1 MMM 介绍
1.1 简介
MMM 是一套支持双主故障切换以及双主日常管理的第三方软件。MMM 由 Perl 开发,用来管理和监控双主复制,虽然是双主架构,但是业务上同一时间只允许一个节点进行写入操作。
MMM 包含两类角色: writer 和 reader, 分别对应读写节点和只读节点。
使用 MMM 管理双主节点的情况下,当 writer 节点出现宕机(假定是 master1),程序会自动移除该节点上的读写 VIP,切换到 Master2 ,并设置 Master2 为 read_only = 0, 同时,所有 Slave 节点会指向 Master2。
除了管理双主节点,MMM 也会管理 Slave 节点,在出现宕机、复制延迟或复制错误,MMM 会移除该节点的 VIP,直到节点恢复正常。
1.2 组件
MMM 由两类程序组成
monitor: 监控集群内数据库的状态,在出现异常时发布切换命令,一般和数据库分开部署agent: 运行在每个 mysql 服务器上的代理进程,monitor 命令的执行者,完成监控的探针工作和具体服务设置,例如设置 VIP、指向新同步节点
其架构如下:
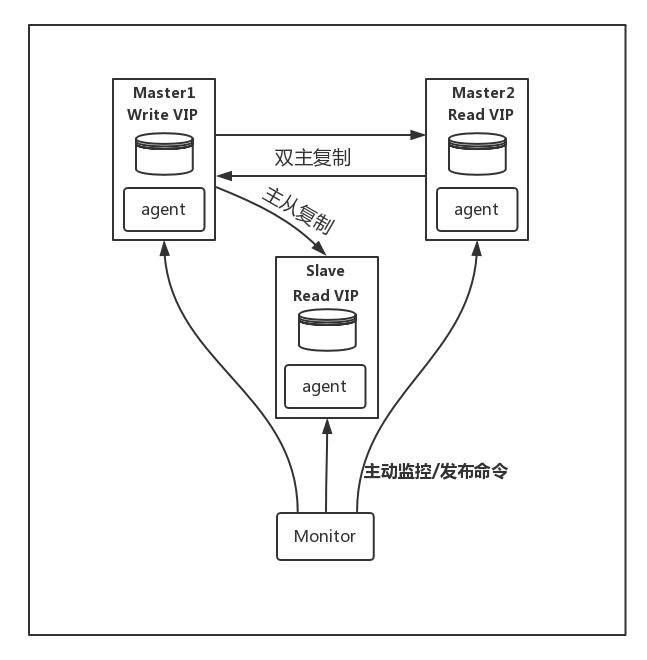
1.3 切换流程
以上述架构为例,描述一下故障转移的流程,现在假设 Master1 宕机
- Monitor 检测到 Master1 连接失败
- Monitor 发送 set_offline 指令到 Master1 的 Agent
- Master1 Agent 如果存活,下线写 VIP,尝试把 Master1 设置为
read_only=1 - Moniotr 发送 set_online 指令到 Master2
- Master2 Agent 接收到指令,执行
select master_pos_wait()等待同步完毕 - Master2 Agent 上线写 VIP,把 Master2 节点设为
read_only=0 - Monitor 发送更改同步对象的指令到各个 Slave 节点的 Agent
- 各个 Slave 节点向新 Master 同步数据
从整个流程可以看到,如果主节点出现故障,MMM 会自动实现切换,不需要人工干预,同时我们也能看出一些问题,就是数据库挂掉后,只是做了切换,不会主动补齐丢失的数据,所以 MMM 会有数据不一致性的风险。
2 MMM 安装
2.1 yum 安装
如果服务器能连网或者有合适 yum 源,直接执行以下命令安装
# 增加 yum 源(如果默认 yum 源有,这一步可以忽略)
yum install epel-release.noarch
# 在 agent 节点执行
yum install -y mysql-mmm-agent
# 在 monitor 节点执行
yum install -y mysql-mmm-monitor
执行该安装命令,会安装以下软件包或依赖
mysql-mmm-agent.noarch 0:2.2.1-1.el5
libart_lgpl.x86_64 0:2.3.17-4
mysql-mmm.noarch 0:2.2.1-1.el5
perl-Algorithm-Diff.noarch 0:1.1902-2.el5
perl-DBD-mysql.x86_64 0:4.008-1.rf
perl-DateManip.noarch 0:5.44-1.2.1
perl-IPC-Shareable.noarch 0:0.60-3.el5
perl-Log-Dispatch.noarch 0:2.20-1.el5
perl-Log-Dispatch-FileRotate.noarch 0:1.16-1.el5
perl-Log-Log4perl.noarch 0:1.13-2.el5
perl-MIME-Lite.noarch 0:3.01-5.el5
perl-Mail-Sender.noarch 0:0.8.13-2.el5.1
perl-Mail-Sendmail.noarch 0:0.79-9.el5.1
perl-MailTools.noarch 0:1.77-1.el5
perl-Net-ARP.x86_64 0:1.0.6-2.1.el5
perl-Params-Validate.x86_64 0:0.88-3.el5
perl-Proc-Daemon.noarch 0:0.03-1.el5
perl-TimeDate.noarch 1:1.16-5.el5
perl-XML-DOM.noarch 0:1.44-2.el5
perl-XML-Parser.x86_64 0:2.34-6.1.2.2.1
perl-XML-RegExp.noarch 0:0.03-2.el5
rrdtool.x86_64 0:1.2.27-3.el5
rrdtool-perl.x86_64 0:1.2.27-3.el5
其他系统安装方式可以参考官网
2.2 手动安装
1). 下载安装包
进入 MMM 下载页面 Downloads MMM for MySQL,点击下载,如图
下载完成上传到服务器上
2). 安装依赖
yum install -y wget perl openssl gcc gcc-c++
wget http://xrl.us/cpanm --no-check-certificate
mv cpanm /usr/bin
chmod 755 /usr/bin/cpanm
cat > /root/list << EOF
install Algorithm::Diff
install Class::Singleton
install DBI
install DBD::mysql
install File::Basename
install File::stat
install File::Temp
install Log::Dispatch
install Log::Log4perl
install Mail::Send
install Net::ARP
install Net::Ping
install Proc::Daemon
install Thread::Queue
install Time::HiRes
EOF
for package in `cat /root/list`
do
cpanm $package
done
3). 安装
tar -xvf mysql-mmm-2.2.1.tar.gz
cd mysql-mmm-2.2.1
make install
ps: 大部分时候,数据库机器都是不允许连接外网的,这个时候只能把上述依赖的 RPM 包一个个下载下来拷到服务器上
3 数据库环境准备
操作前已经准备好了一套主主从架构的数据库,搭建方法可以参考以往文章,具体信息如下
节点信息
| IP | 系统 | 端口 | MySQL版本 | 节点 | 读写 | 说明 |
|---|---|---|---|---|---|---|
| 10.0.0.247 | Centos6.5 | 3306 | 5.7.9 | Master | 读写 | 主节点 |
| 10.0.0.248 | Centos6.5 | 3306 | 5.7.9 | Standby | 只读,可切换为读写 | 备主节点 |
| 10.0.0.249 | Centos6.5 | 3306 | 5.7.9 | Slave | 只读 | 从节点 |
| 10.0.0.24 | Centos6.5 | - | - | monitor | - | MMM Monitor |
VIP 信息
| 简称 | VIP | 类型 |
|---|---|---|
| RW-VIP | 10.0.0.237 | 读写VIP |
| RO-VIP1 | 10.0.0.238 | 读VIP |
| RO-VIP2 | 10.0.0.239 | 读VIP |
架构图
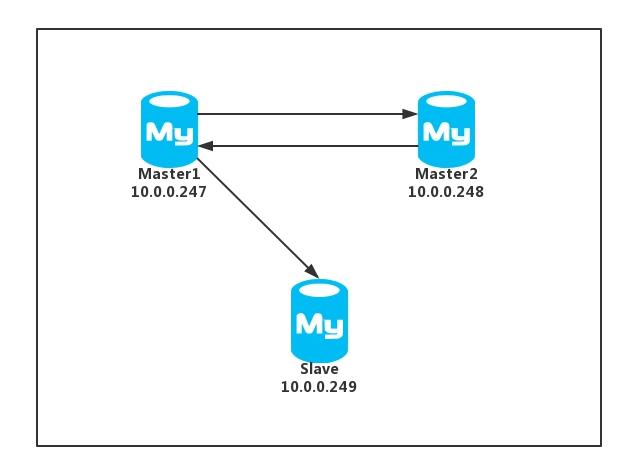
参考配置
Master1
[client]
port = 3306
default-character-set=utf8mb4
socket = /data/mysql_db/test_mmm/mysql.sock
[mysqld]
datadir = /data/mysql_db/test_mmm
basedir = /usr/local/mysql57
tmpdir = /tmp
socket = /data/mysql_db/test_mmm/mysql.sock
pid-file = /data/mysql_db/test_mmm/mysql.pid
skip-external-locking = 1
skip-name-resolve = 1
port = 3306
server_id = 2473306
default-storage-engine = InnoDB
character-set-server = utf8mb4
default_password_lifetime=0
auto_increment_offset = 1
auto_increment_increment = 2
#### log ####
log_timestamps=system
log_bin = /data/mysql_log/test_mmm/mysql-bin
log_bin_index = /data/mysql_log/test_mmm/mysql-bin.index
binlog_format = row
relay_log_recovery=ON
relay_log=/data/mysql_log/test_mmm/mysql-relay-bin
relay_log_index=/data/mysql_log/test_mmm/mysql-relay-bin.index
log_error = /data/mysql_log/test_mmm/mysql-error.log
#### replication ####
log_slave_updates = 1
replicate_wild_ignore_table = information_schema.%,performance_schema.%,sys.%
#### semi sync replication settings #####
plugin_dir=/usr/local/mysql57/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
loose_rpl_semi_sync_master_enabled = 1
loose_rpl_semi_sync_slave_enabled = 1
Master2
[client]
port = 3306
default-character-set=utf8mb4
socket = /data/mysql_db/test_mmm/mysql.sock
[mysqld]
datadir = /data/mysql_db/test_mmm
basedir = /usr/local/mysql57
tmpdir = /tmp
socket = /data/mysql_db/test_mmm/mysql.sock
pid-file = /data/mysql_db/test_mmm/mysql.pid
skip-external-locking = 1
skip-name-resolve = 1
port = 3306
server_id = 2483306
default-storage-engine = InnoDB
character-set-server = utf8mb4
default_password_lifetime=0
auto_increment_offset = 2
auto_increment_increment = 2
#### log ####
log_timestamps=system
log_bin = /data/mysql_log/test_mmm/mysql-bin
log_bin_index = /data/mysql_log/test_mmm/mysql-bin.index
binlog_format = row
relay_log_recovery=ON
relay_log=/data/mysql_log/test_mmm/mysql-relay-bin
relay_log_index=/data/mysql_log/test_mmm/mysql-relay-bin.index
log_error = /data/mysql_log/test_mmm/mysql-error.log
#### replication ####
log_slave_updates = 1
replicate_wild_ignore_table = information_schema.%,performance_schema.%,sys.%
#### semi sync replication settings #####
plugin_dir=/usr/local/mysql57/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
loose_rpl_semi_sync_master_enabled = 1
loose_rpl_semi_sync_slave_enabled = 1
Slave
[client]
port = 3306
default-character-set=utf8mb4
socket = /data/mysql_db/test_mmm/mysql.sock
[mysqld]
datadir = /data/mysql_db/test_mmm
basedir = /usr/local/mysql57
tmpdir = /tmp
socket = /data/mysql_db/test_mmm/mysql.sock
pid-file = /data/mysql_db/test_mmm/mysql.pid
skip-external-locking = 1
skip-name-resolve = 1
port = 3306
server_id = 2493306
default-storage-engine = InnoDB
character-set-server = utf8mb4
default_password_lifetime=0
read_only=1
#### log ####
log_timestamps=system
log_bin = /data/mysql_log/test_mmm/mysql-bin
log_bin_index = /data/mysql_log/test_mmm/mysql-bin.index
binlog_format = row
relay_log_recovery=ON
relay_log=/data/mysql_log/test_mmm/mysql-relay-bin
relay_log_index=/data/mysql_log/test_mmm/mysql-relay-bin.index
log_error = /data/mysql_log/test_mmm/mysql-error.log
#### replication ####
log_slave_updates = 1
replicate_wild_ignore_table = information_schema.%,performance_schema.%,sys.%
#### semi sync replication settings #####
plugin_dir=/usr/local/mysql57/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
loose_rpl_semi_sync_master_enabled = 1
loose_rpl_semi_sync_slave_enabled = 1
新建用户
在主节点中执行下列建立 MMM 用户的命令,由于是测试环境,密码就设为和账号一样
CREATE USER \'mmm_monitor\'@\'%\' IDENTIFIED BY \'mmm_monitor\';
CREATE USER \'mmm_agent\'@\'%\' IDENTIFIED BY \'mmm_agent\';
GRANT REPLICATION CLIENT ON *.* TO \'mmm_monitor\'@\'%\';
GRANT SUPER, REPLICATION CLIENT, PROCESS ON *.* TO \'mmm_agent\'@\'%\';
FLUSH PRIVILEGES;
4 配置 MMM
4.1 配置文件
MMM 有3个配置文件,分别是 mmm_agent.conf, mmm_common.conf, mmm_mon.conf, 在目录 /etc/mysql-mmm 下。如果区分集群,也就是说一台服务器跑多个 MMM,那么配置文件可以这样命名 mmm_agent_cluster.conf, mmm_common_cluster.conf, mmm_mon_cluster.conf, 其中 cluster 表示集群名称
mmm_common.conf, 通用配置,在所有 MMM 节点都需要mmm_agent.conf, agent 配置,在 MMM Agent 节点需要mmm_mon.conf, monitor 配置,在 MMM Monitor 节点需要
这次配置,我们把集群名命名为 test_mmm, 下面是具体配置
mmm_common
在所有节点新建 /etc/mysql-mmm/mmm_common_test_mmm.conf, 根据实际情况写上
active_master_role writer
<host default>
cluster_interface eth0 # 群集的网络接口
agent_port 9989 # agent 监听端口,如果有多个 agent,需要更改默认端口
mysql_port 3306 # 数据库端口,默认为3306
pid_path /var/run/mysql-mmm/mmm_agentd_test_mmm.pid # pid路径, 要和启动文件对应
bin_path /usr/libexec/mysql-mmm # bin 文件路径
replication_user repl # 复制用户
replication_password repl # 复制用户密码
agent_user mmm_agent # 代理用户,用来设置 `read_only` 等
agent_password mmm_agent # 代理用户密码
</host>
<host cluster01> # master1 的 host 名
ip 10.0.0.247 # master1 的 ip
mode master # 角色属性,master 代表是主节点
peer cluster02 # 与 master1 对等的服务器的 host 名,双主中另一个的主机名
</host>
<host cluster02> # master2 的 host 名
ip 10.0.0.248 # master2 的 ip
mode master # 角色属性,master 代表是主节点
peer cluster01 # 与 master2 对等的服务器的 host 名,双主中另一个的主机名
</host>
<host cluster03> # slave 的 host 名
ip 10.0.0.249 # slave 的 ip
mode slave # 角色属性,slave 代表是从节点
</host>
<role writer> # writer 角色配置
hosts cluster01, cluster02 # 能进行写操作的服务器的 host 名
ips 10.0.0.237 # writer 的 VIP
mode exclusive # exclusive 代表只允许存在一个主节点(写节点),也就是只能提供一个写的 VIP
</role>
<role reader> # writer 角色配置
hosts cluster01, cluster02, cluster03 # 能进行读操作的服务器的 host 名
ips 10.0.0.238,10.0.0.239 # reader 的 VIP
mode balanced # balanced 代表负载均衡可以多个 host 同时拥有此角色
</role>
mmm_agent
在所有 agent 的节点新建 /etc/mysql-mmm/mmm_agent_test_mmm.conf 文件,写上以下内容
- Cluster1
include mmm_common_test_mmm.conf # common 文件名,对应上述写下的文件
this cluster01 # 当前节点名称,对应 common 文件 host 名
- Cluster2
include mmm_common_test_mmm.conf
this cluster02
- Cluster3
include mmm_common_test_mmm.conf
this cluster03
mmm_mon
在 monitor 节点新建 /etc/mysql-mmm/mmm_mon_test_mmm.conf 文件,写下监控节点配置
include mmm_common_test_mmm.conf # common 文件名
<monitor>
ip 127.0.0.1 # 监听 IP
port 9992 # 监听端口
pid_path /var/run/mysql-mmm/mmm_mond_test_mmm.pid # PID 文件位置, 要和启动文件对应
bin_path /usr/libexec/mysql-mmm # bin目录
status_path /var/lib/mysql-mmm/mmm_mond_test_mmm.status # 状态文件位置
ping_ips 10.0.0.247, 10.0.0.248, 10.0.0.249 # 需要监控的主机 IP,对应 MySQL 节点 IP
auto_set_online 30 # 自动恢复 online 的时间
</monitor>
<host default>
monitor_user mmm_monitor # 监控用的 MySQL 账号
monitor_password mmm_monitor # 监控用的 MySQL 密码
</host>
<check mysql>
check_period 2 # 监控周期
trap_period 4 # 一个节点被检测不成功的时间持续 trap_period 秒,就认为失去连接
max_backlog 900 # 主从延迟超过这个值就会设为 offline
</check>
debug 0 # 是否开启 debug 模式
PS1: 以上配置文件在使用的时候需要去掉注释
PS2: 如果只有一个集群,可以在默认配置文件上改
4.2 启动文件
安装成功后,会在 /etc/init.d/ 下生成配置启动文件
[root@chengqm ~]# ls /etc/init.d/mysql*
/etc/init.d/mysqld /etc/init.d/mysql-mmm-agent /etc/init.d/mysql-mmm-monitor
mysql-mmm-agent
在所有 agent 节点执行
cp /etc/init.d/mysql-mmm-agent /etc/init.d/mysql-mmm-agent-test-mmm
打开 /etc/init.d/mysql-mmm-agent-test-mmm, 如果你的配置文件头部是这样的
CLUSTER=\'\'
#-----------------------------------------------------------------------
# Paths
if [ "$CLUSTER" != "" ]; then
MMM_AGENTD_BIN="/usr/sbin/mmm_agentd @$CLUSTER"
MMM_AGENTD_PIDFILE="/var/run/mmm_agentd-$CLUSTER.pid"
else
MMM_AGENTD_BIN="/usr/sbin/mmm_agentd"
MMM_AGENTD_PIDFILE="/var/run/mmm_agentd.pid"
fi
echo "Daemon bin: \'$MMM_AGENTD_BIN\'"
echo "Daemon pid: \'$MMM_AGENTD_PIDFILE\'"
改为
CLUSTER=\'test_mmm\'
#-----------------------------------------------------------------------
# Paths
if [ "$CLUSTER" != "" ]; then
MMM_AGENTD_BIN="/usr/sbin/mmm_agentd @$CLUSTER"
MMM_AGENTD_PIDFILE="/var/run/mysql-mmm/mmm_agentd_$CLUSTER.pid"
else
MMM_AGENTD_BIN="/usr/sbin/mmm_agentd"
MMM_AGENTD_PIDFILE="/var/run/mysql-mmm/mmm_agentd.pid"
fi
echo "Daemon bin: \'$MMM_AGENTD_BIN\'"
echo "Daemon pid: \'$MMM_AGENTD_PIDFILE\'"
如果打开发现是这样的
MMMD_AGENT_BIN="/usr/sbin/mmm_agentd"
MMMD_AGENT_PIDFILE="/var/run/mysql-mmm/mmm_agentd.pid"
LOCKFILE=\'/var/lock/subsys/mysql-mmm-agent\'
prog=\'MMM Agent Daemon\'
改为
...
CLUSTER=\'test_mmm\'
MMMD_AGENT_BIN="/usr/sbin/mmm_agentd @$CLUSTER"
MMMD_AGENT_PIDFILE="/var/run/mysql-mmm/mmm_agentd_$CLUSTER.pid"
LOCKFILE=\'/var/lock/subsys/mysql-mmm-agent_CLUSTER$\'
prog=\'MMM Agent Daemon\'
mysql-mmm-monitor
在 monitor 节点执行
cp /etc/init.d/mysql-mmm-monitor /etc/init.d/mysql-mmm-monitor-test-mmm
打开 /etc/init.d/mysql-mmm-monitor-test-mmm, 把文件开始部分改为
# Cluster name (it can be empty for default cases)
CLUSTER=\'test_mmm\'
LOCKFILE="/var/lock/subsys/mysql-mmm-monitor-${CLUSTER}"
prog=\'MMM Monitor Daemon\'
if [ "$CLUSTER" != "" ]; then
MMMD_MON_BIN="/usr/sbin/mmm_mond @$CLUSTER"
MMMD_MON_PIDFILE="/var/run/mysql-mmm/mmm_mond_$CLUSTER.pid"
else
MMMD_MON_BIN="/usr/sbin/mmm_mond"
MMMD_MON_PIDFILE="/var/run/mysql-mmm/mmm_mond.pid"
fi
start() {
...
如果打开启动文件发现和本文的启动文件有出入,可以根据实际情况进行修改,确保启动 monitor 命令为 /usr/sbin/mmm_mond @$CLUSTER 且 pid 文件和配置文件一致即可
PS: 如果只有一个集群,可以直接使用默认启动文件
注意: 配置文件的 PID 文件位置要和启动文件的 PID 文件位置要一致,如果不一致就改为一致
5 启动 MMM
启动 MMM 的顺序是
- 启动 MMM Monitor
- 启动 MMM Agent
关闭 MMM 的顺序则反过来执行
5.1 启动 Monitor
在 monitor 节点上执行启动命令,示例如下
[root@chengqm ~]# /etc/init.d/mysql-mmm-monitor-test-mmm start
Starting MMM Monitor Daemon: [ OK ]
如果启动有报错查看 mmm 日志,mmm 日志放在 /var/log/mysql-mmm/ 目录下
5.2 启动 Agent
在所有 agent 节点执行启动命令,示例如下
[root@cluster01 ~]# /etc/init.d/mysql-mmm-agent-test-mmm start
Daemon bin: \'/usr/sbin/mmm_agentd @test_mmm\'
Daemon pid: \'/var/run/mmm_agentd-test_mmm.pid\'
Starting MMM Agent daemon... Ok
5.3 观察 mmm 状态
在 monitor 节点执行 mmm_control @cluster show 命令查看各节点状态
[root@chengqm ~]# mmm_control @test_mmm show
cluster01(10.0.0.247) master/ONLINE. Roles: reader(10.0.0.238), writer(10.0.0.237)
cluster02(10.0.0.248) master/ONLINE. Roles: reader(10.0.0.239)
cluster03(10.0.0.249) slave/ONLINE. Roles:
在 monitor 节点执行 mmm_control @cluster checks all 命令检测所有节点
[root@chengqm ~]# mmm_control @test_mmm checks all
cluster01 ping [last change: 2018/12/05 20:06:35] OK
cluster01 mysql [last change: 2018/12/05 20:23:59] OK
cluster01 rep_threads [last change: 2018/12/05 20:24:14] OK
cluster01 rep_backlog [last change: 2018/12/05 20:24:14] OK: Backlog is null
cluster02 ping [last change: 2018/12/05 20:06:35] OK
cluster02 mysql [last change: 2018/12/05 20:23:59] OK
cluster02 rep_threads [last change: 2018/12/05 20:24:14] OK
cluster02 rep_backlog [last change: 2018/12/05 20:24:14] OK
cluster03 ping [last change: 2018/12/05 20:06:35] OK
cluster03 mysql [last change: 2018/12/05 20:23:59] OK
cluster03 rep_threads [last change: 2018/12/05 20:24:14] OK
cluster03 rep_backlog [last change: 2018/12/05 20:24:14] OK: Backlog is null
在 Cluster1 主机查看 VIP 情况
[root@cluster01 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether fa:16:3e:de:80:33 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.247/16 brd 10.0.255.255 scope global eth0
inet 10.0.0.238/32 scope global eth0
inet 10.0.0.237/32 scope global eth0
inet6 fe80::f816:3eff:fede:8033/64 scope link
valid_lft forever preferred_lft forever
可以看到 VIP 和 MMM 描述的一致
6 MMM 切换
MMM 切换有两种方式,手动切换和自动切换
6.1 直接切换 role
相关命令: mmm_control [@cluster] move_role [writer/reader] host 给某个节点增加角色
让我们测试一下
- 当前节点状态
[root@chengqm ~]# mmm_control @test_mmm show
cluster01(10.0.0.247) master/ONLINE. Roles: reader(10.0.0.238), writer(10.0.0.237)
cluster02(10.0.0.248) master/ONLINE. Roles: reader(10.0.0.239)
cluster03(10.0.0.249) slave/ONLINE. Roles:
- Cluster1 VIP
[mysql@cluster01 ~]$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether fa:16:3e:de:80:33 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.247/16 brd 10.0.255.255 scope global eth0
inet 10.0.0.238/32 scope global eth0
inet 10.0.0.237/32 scope global eth0
inet6 fe80::f816:3eff:fede:8033/64 scope link
valid_lft forever preferred_lft forever
- Master1 read_only 状态
[mysql@cluster01 ~]$ /usr/local/mysql57/bin/mysql -S /data/mysql_db/test_mmm/mysql.sock -e "show variables like \'read_only\'";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| read_only | OFF |
+---------------+-------+
- Cluster2 VIP
[mysql@cluster02 ~]$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether fa:16:3e:66:7e:e8 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.248/16 brd 10.0.255.255 scope global eth0
inet 10.0.0.239/32 scope global eth0
inet6 fe80::f816:3eff:fe66:7ee8/64 scope link
valid_lft forever preferred_lft forever
- Master2 read_only 状态
[mysql@cluster02 ~]$ /usr/local/mysql57/bin/mysql -S /data/mysql_db/test_mmm/mysql.sock -e "show variables like \'read_only\'";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| read_only | ON |
+---------------+-------+
- Slave 同步指向
[mysql@cluster03 ~]$ /usr/local/mysql57/bin/mysql -S /data/mysql_db/test_mmm/mysql.sock -e "show slave status \\G";
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.247
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
...
....
切换
执行 mmm_control @test_mmm move_role writer cluster02 切换
[root@chengqm ~]# mmm_control @test_mmm move_role writer cluster02
OK: Role \'writer\' has been moved from \'cluster01\' to \'cluster02\'. Now you can wait some time and check new roles info!
[root@chengqm ~]# mmm_control @test_mmm show
cluster01(10.0.0.247) master/ONLINE. Roles: reader(10.0.0.238)
cluster02(10.0.0.248) master/ONLINE. Roles: reader(10.0.0.239), writer(10.0.0.237)
cluster03(10.0.0.249) slave/ONLINE. Roles:
- 切换后 cluster2 VIP
[mysql@cluster02 ~]$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether fa:16:3e:66:7e:e8 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.248/16 brd 10.0.255.255 scope global eth0
inet 10.0.0.239/32 scope global eth0
inet 10.0.0.237/32 scope global eth0
inet6 fe80::f816:3eff:fe66:7ee8/64 scope link
valid_lft forever preferred_lft forever
- 切换后 Master2 read_only 状态
[mysql@cluster02 ~]$ /usr/local/mysql57/bin/mysql -S /data/mysql_db/test_mmm/mysql.sock -e "show variables like \'read_only\'";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| read_only | OFF |
+---------------+-------+
- 切换后 Slave 同步指向
[mysql@cluster03 ~]$ /usr/local/mysql57/bin/mysql -S /data/mysql_db/test_mmm/mysql.sock -e "show slave status \\G";
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.248
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
可以看到切换成功
6.2 使用"上线""下线"功能切换
切换操作也可以用以下两个命令完成
mmm_control [@cluster] set_offline host下线节点mmm_control [@cluster] set_online host上线节点
现在我们想把写节点从 Master2 切换到 Master1,可以进行如下操作
mmm_control @test_mmm set_offline cluster02
mmm_control @test_mmm set_online cluster02
切换后的效果是一样的,就不演示了
6.3 宕机自动切换
现在我们演示一下 Master2 数据库挂掉后自动切换情况
- kill master2
- 查看 MMM monitor 日志,看到切换过程
[root@chengqm ~]# tail -8 /var/log/mysql-mmm/mmm_mond_test_mmm.log
2018/12/06 18:09:27 WARN Check \'rep_backlog\' on \'cluster02\' is in unknown state! Message: UNKNOWN: Connect error (host = 10.0.0.248:3306, user = mmm_monitor)! Lost connection to MySQL server at \'reading initial communication packet\', system error: 111
2018/12/06 18:09:30 ERROR Check \'mysql\' on \'cluster02\' has failed for 4 seconds! Message: ERROR: Connect error (host = 10.0.0.248:3306, user = mmm_monitor)! Lost connection to MySQL server at \'reading initial communication packet\', system error: 111
2018/12/06 18:09:31 FATAL State of host \'cluster02\' changed from ONLINE to HARD_OFFLINE (ping: OK, mysql: not OK)
2018/12/06 18:09:31 INFO Removing all roles from host \'cluster02\':
2018/12/06 18:09:31 INFO Removed role \'reader(10.0.0.238)\' from host \'cluster02\'
2018/12/06 18:09:31 INFO Removed role \'writer(10.0.0.237)\' from host \'cluster02\'
2018/12/06 18:09:31 INFO Orphaned role \'writer(10.0.0.237)\' has been assigned to \'cluster01\'
2018/12/06 18:09:31 INFO Orphaned role \'reader(10.0.0.238)\' has been assigned to \'cluster01\'
- 查看节点状态
[root@chengqm ~]# mmm_control @test_mmm show
cluster01(10.0.0.247) master/ONLINE. Roles: reader(10.0.0.238), reader(10.0.0.239), writer(10.0.0.237)
cluster02(10.0.0.248) master/HARD_OFFLINE. Roles:
cluster03(10.0.0.249) slave/ONLINE. Roles:
- Cluster1 VIP 情况
[mysql@cluster01 ~]$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether fa:16:3e:de:80:33 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.247/16 brd 10.0.255.255 scope global eth0
inet 10.0.0.238/32 scope global eth0
inet 10.0.0.237/32 scope global eth0
inet6 fe80::f816:3eff:fede:8033/64 scope link
valid_lft forever preferred_lft forever
- 切换后 Slave 同步指向
[mysql@cluster03 ~]$ /usr/local/mysql57/bin/mysql -S /data/mysql_db/test_mmm/mysql.sock -e "show slave status \\G";
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.247
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
可以看到数据库宕机后, MMM 会自动切换, 从而实现高可用
7. 总结
7.1 MMM 优点
- MMM 可以管理主备节点,并实现全节点高可用
- 当节点出现问题的时候自动切换,恢复后自动上线
7.2 MMM 缺点
- 在进行主从切换时, 容易造成数据丢失。
- MMM Monitor 服务存在单点故障 ,也就是说, MMM 本身不是高可用的,所以监控端要和数据库分开部署以防数据库和监控都出现问题
笔者在实际使用过程中发现:
- 主备切换偶尔会造成从节点同步失败(主键冲突、记录不存在)
- 宕机切换恢复后节点有数据丢失
7.3 MMM 适用场景
- 对数据一致性要求不高,允许丢失少量数据,比如说评论、资讯类数据
- 读操作频繁,需要在所有节点上进行读操作负载均衡(后续文章会说到怎么做负载均衡)
到此, MMM 高可用架构搭建完毕
8. 附
8.1 问题及解决方案
1). 配置文件读写权限
- 问题描述
FATAL Configuration file /etc/mysql-mmm/mmm_agent*.conf is world writable!
FATAL Configuration file /etc/mysql-mmm/mmm_agent*.conf is world readable!
- 解决方案
chmod 664 /etc/mysql-mmm/*
2). 重复监听
- 问题描述
这个问题容易出现在多个 MMM 监控实例的情况下, 报错如下
FATAL Listener: Can’t create socket!
- 解决方案
- 检查配置文件端口是否冲突
- 检查机器端口是否被占用
3). 网卡配置不对
- 问题描述
FATAL Couldn’t configure IP ‘192.168.1.202’ on interface ‘em1’: undef
- 解决方案
ifconfig 命令查看网卡,更改配置文件
8.2 mmm 6 种状态及变化原因
状态
- online
- admin_offline
- hard_offline
- awaiting_recovery
- replication_delay
- replication_fail
变化原因:
- ONLINE: Host is running without any problems.
- ADMIN_OFFLINE: host was set to offline manually.
- HARD_OFFLINE: Host is offline (Check ping and/or mysql failed)
- AWAITING_RECOVERY: Host is awaiting recovery
- REPLICATION_DELAY: replication backlog is too big (Check rep_backlog failed)
- REPLICATION_FAIL: replication threads are not running (Check rep_threads failed)
其他说明
- Only hosts with state ONLINE may have roles. When a host switches from ONLINE to any other state, all roles will be removed from it.
- A host that was in state REPLICATION_DELAY or REPLICATION_FAIL will be switched back to ONLINE if everything is OK again, unless it is flapping (see Flapping).
- A host that was in state HARD_OFFLINE will be switched to AWAITING_RECOVERY if everything is OK again. If its downtime was shorter than 60 seconds and it wasn\'t rebooted or auto_set_online is > 0 it will be switched back to ONLINE automatically, unless it is flapping (see Flapping again).
- Replication backlog or failure on the active master isn\'t considered to be a problem, so the active master will never be in state REPLICATION_DELAY or REPLICATION_FAIL.
- Replication backlog or failure will be ignored on hosts whos peers got ONLINE less than 60 seconds ago (That\'s the default value of master-connect-retry).
- If both checks rep_backlog and rep_threads fail, the state will change to REPLICATION_FAIL.
- If auto_set_online is > 0, flapping hosts will automatically be set to ONLINE after flap_duration seconds.
参考: mmm 官方文档