redis对比其余数据库
Posted stackOverFlow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis对比其余数据库相关的知识,希望对你有一定的参考价值。
Redis属于常见的NoSQL数据库或者说非关系数据库:Redis不使用表,她的数据库也不会预定义或者强制去要求用户对Redis存储的不同数据进行关联。
常见数据库对比:
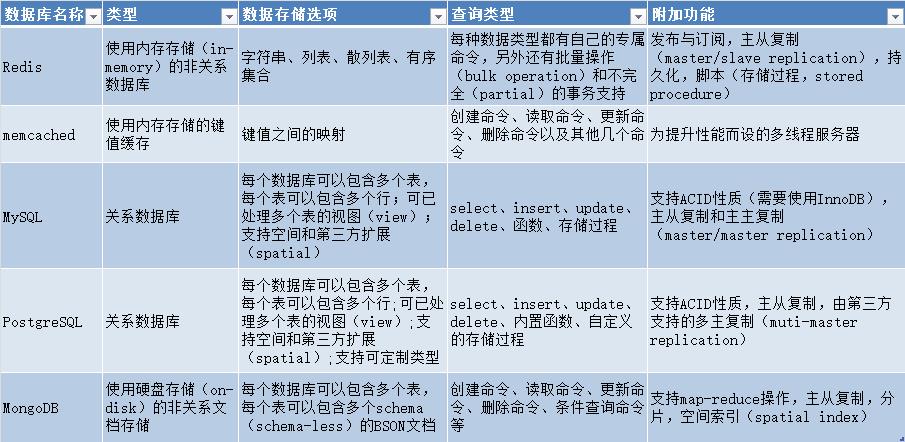
和高性能键值缓存服务器memcached对比:
Redis和mencached都可用于存储键值映射,彼此性能也相差无几,但是①.Redis能够自动以两种不同的方式将数据写入硬盘进行持久化;②.Redis除了能存储普通的字符串键外,还可以存储其他四种数据结构,而memcached只能存储普通的字符串键;③.Redis数据库既可以用作主数据库(primary database)使用,也可以作为其他存储系统的辅助数据库(auxiliary database)使用。
Redis附加特性:
1.持久化方法:
作为内存数据库,服务器关闭后,存储的数据何去何从?Redis拥有两种不同形式的持久化方法,都可以用小而紧凑的格式将存储在内存中的数据写入硬盘:第一种持久化方法为时间点转储(point-in-time dump),转储操作既可以在“指定时间段内有指定数量的写操作执行”这一条件被满足时执行,又可以通过调用两条转储到硬盘(dump-to-disk)命令中的任何一条来执行;第二种持久化方法见过有修改了数据库的命令都写入到一个只追加(append-only)文件里面,用户可以根据数据的重要程度,将只追加写入设置为从不同步(sync)、每秒同步一次或者每写入一条命令就同步一次。
2.避免集中式访问:
由于Redis的内存存储设计,只使用一台Redis服务器可能没办法处理所有请求,因此为了扩展Redis的读性能,并为redis提供故障转移(failover)支持,Redis实现了主从复制特性:执行复制的从服务器会连上主服务器,接收主服务器发送的整个数据库的初始副本(copy);之后主服务器执行的写命令,都会发送给所有连接着的从服务器,从而实时更新从服务器的数据集,因此可以向任意一个从服务器发送读请求,避免对主服务器的集中式访问。
使用Redis的理由
memcached数据库,用户只能用APPEND命令将数据添加到已有字符串的末尾。memcached的文档中声明,可以用APPEND命令来管理元素列表。用户可以将元素追加到一个字符串的末尾,并将那个字符串当作列表来使用。对于如何删除这些元素,memcached采用的办法是通过黑名单(blacklist)来隐藏列表里面的元素,从而避免对元素执行读取、更新、写入(包括在一次数据库查询之后执行的memcached写入)等操作。相反地,Redis的LIST和SET允许用户直接添加或者删除元素。
使用Redis而不是memcached来解决问题,不仅可以让代码变得更简短、更易懂、更易维护,而且还可以使代码的运行速度更快(因为用户不需要通过读取数据库来更新数据)。除此之外,在其他许多情况下,Redis的效率和易用性也比关系数据库要好得多。
数据库的一个常见用法是存储长期的报告数据,并将这些报告数据用作固定时间范围内的聚合数据(aggregates)。收集聚合数据的常见做法是:先将各个行插入一个报告表里面,之后再通过扫描这些行来收集聚合数据,并根据收集到的聚合数据来更新聚合表中已有的那些行。之所以使用插入行的方式来存储,是因为对于大部分数据库来说,插入行操作的执行速度非常快(插入行只会在硬盘文件末尾进行写入)。不过,对表里面的行进行更新却是一个速度相当慢的操作,因为这种更新除了会引起一次随机读(random read)之外,还可能会引起一次随机写(random write)。而在Redis里面,用户可以直接使用原子的(atomic)INCR命令及其变种来计算聚合数据,并且因为Redis将数据存储在内存里面,而且发送给Redis的命令请求并不需要经过典型的查询分析器(parser)或者查询优化器(optimizer)进行处理,所以对Redis存储的数据执行随机写的速度总是非常迅速的。
使用 Redis 而不是关系数据库或者其他硬盘存储数据库,可以避免写入不必要的临时数据,也免去了对临时数据进行扫描或者删除的麻烦,并最终改善程序的性能。虽然上面列举的都是一些简单的例子,但它们很好地证明了“工具会极大地改变人们解决问题的方式”这一点。
以上是关于redis对比其余数据库的主要内容,如果未能解决你的问题,请参考以下文章
Memcache,Redis,MongoDB三种非关系型数据库的对比
缓存数据REDIS:Redis简介及Memcached 对比
缓存数据REDIS:Redis简介及Memcached 对比