SparkSQL
Posted cschen588
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkSQL相关的知识,希望对你有一定的参考价值。
Spark SQL 增加了DataFrame 即带有Schema信息的RDD
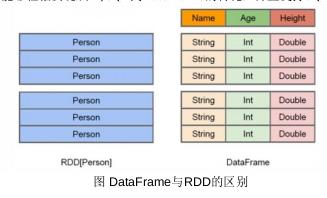
DataFrame 创建
启动pyspark(由于内存不够 启动本地,模式)
pyspark --master local
pyspark 自动生成 sc,sparksession
from pyspark import SparkContext,SparkConf from pyspark.sql import SparkSession spark=SparkSession.builder.config(conf=SparkConf()).getOrCreate() df=spark.read.json("file:///usr/local/spark/examples/src/main/resources/people.json") df.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
1。利用反射机制推断RDD
schemaPeople.createOrReplaceTempView("people")的people 是一个名称
persionDF是新建的DataFrame 每个sql就是一个DataFrame
下面从rdd转到df再到rdd

2。使用编程方法定义RDD

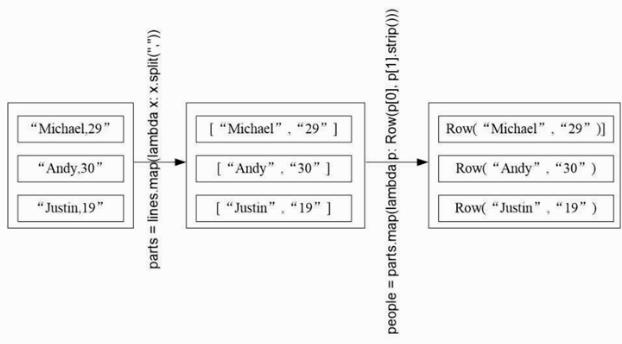
for循环2次
名字,数据类型,可否为空

记录放前面,表头放后面
sparksql读取Mysql
Mysql数据库的准备:
http://dblab.xmu.edu.cn/blog/install-mysql/ mysql安装
- sudo apt-get update #更新软件源
- sudo apt-get install mysql-server #安装mysql
- service mysql start
sudo mysql 启动mysql
修改用户 hadoop
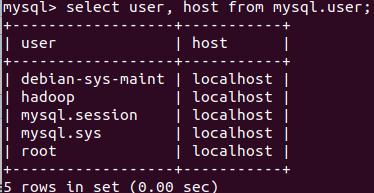
select user, host from mysql.user; 看当前的所有用户
grant all privileges on *.* to \'hadoop\'@\'localhost\' identified by "Unsw2016"; 给hadoop权限并设密码
flush privileges; 刷新权限
show grants for \'hadoop\'@\'localhost\'; 看权限
sql基本操作:
https://www.jianshu.com/p/652495b6fea6
mysql -u hadoop -p
启动mysql


https://dev.mysql.com/downloads/connector/j/
使用spark sql读取mysql
通过JDBC链接mysql
老是他秒的读不出 必须在pyspark启动时添加jar包
pyspark --master local --jars /usr/local/spark/jars/mysql-connector-java-5.1.48.jar
pyspark下执行 通过jdbc连接mysql
jdbcDF=spark.read.format("jdbc").option("driver","com.mysql.jdbc.Driver").option("url","jdbc:mysql://localhost:3306/spark")\\ option("dbtable","student").option("user","hadoop").option("password","Unsw2016").load()
jdbcDF.show()
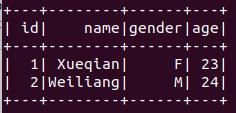
通过从mysql中读取数据生成dataframe
使用spark sql写入mysql
Spark官方推荐使用Row对象来代替dict:

.map操作不会改变元素的个数
p代表列表 并去掉尾部空格
from pyspark.sql import Row from pyspark.sql.types import * from pyspark import SparkContext,SparkConf from pyspark.sql import SparkSession spark=SparkSession.builder.config(conf=SparkConf()).getOrCreate() #model info table head, table record and combine them schema = StructType([StructField("id",IntegerType(),True),\\ StructField("name",StringType(),True),\\ StructField("gender",StringType(),True),\\ StructField("age",IntegerType(),True)]) #above is table head, below set two data,means two students studentRDD=spark.sparkContext\\ .parallelize(["3 Rongcheng M 26","4 Guanhua M 27"])\\ .map(lambda x:x.split(" ")) #below create Row object, every Row object is a line in rowRDD rowRDD=studentRDD.map(lambda p:Row(int(p[0].strip()),p[1].strip(),p[2].strip(),int(p[3].strip()))) #combine table head and table content studentDF=spark.createDataFrame(rowRDD,schema) #write into database prop={} prop["user"]="hadoop" prop["password"]="Unsw2016" prop["driver"]="com.mysql.jdbc.Driver" studentDF.write.jdbc("jdbc:mysql://localhost:3306/spark","student","append",prop)
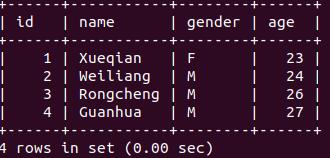
写入成功
以上是关于SparkSQL的主要内容,如果未能解决你的问题,请参考以下文章