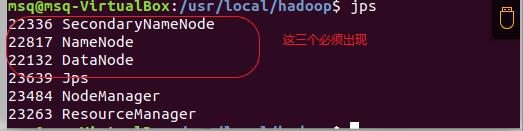
安装成功^.^
在浏览器中输入:localhost:50070/
出现
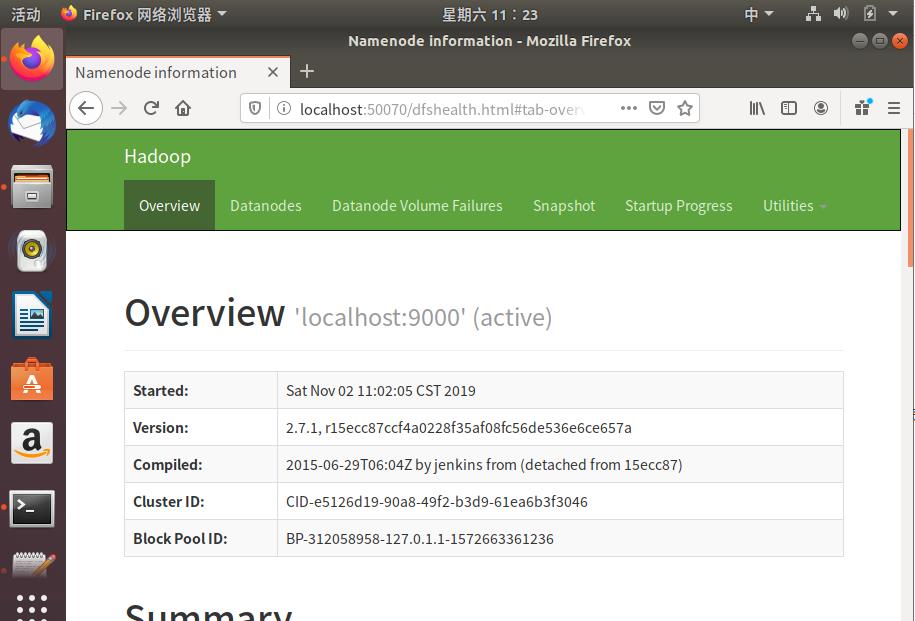
完美~~~
以上是关于安装Hadoop的主要内容,如果未能解决你的问题,请参考以下文章
如何从开源 Hadoop 构建 deb/rpm 存储库或由 ambari 安装的公开可用的 HDP 源代码
Android 插件化VirtualApp 源码分析 ( 目前的 API 现状 | 安装应用源码分析 | 安装按钮执行的操作 | 返回到 HomeActivity 执行的操作 )(代码片段