当然, 说明一下, 所有的内容都是网上搬砖的, 也是用作自己练习用的.
我觉得如何去写 sql 这个思考的过程, 远比最终写出来更重要, 毕竟, 我最近有在公司看到了 2000多行的一个 sql. 我觉的, 这样神级的存在, 也是, 九层之台,起于垒土. 而最为重要的是理清楚逻辑. 我最真实的情况是, 一般在做一些数据处理的时候, 我用 pandas 几乎能完成任何的数据操作. 根本原因在于,我头脑中, 始终有一个 DataFrame 的影像. 我始终能知道我当前的对象, 会是怎样的 DataFrame. 而这点是我在 SQL 所不具备的. 因而, 我觉得, sql 的思路过程, 会帮助我去理解这一块.
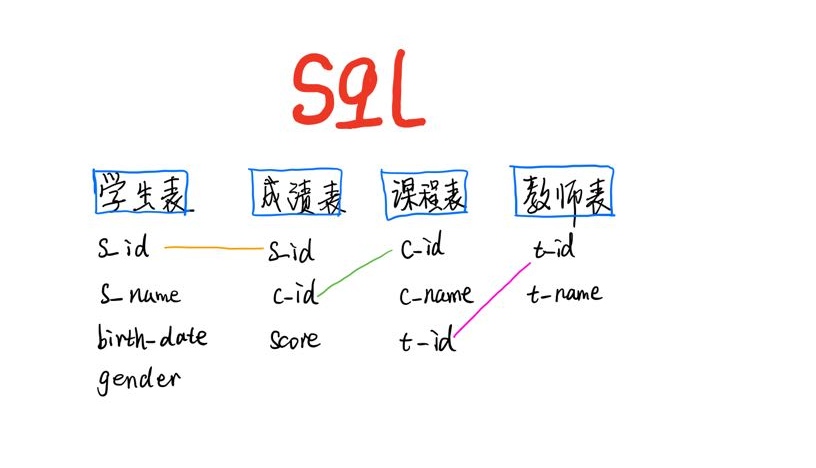
数据关系
这个是都次都要重复提及的. 只有熟练知晓表结构, 才能做各种查询呀.
需求
第 01 题
查询课程编号为 "0001" 的课程, 比 "0002" 的课程成绩 高 的所有学生的 学号.
分析
可以从面向过程的角度, 其实, 如果我们有这样的一张表.
s_id, c_id_0001_score, c_id_0002_score
s_a, 90, 80
s_b, 80, 60
s_c, 70, 98
-- 则就简单了直接
select s_id from xxx where c_id_0001 > c_id_0002;
即涉及的表主要是 score 表.
mysql> select * from score;
+------+------+-------+
| s_id | c_id | score |
+------+------+-------+
| 0001 | 0001 | 80 |
| 0001 | 0002 | 90 |
| 0001 | 0003 | 99 |
| 0002 | 0002 | 60 |
| 0002 | 0003 | 80 |
| 0003 | 0001 | 80 |
| 0003 | 0002 | 80 |
| 0003 | 0003 | 80 |
+------+------+-------+
8 rows in set (0.00 sec)
可以看到, 1, 3号学生有选1,2,3 课程; 2号学生选了 2,3 号课程.
如果要给 2号学生选上1号课, 则:
insert into score values ("0002", "0001", 85)
要想得到咱上面 的表呢, 其实就是, 将这里的 score:
- 以 c_id 分为 0001 和 0002 两个部分,
- 以 s_id 作为键, 对这两部分进行 inner join 即可.
-- 首先从 score 找出 课程为 0001 的 学生id, 课程id, 和成绩
select
s_id,
c_id,
score
from score
where
c_id = "0001";
+------+------+-------+
| s_id | c_id | score |
+------+------+-------+
| 0001 | 0001 | 80 |
| 0003 | 0001 | 80 |
+------+------+-------+
2 rows in set (0.00 sec)
可以看到, 选择课程 0001 的有 1, 3号学生, 他们的成绩都是80
-- 同样从 score 中找出课程为0002的s_id, c_id, score
select
s_id,
c_id,
score
from score
where
c_id = "0002";
+------+------+-------+
| s_id | c_id | score |
+------+------+-------+
| 0001 | 0002 | 90 |
| 0002 | 0002 | 60 |
| 0003 | 0002 | 80 |
+------+------+-------+
3 rows in set (0.00 sec)
选课 0002 课程的有 1,2,3 号学生, 成绩分别为 90, 60, 80
要查询课程编号为 "0001" 的课程, 比 "0002" 的课程成绩 高 的所有学生的 学号. 其实就将这两个查询集, 给 inner join 就好了呀.
-- 外面需要再套一层
select *
from
(
select
s_id,
c_id,
score
from score
where
c_id = "0001"
) as a
-- 连接方式
inner join
(
select
s_id,
c_id,
score
from score
where c_id = "0002"
) as b
-- 连接条件
on
a.s_id = b.s_id;
可以看到, 其实 0001 > 0002 的兄弟, 是没有的.
+------+------+-------+------+------+-------+
| s_id | c_id | score | s_id | c_id | score |
+------+------+-------+------+------+-------+
| 0001 | 0001 | 80 | 0001 | 0002 | 90 |
| 0003 | 0001 | 80 | 0003 | 0002 | 80 |
+------+------+-------+------+------+-------+
2 rows in set (0.01 sec)
为了有, 我把条件给放宽到 等于吧, 即 3号兄弟, 然后完整地来写一遍 sql
select
a.s_id as "学号"
-- a.score as "0001课的成绩",
-- b.score as "0002棵的成绩"
from
(
select
s_id,
c_id,
score
from score
where
c_id = "0001"
) as a
-- 连接方式
inner join
(
select
s_id,
c_id,
score
from score
where c_id = "0002"
) as b
-- 连接条件
on
a.s_id = b.s_id
where
a.score >= b.score;
这样就只查到了学号
+--------+
| 学号 |
+--------+
| 0003 |
+--------+
1 row in set (0.00 sec)
假如我们这里再来扩展一波, 不仅要学号, 还要姓名的话, 就需要再 inner join 学生表了呀, 根据 s_id
select
a.s_id as "学号",
c.s_name as "学生姓名",
a.score as "0001课的成绩",
b.score as "0002棵的成绩"
from
(
select
s_id,
c_id,
score
from score
where
c_id = "0001"
) as a
-- 连接方式
inner join
(
select
s_id,
c_id,
score
from score
where c_id = "0002"
) as b
-- 连接条件
on
a.s_id = b.s_id
-- 补充上学生的名字
inner join student as c
on c.s_id = a.s_id
where
a.score >= b.score;
然后就可以看到3号的老铁啦
+--------+--------------+------------------+------------------+
| 学号 | 学生姓名 | 0001课的成绩 | 0002棵的成绩 |
+--------+--------------+------------------+------------------+
| 0003 | 胡小适 | 80 | 80 |
+--------+--------------+------------------+------------------+
1 row in set (0.01 sec)
可以看到, 我们这里的学号是 1对1 的, 如果是多对多什么的, 感觉就会比较复杂了.
小结
- 这个demo 的关键思路是, 将 score 通过课程 id 的方式给分成 几份, 做内连接
- 整个写法呢, 是面向过程的, 应用子查询来弄
- 代码排版上, 尽量能分块, 缩进, 提高阅读体验
虽然这一篇就只是弄了一个 sql 但我感觉, 涉及的东西还是挺多的, 尤其是最初的那个假定的表, 思维这块需要多练.