大数据07 Spark
Posted 神之一招
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据07 Spark相关的知识,希望对你有一定的参考价值。
Spark 是基于内存的计算, 低延迟.
Apache 基金会3大分布式系统开源项目 Hadoop, Spark, Storm (数据流)
Spark 特点: 处理快, 容易使用(Java,Python,Scala,R). 通用性(包括SQL,机器学习, 流失计算), 运行模式多样
Spark生态系统

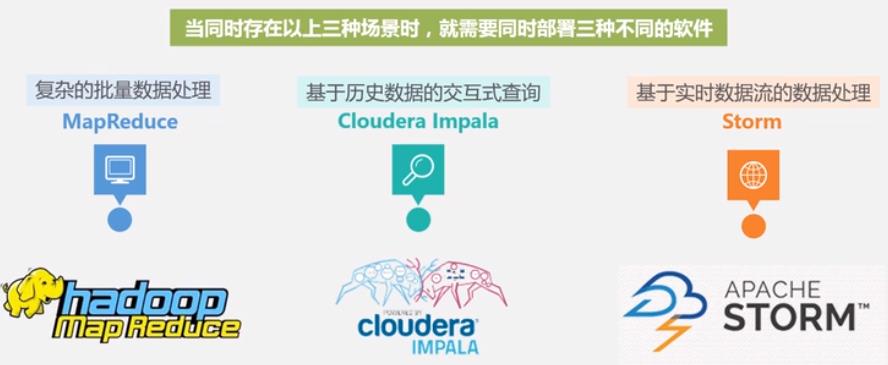
不同的软件的问题:

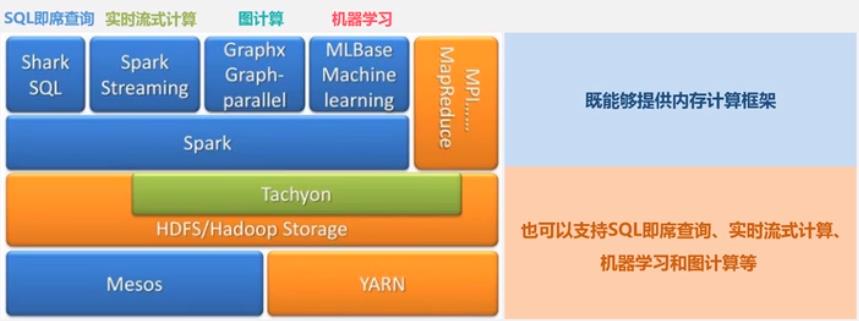
Spark 可以一站式提供的解决方案.

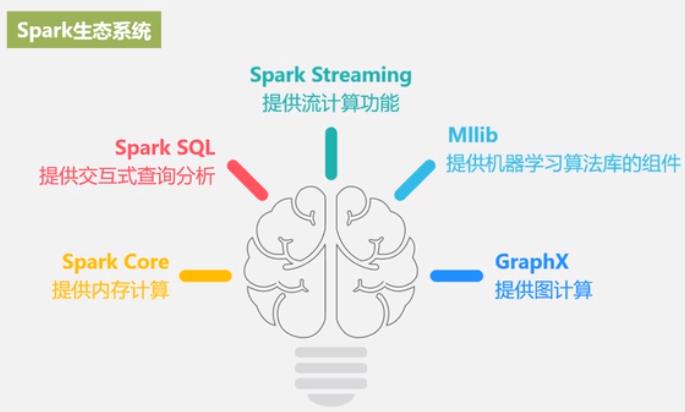
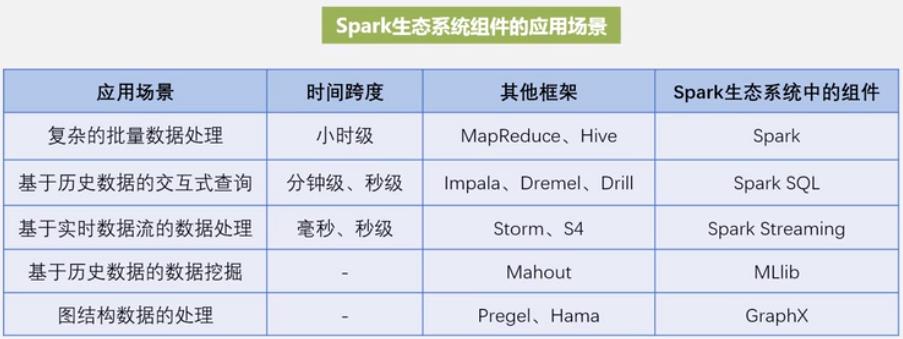
Spark 基本概念
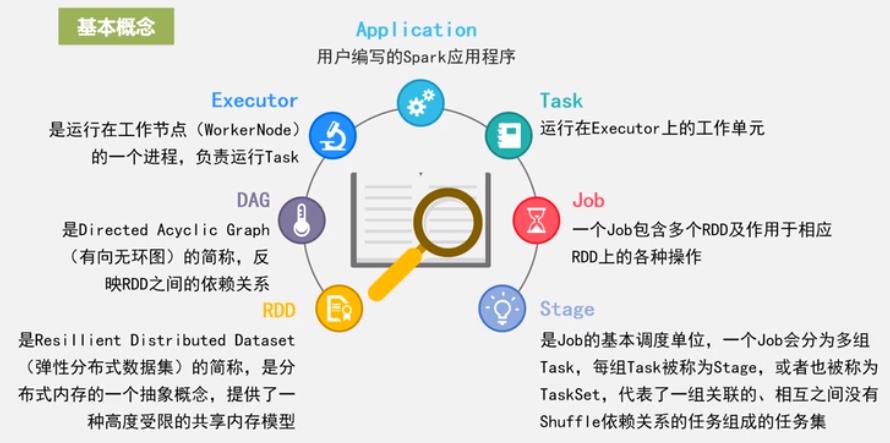
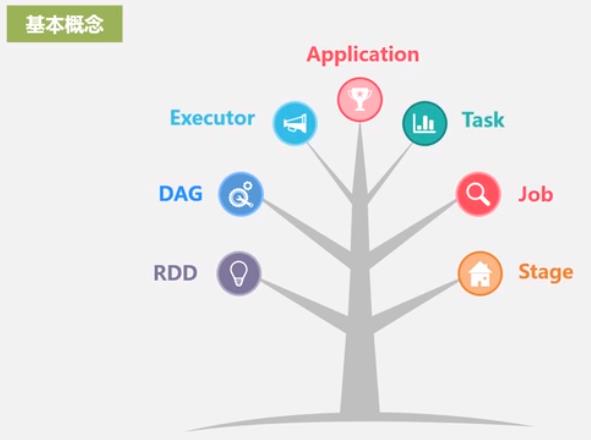
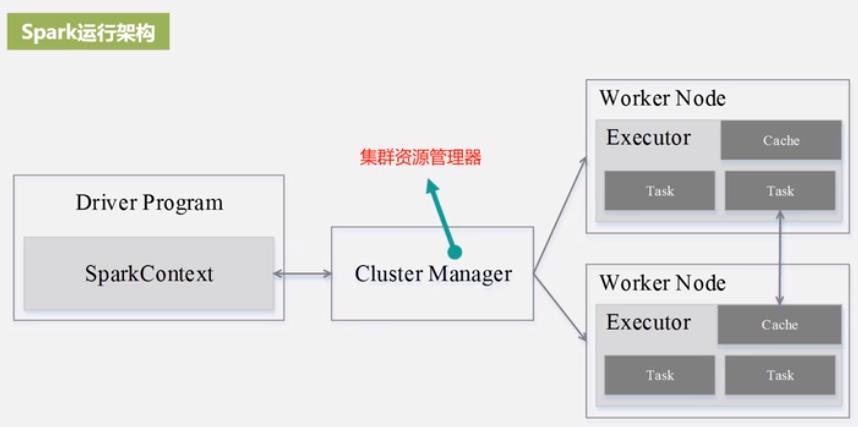

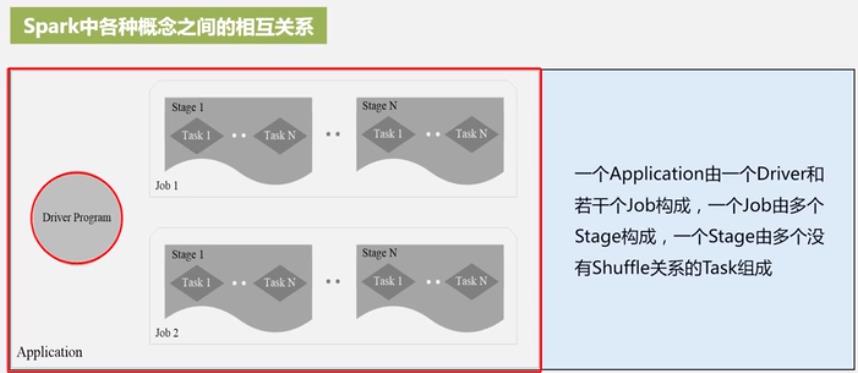
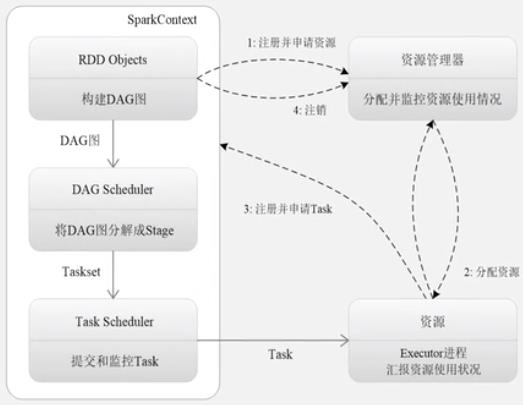
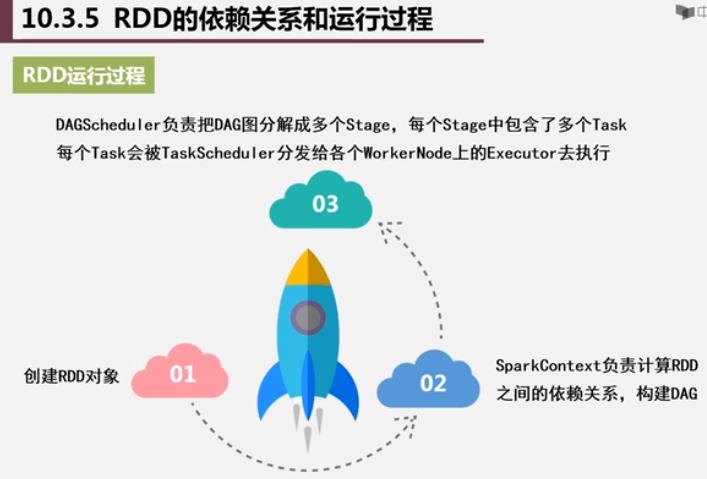
DAG: 有向无环图

RDD



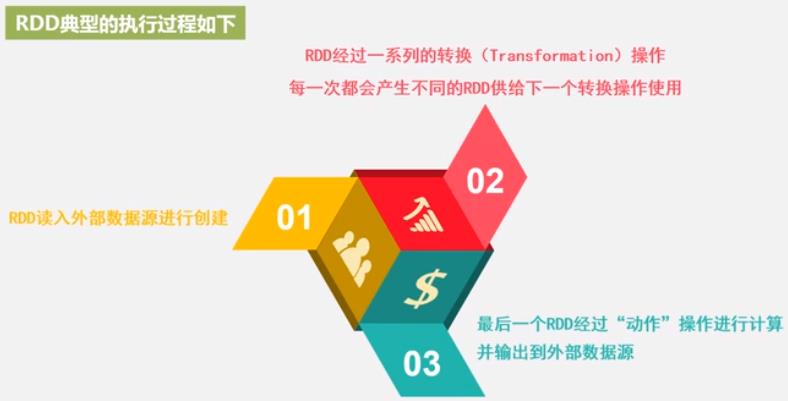
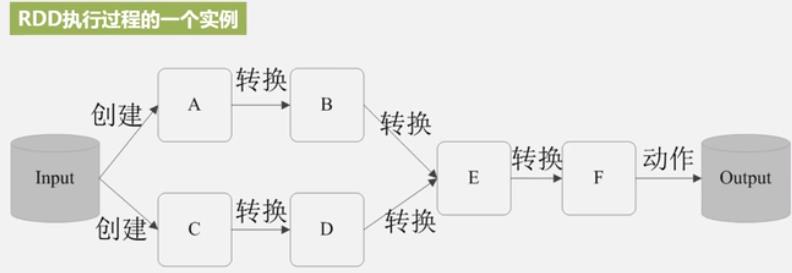
这一系列处理称为一个Lineage(血缘关系), DAG 拓扑排序的结果. 管道化处理.
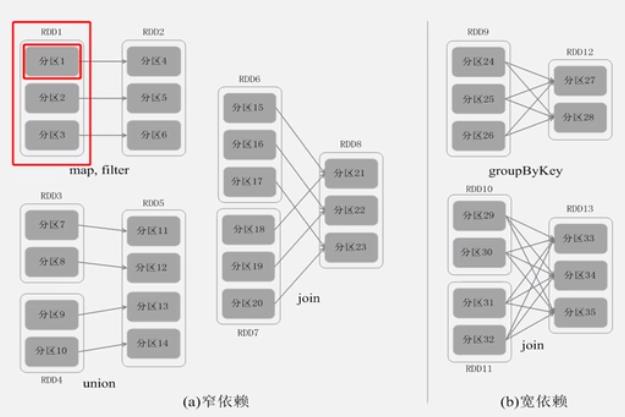

窄依赖: 1对1,或多对一.
宽依赖: 1对多
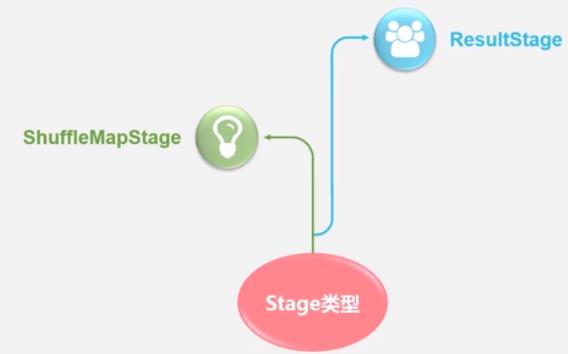
Stage划分: 就依赖于 宽/窄依赖

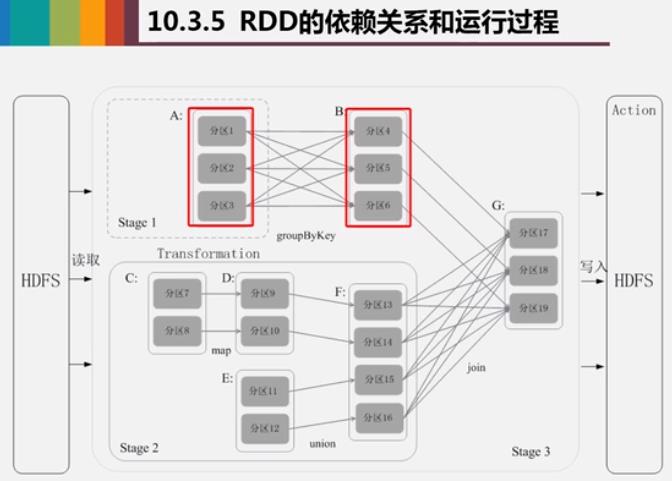


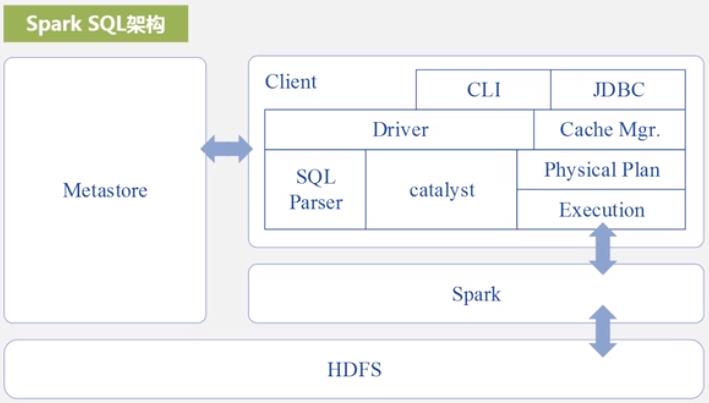
Spark SQL
Shark 即 Hive on Spark. 所以 Shark 与 Hive 很像,只是在最后物理层生成了 Spark, 而不是生成的 MapReduce.

Shark 有线程安全. 所以 Shark 被抛弃了, 转到了 SparkSQL 架构.


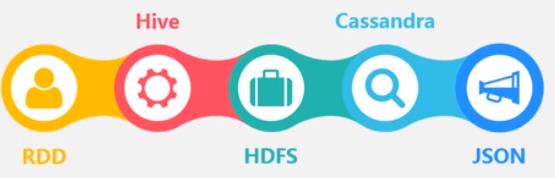
RDD 的来源更加多元化
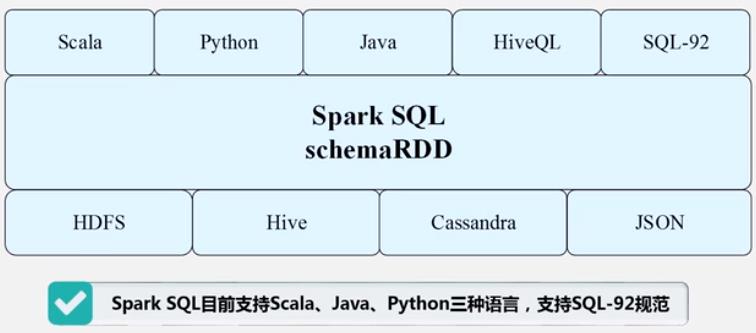
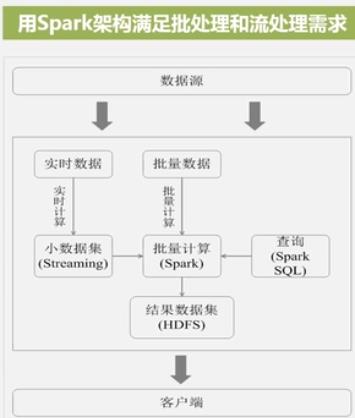

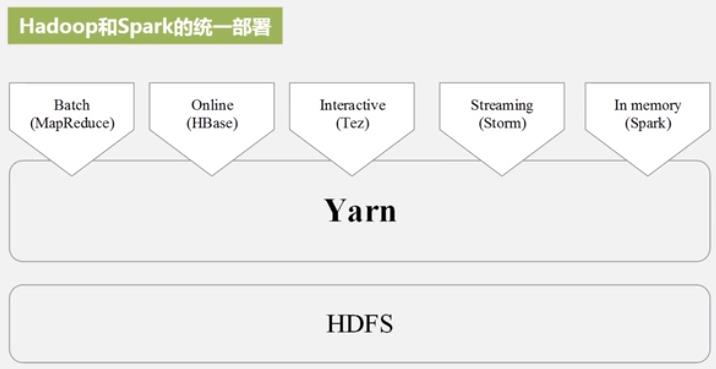
现在比较流行的是 Hadoop + Spark
以上是关于大数据07 Spark的主要内容,如果未能解决你的问题,请参考以下文章