写时复制技术最初产生于Unix系统,用于实现一种傻瓜式的进程创建:当发出fork( )系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程。这种行为是非常耗时的,因为它需要:
· 为子进程的页表分配页面
· 为子进程的页分配页面
· 初始化子进程的页表
· 把父进程的页复制到子进程相应的页中
创建一个地址空间的这种方法涉及许多内存访问,消耗许多CPU周期,并且完全破坏了高速缓存中的内容。在大多数情况下,这样做常常是毫无意义的,因为许多子进程通过装入一个新的程序开始它们的执行,这样就完全丢弃了所继承的地址空间。
现在的Unix内核(包括Linux),采用一种更为有效的方法称之为写时复制(或COW)。这种思想相当简单:父进程和子进程共享页面而不是复制 页面。然而,只要页面被共享,它们就不能被修改。无论父进程和子进程何时试图写一个共享的页面,就产生一个错误,这时内核就把这个页复制到一个新的页面中 并标记为可写。原来的页面仍然是写保护的:当其它进程试图写入时,内核检查写进程是否是这个页面的唯一属主;如果是,它把这个页面标记为对这个进程是可写 的。
1. Linux的fork()使用写时复制
传统的fork()系统调用直接把所有的资源复制给新创建的进程。这种实现过于简单并且效率低下,因为它拷贝的数据或许可以共享(This approach is significantly naïve and inefficient in that it copies much data that might otherwise be shared.)。更糟糕的是,如果新进程打算立即执行一个新的映像,那么所有的拷贝都将前功尽弃。Linux的fork()使用写时拷贝(copy- on-write)页实现。写时拷贝是一种可以推迟甚至避免拷贝数据的技术。内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间。只 用在需要写入的时候才会复制地址空间,从而使各个进行拥有各自的地址空间。也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共 享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。在页根本不会被写入的情况下---例如,fork()后立即执行exec(),地址空间 就无需被复制了。fork()的实际开销就是复制父进程的页表以及给子进程创建一个进程描述符。在一般情况下,进程创建后都为马上运行一个可执行的文件, 这种优化,可以避免拷贝大量根本就不会被使用的数据(地址空间里常常包含数十兆的数据)。由于Unix强调进程快速执行的能力,所以这个优化是很重要的。
COW技术初窥:
在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,linux中引入了“写时复制“技术,也就是只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
那么子进程的物理空间没有代码,怎么去取指令执行exec系统调用呢?
在fork之后exec之前两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间 不同,但其对应的物理空间是同一个。当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间,如果不是因为exec,内核会给子进程的数 据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。而如果是因为 exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
在网上看到还有个细节问题就是,fork之后内核会通过将子进程放在队列的前面,以让子进程先执行,以免父进程执行导致写时复制,而后子进程执行exec系统调用,因无意义的复制而造成效率的下降。
COW详述:
现在有一个父进程P1,这是一个主体,那么它是有灵魂也就身体的。现在在其虚拟地址空间(有相应的数据结构表示)上有:正文段,数据段,堆,栈这四个部 分,相应的,内核要为这四个部分分配各自的物理块。即:正文段块,数据段块,堆块,栈块。至于如何分配,这是内核去做的事,在此不详述。
1. 现在P1用fork()函数为进程创建一个子进程P2,
内核:
(1)复制P1的正文段,数据段,堆,栈这四个部分,注意是其内容相同。
(2)为这四个部分分配物理块,P2的:正文段->PI的正文段的物理块,其实就是不为P2分配正文段块,让P2的正文段指向P1的正文段块,数据 段->P2自己的数据段块(为其分配对应的块),堆->P2自己的堆块,栈->P2自己的栈块。如下图所示:同左到右大的方向箭头表示复制内容。
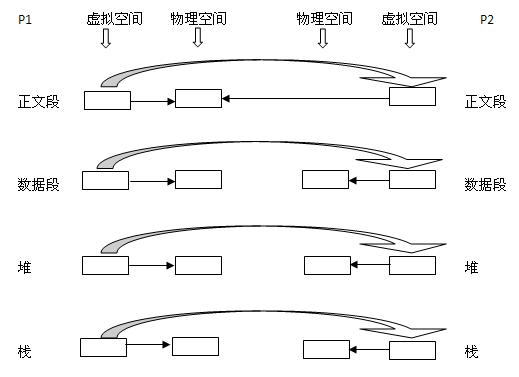
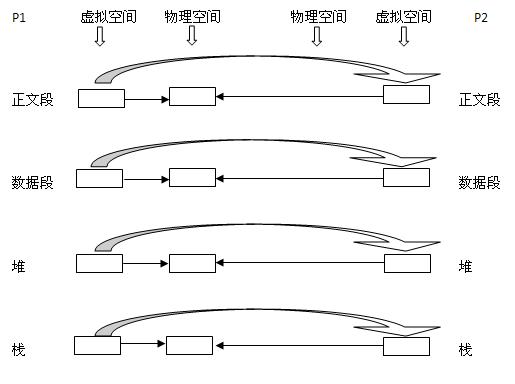
2. 写时复制技术:内核只为新生成的子进程创建虚拟空间结构,它们来复制于父进程的虚拟究竟结构,但是不为这些段分配物理内存,它们共享父进程的物理空间,当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间。
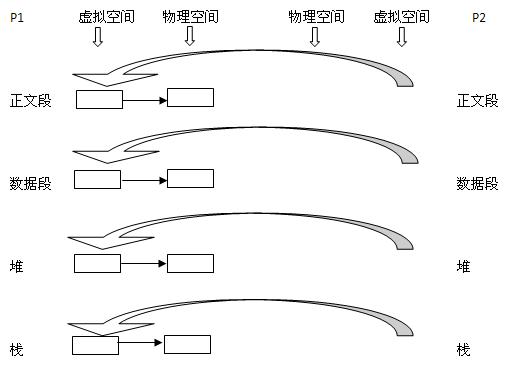
3. vfork():这个做法更加火爆,内核连子进程的虚拟地址空间结构也不创建了,直接共享了父进程的虚拟空间,当然了,这种做法就顺水推舟的共享了父进程的物理空间
通过以上的分析,相信大家对进程有个深入的认识,它是怎么一层层体现出自己来的,进程是一个主体,那么它就有灵魂与身体,系统必须为实现它创建相应的实体, 灵魂实体与物理实体。这两者在系统中都有相应的数据结构表示,物理实体更是体现了它的物理意义。
补充一点:Linux COW与exec没有必然联系
PS:实际上COW技术不仅仅在Linux进程上有应用,其他例如C++的String在有的IDE环境下也支持COW技术,即例如:
string str1 = "hello world"; string str2 = str1;
之后执行代码:
str1[1]=\'q\'; str2[1]=\'w\';
在开始的两个语句后,str1和str2存放数据的地址是一样的,而在修改内容后,str1的地址发生了变化,而str2的地址还是原来的,这就是C++中的COW技术的应用,不过VS2005似乎已经不支持COW。
2. fork()函数
头文件
- #include<unistd.h>
- #include<sys/types.h>
函数原型
- pid_t fork( void);
(pid_t 是一个宏定义,其实质是int 被定义在#include<sys/types.h>中)
返回值: 若成功调用一次则返回两个值,子进程返回0,父进程返回子进程ID;否则,出错返回-1
口诀: 父返子,子返0,fork出错返-1
示例代码
- #include<sys/types.h> //对于此程序而言此头文件用不到
- #include<unistd.h>
- #include<stdio.h>
- #include<stdlib.h>
- int main(int argc, charchar ** argv ){
- //由于会返回两次,下面的代码会被执行两遍
- //如果成功创建子进程:
- //1. 父进程返回子进程ID,因此(父进程)会走一遍“分支3”
- //2. 子进程返回0,因此(子进程)会走一遍“分支2”
- pid_t pid = fork();
- if (pid < 0){ //分支1
- fprintf(stderr, "error!");
- }else if( 0 == pid ){//分支2
- printf("This is the child process!");
- _exit(0);
- }else{//分支3
- printf("This is the parent process! child process id = %d", pid);
- }
- //可能需要时候wait或waitpid函数等待子进程的结束并获取结束状态
- exit(0);
- }
注意!样例代码仅供参考,样例代码存在着父进程在子进程结束前结束的可能性。必要的时候可以使用wait或 waitpid函数让父进程等待子进程的结束并获取子进程的返回状态。
fork的另一个特性是所有由父进程打开的描述符都被复制到子进程中。父、子进程中相同编号的文件描述符在内核中指向同一个file结构体,也就是说,file结构体的引用计数要增加。
3. Linux的fork()使用写时复制(详)
fork函数用于创建子进程,典型的调用一次,返回两次的函数,其中返回子进程的PID和0,其中调用进程返回了子进程的PID,而子 进程则返回了0,这是一个比较有意思的函数,但是两个进程的执行顺序是不定的。fork()函数调用完成以后父进程的虚拟存储空间被拷贝给了子进程的虚拟 存储空间,因此也就实现了共享文件等操作。但是虚拟的存储空间映射到物理存储空间的过程中采用了写时拷贝技术(具体的操作大小是按着页控制的),该技术主 要是将多进程中同样的对象(数据)在物理存储其中只有一个物理存储空间,而当其中的某一个进程试图对该区域进行写操作时,内核就会在物理存储器中开辟一个 新的物理页面,将需要写的区域内容复制到新的物理页面中,然后对新的物理页面进行写操作。这时就是实现了对不同进程的操作而不会产生影响其他的进程,同时 也节省了很多的物理存储器。
- #include<stdio.h>
- #include<stdlib.h>
- #include<unistd.h>
- #include<fcntl.h>
- #include<sys/types.h>
- #include<sys/stat.h>
- int main(){
- char p = \'p\';
- int number = 11;
- if(fork()==0) /*子进程*/
- {
- p = \'c\'; /*子进程对数据的修改*/
- printf("p = %c , number = %d \\n ",p,number);
- exit(0);
- }
- /*父进程*/
- number = 14; /*父进程对数据修改*/
- printf("p = %c , number = %d \\n ",p,number);
- exit(0);
- }
- $ gcc -g TestWriteCopyTech.c -o TestWriteCopyTech
- $ ./TestWriteCopyTech
- p = p , number = 14 -----父进程打印内容
- $ p = c , number = 11 -----子进程打印内容
原因分析:
由于存在企图进行写操作的部分,因此会发生写时拷贝过程,子进程中对数据的修改,内核就会创建一个新的物理内存空间。然后再次将数据写入到新的物理内存空
间中。可知,对新的区域的修改不会改变原有的区域,这样不同的空间就区分开来。但是没有修改的区域仍然是多个进程之间共享。
fork()函数的代码段基本是只读类型的,而且在运行阶段也只是复制,并不会对内容进行修改,因此父子进程是共享代码段,而数据段、Bss段、堆栈段等会在运行的过程中发生写过程,这样就导致了不同的段发生相应的写时拷贝过程,实现了不同进程的独立空间。
但是需要注意的是文件操作,由于文件的操作是通过文件描述符表、文件表、v-node表三个联系起来控制的,其中文件表、v-node表是所有的进程共
享,而每个进程都存在一个独立的文件描述符表。父子进程虚拟存储空间的内容是大致相同的,父子进程是通过同一个物理区域存储文件描述符表,但如果修改文件
描述符表,也会发生写时拷贝操作,只有这样才能保证子进程中对文件描述符的修改,不会影响到父进程的文件描述符表。例如close操作,因为close会
导致文件的描述符的值发生变化,相当于发生了写操作,这是产生了写时拷贝过程,实现新的物理空间,然后再次发生close操作,这样就不会产生子进程中文
件描述符的关闭而导致父进程不能访问文件。
测试函数:
- #include<stdio.h>
- #include<stdlib.h>
- #include<unistd.h>
- #include<sys/types.h>
- #include<sys/stat.h>
- #include<fcntl.h>
- #include<sys/wait.h>
- int main(){
- int fd;
- char c[3];
- charchar *s = "TestFs";
- fd = open("foobar.txt",O_RDWR,0);
- if(fork()==0) //子进程
- {
- fd = 1;//stdout
- write(fd,s,7);
- exit(0);
- }
- //父进程
- read(fd,c,2);
- c[2]=\'\\0\';
- printf("c = %s\\n",c);
- exit(0);
- }
编译运行:
- $ gcc -g fileshare2.c -o fileshare2
- $ ./fileshare2
- c = fo ----foobar.txt中的内容
- $ TestFs ---标准输出
原因分析:由于父子进程的文件描述符表是相同的,但是在子进程中对fd(文件描述符表中的项)进行了修改,这时会发生写时拷贝过程,内核在物理内存中分配
一个新的页面存储子进程原文件描述符fd存在页面的内容,然后再进修写操作,实现将fd修改为1,也就是标准输出。但是父进程的fd并没有发生改变,还是
与其他的子进程共享文件描述符表,因此仍然是对文件foobar.txt进行操作。
因此需要注意fork()函数实质上是按着写时拷贝的方式实现文件的映射,并不是共享,写时拷贝操作使得内存的需求量大大的减少了,具体的写时拷贝实现,请参看非常经典的“深入理解计算机系统”的第622页。