redis++:Redis持久化 rdb & aof 工作原理及流程图
Posted coding++
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis++:Redis持久化 rdb & aof 工作原理及流程图 相关的知识,希望对你有一定的参考价值。
RDB的原理:
在Redis中RDB持久化的触发分为两种:自己手动触发与Redis定时触发。
针对RDB方式的持久化,手动触发可以使用:
1):save:会阻塞当前Redis服务器,直到持久化完成,线上应该禁止使用。
2):bgsave:该触发方式会fork一个子进程,由子进程负责持久化过程,因此阻塞只会发生在fork子进程的时候。
而自动触发的场景主要是有以下几点:
1):根据我们的 save m n 配置规则自动触发;
2):从节点全量复制时,主节点发送rdb文件给从节点完成复制操作,主节点会触发 bgsave;
3):执行 debug reload 时;
4):执行 shutdown时,如果没有开启aof,也会触发。
由于 save 基本不会被使用到,我们重点看看 bgsave 这个命令是如何完成RDB的持久化的。流程图如下
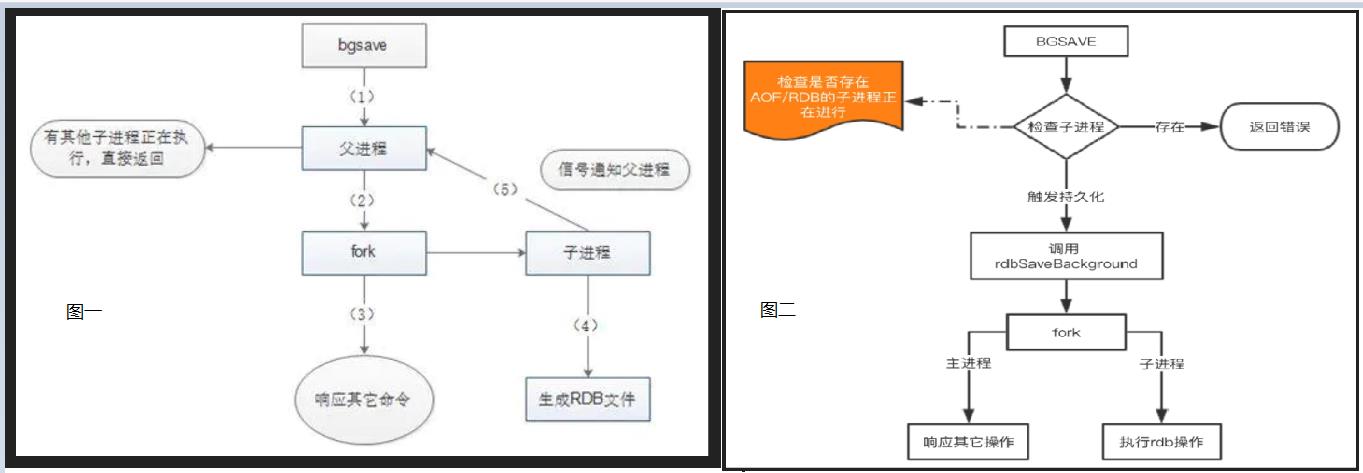
1、Redis父进程首先判断:当前是否在执行save,或bgsave/bgrewriteaof(aof文件重写命令)的子进程,如果在执行则bgsave命令直接返回。
bgsave/bgrewriteaof 的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题。
2、父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令;
3、父进程fork后,bgsave命令返回”Background saving started”信息并不再阻塞父进程,并可以响应其他命令;
4、子进程创建RDB文件,根据父进程内存快照生成临时快照文件,完成后对原有文件进行原子替换;
5、子进程发送信号给父进程表示完成,父进程更新统计信息。
AOF的原理:
AOF的整个流程大体来看可以分为两步,一步是命令的实时写入(如果是 appendfsync everysec 配置,会有1s损耗),第二步是对aof文件的重写。
对于增量追加到文件这一步主要的流程是:命令写入=》追加到aof_buf =》同步到aof磁盘。
那么这里为什么要先写入buf在同步到磁盘呢?如果实时写入磁盘会带来非常高的磁盘IO,影响整体性能。
aof重写是为了减少aof文件的大小,可以手动或者自动触发,关于自动触发的规则请看上面配置部分。
fork的操作也是发生在重写这一步,也是这里会对主进程产生阻塞。
手动触发: bgrewriteaof,自动触发 就是根据配置规则来触发,当然自动触发的整体时间还跟Redis的定时任务频率有关系。
流程图如下:

对于上图有四个关键点补充一下:
1、在重写期间,由于主进程依然在响应命令,为了保证最终备份的完整性;因此它依然会写入旧的AOF file中,如果重写失败,能够保证数据不丢失。
2、为了把重写期间响应的写入信息也写入到新的文件中,因此也会为子进程保留一个buf,防止新写的file丢失数据。
3、重写是直接把当前内存的数据生成对应命令,并不需要读取老的AOF文件进行分析、命令合并。
4、AOF文件直接采用的文本协议,主要是兼容性好、追加方便、可读性高可认为修改修复。
无论是 RDB 还是 AOF 都是先写入一个临时文件,然后通过 rename 完成文件的替换工作。
持久化中恢复数据:
数据的备份、持久化做完了,我们如何从这些持久化文件中恢复数据呢?如果一台服务器上有既有RDB文件,又有AOF文件,该加载谁呢?
其实想要从这些文件中恢复数据,只需要重新启动Redis即可。
恢复数据流程图:

启动时会先检查AOF文件是否存在,如果不存在就尝试加载RDB。
那么为什么会优先加载AOF呢?因为AOF保存的数据更完整,通过上面的分析我们知道AOF基本上最多损失1s的数据。
性能与实践:
通过上面的分析,我们都知道RDB的快照、AOF的重写都需要fork,这是一个重量级操作,会对Redis造成阻塞。因此为了不影响Redis主进程响应,我们需要尽可能降低阻塞。
1、降低fork的频率,比如可以手动来触发RDB生成快照、与AOF重写;
2、控制Redis最大使用内存,防止fork耗时过长;
3、使用更牛逼的硬件;
4、合理配置Linux的内存分配策略,避免因为物理内存不足导致fork失败。
在线上我们到底该怎么做?我提供一些自己的实践经验。
1、如果Redis中的数据并不是特别敏感或者可以通过其它方式重写生成数据,可以关闭持久化,如果丢失数据可以通过其它途径补回;
2、自己制定策略定期检查Redis的情况,然后可以手动触发备份、重写数据;
3、单机如果部署多个实例,要防止多个机器同时运行持久化、重写操作,防止出现内存、CPU、IO资源竞争,让持久化变为串行;
4、可以加入主从机器,利用一台从机器进行备份处理,其它机器正常响应客户端的命令;
5、RDB持久化与AOF持久化可以同时存在,配合使用。
本文的内容主要是运维上的一些注意点,但我们开发者了解到这些知识,在某些时候有助于我们发现诡异的bug。
以上是关于redis++:Redis持久化 rdb & aof 工作原理及流程图 的主要内容,如果未能解决你的问题,请参考以下文章