mysql的undo log和redo log
Posted 爱上胡萝卜的猴子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql的undo log和redo log相关的知识,希望对你有一定的参考价值。
1.1 undo是什么
1.2 undo参数
show global variables like \'%undo%\';
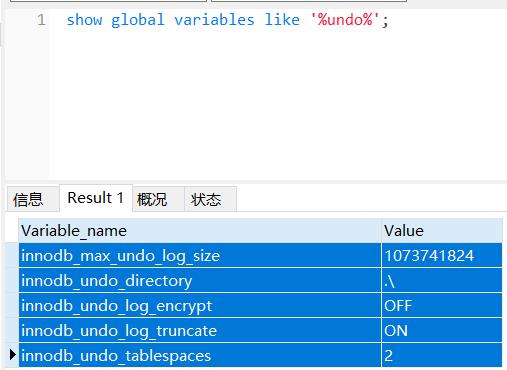
设置undo独立表空间个数,范围为0-128, 默认为0,0表示表示不开启独立undo表空间 且 undo日志存储在ibdata文件中。该参数只能在最开始初始化MySQL实例的时候指定,如果实例已创建,这个参数是不能变动的,如果在数据库配置文 件 .cnf 中指定innodb_undo_tablespaces 的个数大于实例创建时的指定个数,则会启动失败,提示该参数设置有误。
innodb_undo_log_truncate
InnoDB的purge线程,根据innodb_undo_log_truncate设置开启或关闭、innodb_max_undo_log_size的参数值,以及truncate的频率来进行空间回收和 undo file 的重新初始化。
该参数生效的前提是,已设置独立表空间且独立表空间个数大于等于2个
1.3 undo空间管理
- slot 0 ,预留给系统表空间;
- slot 1- 32,预留给临时表空间,每次数据库重启的时候,都会重建临时表空间;
- slot33-127,如果有独立表空间,则预留给UNDO独立表空间;如果没有,则预留给系统表空间;
Cannot find a free slot for an undo log。则说明并发的事务太多了,需要考虑下是否要分流业务。2.1 redo是什么
- 当buffer pool中的dirty page 还没有刷新到磁盘的时候,发生crash,启动服务后,可通过redo log 找到需要重新刷新到磁盘文件的记录;
- buffer pool中的数据直接flush到disk file,是一个随机IO,效率较差,而把buffer pool中的数据记录到redo log,是一个顺序IO,可以提高事务提交的速度;
2.2 redo 参数
- innodb_log_files_in_group
- innodb_log_file_size
- innodb_log_group_home_dir
- innodb_log_buffer_size
- innodb_flush_log_at_trx_commit
- innodb_flush_log_at_trx_commit=1,每次commit都会把redo log从redo log buffer写入到system,并fsync刷新到磁盘文件中。
- innodb_flush_log_at_trx_commit=2,每次事务提交时MySQL会把日志从redo log buffer写入到system,但只写入到file system buffer,由系统内部来fsync到磁盘文件。如果数据库实例crash,不会丢失redo log,但是如果服务器crash,由于file system buffer还来不及fsync到磁盘文件,所以会丢失这一部分的数据。
- innodb_flush_log_at_trx_commit=0,事务发生过程,日志一直激励在redo log buffer中,跟其他设置一样,但是在事务提交时,不产生redo 写操作,而是MySQL内部每秒操作一次,从redo log buffer,把数据写入到系统中去。如果发生crash,即丢失1s内的事务修改操作。
- 注意:由于进程调度策略问题,这个“每秒执行一次 flush(刷到磁盘)操作”并不是保证100%的“每秒”。
-
2.3 redo 空间管理
Redo log文件以ib_logfile[number]命名,Redo log 以顺序的方式写入文件文件,写满时则回溯到第一个文件,进行覆盖写。(但在做redo checkpoint时,也会更新第一个日志文件的头部checkpoint标记,所以严格来讲也不算顺序写)。实际上redo log有两部分组成:redo log buffer 跟redo log file。buffer pool中把数据修改情况记录到redo log buffer,出现以下情况,再把redo log刷下到redo log file:- Redo log buffer空间不足
- 事务提交(依赖innodb_flush_log_at_trx_commit参数设置)
- 后台线程
- 做checkpoint
- 实例shutdown
- binlog切换
3.1 Undo + Redo事务的简化过程
undo 例子
Undo Log的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到一个地方(这个存储数据备份的地方称为Undo Log)。然后进行数据的修改。如果出现了错误或者用户执行了ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。
假设有A、B两个数据,值分别为1,2。 进行+2的事务操作。
A.事务开始.
B.记录A=1到undo log.
C.修改A=3.
D.记录B=2到undo log.
E.修改B=4.
F.将undo log写到磁盘。
G.将数据写到磁盘。
H.事务提交
这里有一个隐含的前提条件:‘数据都是先读到内存中,然后修改内存中的数据,最后将数据写回磁盘’。
之所以能同时保证原子性和持久化,是因为以下特点:
A. 更新数据前记录Undo log。
B. 为了保证持久性,必须将数据在事务提交前写到磁盘。只要事务成功提交,数据必然已经持久化。
C. Undo log必须先于数据持久化到磁盘。如果在G,H之间系统崩溃,undo log是完整的,可以用来回滚事务。
D. 如果在A-F之间系统崩溃,因为数据没有持久化到磁盘。所以磁盘上的数据还是保持在事务开始前的状态。
缺点:每个事务提交前将数据和Undo Log写入磁盘,这样会导致大量的磁盘IO,因此性能很低。
再举个Undo + Redo事务的简化过程例子:
B.记录A=1到undo log.
C.修改A=3.
D.记录A=3到redo log.
E.记录B=2到undo log.
F.修改B=4.
G.记录B=4到redo log.
H.将redo log写入磁盘。
3.2 IO影响
以减少日志占用的空间。例如,Redo Log中的记录内容可能是这样的:
记录1: <trx1, insert …>
记录2: <trx2, update …>
记录3: <trx1, delete …>
记录4: <trx3, update …>
记录5: <trx2, insert …>
D. 因为C的原因,当一个事务将Redo Log写入磁盘时,也会将其他未提交的事务的日志写入磁盘。
3.3 恢复
B. 进行恢复时,重做所有事务包括未提交的事务和回滚了的事务。然后通过Undo Log回滚那些
记录1: <trx1, Undo log insert <undo_insert …>>
记录2: <trx1, insert …>
记录3: <trx2, Undo log insert <undo_update …>>
记录4: <trx2, update …>
记录5: <trx3, Undo log insert <undo_delete …>>
记录6: <trx3, delete …>
C. 到这里,还有一个问题没有弄清楚。既然Redo没有事务性,那岂不是会重新执行被回滚了的事务?
确实是这样。同时Innodb也会将事务回滚时的操作也记录到redo log中。回滚操作本质上也是
对数据进行修改,因此回滚时对数据的操作也会记录到Redo Log中。
一个回滚了的事务的Redo Log,看起来是这样的:
记录1: <trx1, Undo log insert <undo_insert …>>
记录2: <trx1, insert A…>
记录3: <trx1, Undo log insert <undo_update …>>
记录4: <trx1, update B…>
记录5: <trx1, Undo log insert <undo_delete …>>
记录6: <trx1, delete C…>
记录7: <trx1, insert C>
记录8: <trx1, update B to old value>
以上是关于mysql的undo log和redo log的主要内容,如果未能解决你的问题,请参考以下文章
mysql的innodb引擎下的undo log中包括“写redo log”这件事?
MySQL的日志:事务日志(redo log和undo log)
MySQL 日志(redo log 和 undo log) 都是什么鬼?