NOSQL之Memcached缓存服务实战精讲第一部
Posted 小熊尤里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NOSQL之Memcached缓存服务实战精讲第一部相关的知识,希望对你有一定的参考价值。
1.Memcached是一套数据缓存系统或软件。
用于在动态应用系统中缓存数据库的数据,减少数据库的访问压力,达到提升网站系统性能的目的;Memcached在企业应用场景中一般是用来作为数据库的cache服务使用;(但不是专门干这个,还可以干别的,主要是干这个,知道就好)

1)linux有特性,系统内存没有用完,利用这些内存就会缓存起来,所以剩余的内存为881
2)cache读缓存,磁盘数据读到缓存中;buffers写缓存,将数据写到缓存中,等到一定量的时候就写入磁盘中。
3)buffers同步到磁盘中,缓冲区的数据写入磁盘命令:sync,关机前多写几次
Memcached是通过预分配指定的内存空间来存取数据的,因此它比mysql这样数据库直接操作磁盘要快很多,可以提供比直接读取数据库更好的性能;还可作为集群节点session共享(会话保持)。
一般动态服务并发都不是很好,比如:.net 、java等。所以对于集群架构,数据库和存储都是容易出现瓶颈的。对于数据库就可以用memcache;对于存储可以是nginx。
| 软件 | 作用 | 缓存的数据 |
| memcached,redis | 后端数据库的缓存 | 动态的数据,例如:博文、bbs帖子 |
| squid,nginx,varnish | 前端web应用的缓存 | 静态数据缓存,例如图片、附件、js,css,html等 |
一般前端的CDN就是分布式缓存系统,同时节省网络带宽,
对于无论是memcached后端还是nginx等前端的缓存,如果我们做了修改,就会修改对应的存储或者数据库,但是我们访问的时候还是访问的缓存数据,这里就有一个数据一致性的问题。所以
1)对于后端memcached服务,在更新数据库的同时发送一个指标告知memcached数据过期了
2)一般存储类的图片等是不经常换的,如果有数据更新,都是起另外的别名进行操作即可。
memcached和redis的区别:
memcached是纯内存软件,重启就会丢失;redis是持久化软件,不仅存在内存中,而且也会存储到磁盘中。memcache是整个项目的名称。memcached是服务器端的主程序名。
2.关于memcached的会话缓存机制
例如php来说,将会话机制放到tmp中,是在php.ini进行配置,可以进行IP+端口,就可以改成从tmp到memchache的会话缓存
3.工作流程
内存是预先分配的,比如200M,是进行了初始化,读取是通过API的方式存取内存中缓存的这些数据,Memcached服务内存中缓存的数据就像一张巨大的HASH表,每条数据都是以key-value对的形式存在。
在读取会优先访问memchaced中的数据,没有命中,就会访问数据库,且给memcached一份。
当程序更新、删除数据库中已有的数据时,会同时发送请求通知memcached已经缓存过的同一个ID内容的旧数据失效,从而保证memcache中的数据和数据库中的数据一致。当然在高并发情况下,除了通知失效外,还会把数据推送到memcached中,下一个访问就直接memcached。
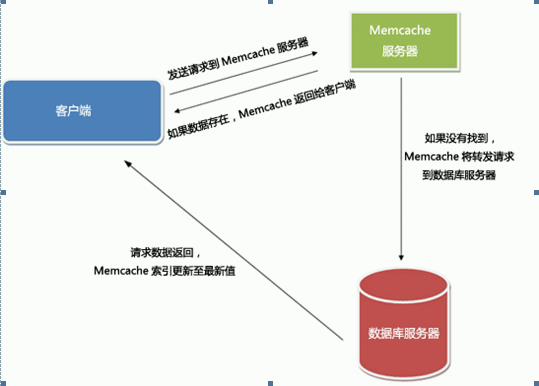
4.memcached服务在大型站点中的应用
几乎所有的网站,当访问量大的时候,在整个网站集群架构中最先出现瓶颈的一定是数据库角色的服务器以及存储角色的服务器,在工作中我们是尽量把用户的请求往前推,即越是在靠前用户端把数据返回就越好。
高并发访问的核心原则其实就一句化:“把所有的用户访问请求都尽量往前推”。
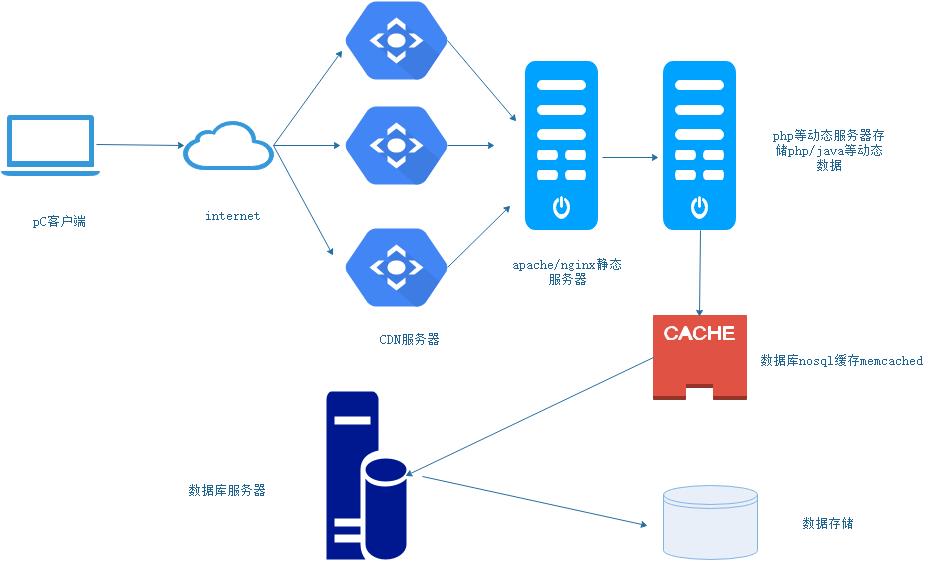
当然除了在前端加memcached以外,还要数据库层配置数据读写分离及读数据做负载均衡。对于单台memcache的内存容量是有限的,并且单台也是单点,因此,memcached也有负载均衡和应用场景。
分布式应用1
在应用服务器上通过程序及URL_HASH(固定在某一台服务器上)算法去访问Memcache服务,Memcached服务的地址池可以简单的配在程序的配置文件中
分布式应用2
门户如百度,会通过一个中间件代理负责请求后端的cache服务
分布式应用3
可以用常见的LVS,haproxy做Cache的负载均衡,和普通web应用服务相比,这里的重点是调用算法,Cache一般会选择url_hash及一致性hash算法。而web应用服务就是集群,对于不一样的放在NFS中,可以用轮询算法。如果memcache也用轮询算法,那么会慢的很多(个人理解,就算web应用都是不一样的,这样就现实,没用冗余性了,但是memcached是可以单点坏掉,直接请求数据库或者备用的memcached)
5.企业案例

如图所有,外部有爬虫,不停的自动输入查找内容,匹配的是如:like \'%杜冷门%\'的语句,这样的导致服务器负载很高,查询很慢,无法优化。
在linux下使用uptime查看,发现负载很高
登陆数据库查看:show processlist;show full processlist;
mysql -uroot -p\'1111\' -e "show full processlist"|grep -vi sleep
优化方案思路:
1)从业务上实现用户登陆后在搜索,这样减少搜索次数,减轻服务器压力
2)如果有大量频繁的搜索,一般是由爬虫在爬你的网站,分析web IP 封掉(部署awstats)
3) 配置主从同步,程序实现读写分离,减少主库压力
4)LIKE ‘\'%杜冷门%\'’ 这样的语句在mysql很难优化,可以通过搜索服务Sphinx实现搜索
5)在数据库前端加上memcached缓存服务器。
1)2)短期可解决 3)4)后期发展目标
6.Memcached的特性
libevent是一套利用C开发的程序库,支持大并发,memcached就是利用这个库进行异步事件处理。所以在安装的时候,需要先安装libenent,再安装memcached
memcached有一套自己管理内存的方式,这套管理方式非常高效,所有的数据都保存在Memcached内置的内存中,当存入的数据占满内存空间时,Memcached使用LRU算法自动删除不使用的缓存数据,即重用过期数据的内存空间。Memcached是为缓存系统设计的,因此,没有考虑数据的容灾问题,和机器的内存一样,重启机器数据将会丢失,如果希望重启数据依然保留,那么就需要sina网开发的memcachedb持久化内存缓存系统,当然还有redis、MongoDB等。
各个Memcached服务器之间互相不通信,都是独立的存取数据,不共享任何信息,通过客户端的设计,让Memcached具备分布式,能支持海量缓存和大规模应用。
7.Memcached软件工作原理
Memcached是一套C/S模式架构的软件,在服务器端启动服务守护进程,可以为memcached服务器指定监听的IP地址、端口号、并发访问连接数以及分配多少内存来处理客户端的请求的参数。
Memcached软件是由C语言开发的,全部代码仅有2000多行,采用的是异步I/O,其实现方法是基于事件的单进程和单线程的,使用libevent作为事件通知机制,多个服务器端可以协同工作,但这些服务器端之间是没有任何通信联系,每个服务器端只对自己的数据进行管理。应用程序端通过指定缓存服务器的IP地址和端口,就可以连接memcached服务相互通信。
需要被缓存的数据以Key/Value对的形式保存在服务器端预分配的内存区中,每个被缓存的数据都有唯一的标识key,操作Memcached中的数据通过这个唯一标识的key进行。缓存到Memcached中的数据仅放置在Memcached服务预分配的内存中,而非存储在memcached所在的磁盘上,速度很快。
由于Memcached服务自身没有对缓存的数据进行持久性存储的设计,因此,在服务器重启的时候,会丢失,而且如果容量达到设定的值,就会使用LRU算法删除过期的缓存数据。
当初就是为缓存而设计的,所以没有考虑永久性问题;
memcached支持各种客户端shell,php,java,python都可连接memecached.
8.Memcached内存管理机制
Memcached利用Slab Allocation 机制来分配和管理内存。传统的内存管理方式是:使用完通过malloc分配的内存后通过free来回收内存。这种方式容易产生内存碎片并降低操作系统对内存的管理效率。Slab Allocation机制不存在这样的问题,它按照预先规定的大小,将分配的内存分割成特定长度的内存块,再把尺寸相同的内存块分成组,这些内存块不会释放,可以重复利用。
Memcached服务端保存着一个空闲的内存块列表,当有数据存入时根据接收到的数据大小,分配一个能存下这个数据的最小内存块,这种方式有时会造成内存浪费,避免浪费的方式:
1)把同一个业务类型的数据存入一个Memcached服务器中,确保存入的数据大小相对均匀
2)指定 -f 参数 能再某种程度上控制这个差异,一般不设置,就用默认的1.25
9.Memcached的删除机制
Memcached不会释放已分配的内存空间(除非添加数据设定过期或内存缓存满了),再数据过期后,客户端不能通过key取出它的值,其存储空间被重新利用。
Memcached使用的是一种Lazy Expiration策略,自己不会监控存入的key/value对是否过期,而是再获取key值时查看记录的时间戳,检查key/value对空间是否过期,这种策略不会再过期检测上不浪费CPU资源。
Memcached在分配空间时,优先使用已经过期的key/value对空间,当分配的内存空间占满时,Memcached就会使用LRU算法来分配空间,删除最近最少使用的key/value对,将其空间分配给新的key/value对,在某些情况下,如果不想使用LRU算法,那么可以通过-M参数来启动Memcached,这样Memcached在内存耗尽时,会返回一个报错信息。
以上是关于NOSQL之Memcached缓存服务实战精讲第一部的主要内容,如果未能解决你的问题,请参考以下文章