如果合理的设计且使用索引的mysql是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
索引分类
1.PRIMARY KEY 主键索引:一个表只能有一个主键,不允许有空值。
2.UNIQUE INDEX 唯一索引:索引列的值必须唯一,但允许有空值。
3.INDEX 普通索引:最基本的索引,它没有任何限制
4.FULLTEXT 全文索引:主要用来查找文本中的关键字,而不是直接与索引中的值相比较。
5.INDEX 组合索引:多个字段上创建的索引
索引的作用
1.快速查找,减少服务器需要扫描的数据量
2.减少IO操作,避免临时表
索引的数据结构
1.Memory存储引擎使用哈希表。
优点:快,在内存中。缺点:不能持久化,重启没有了。
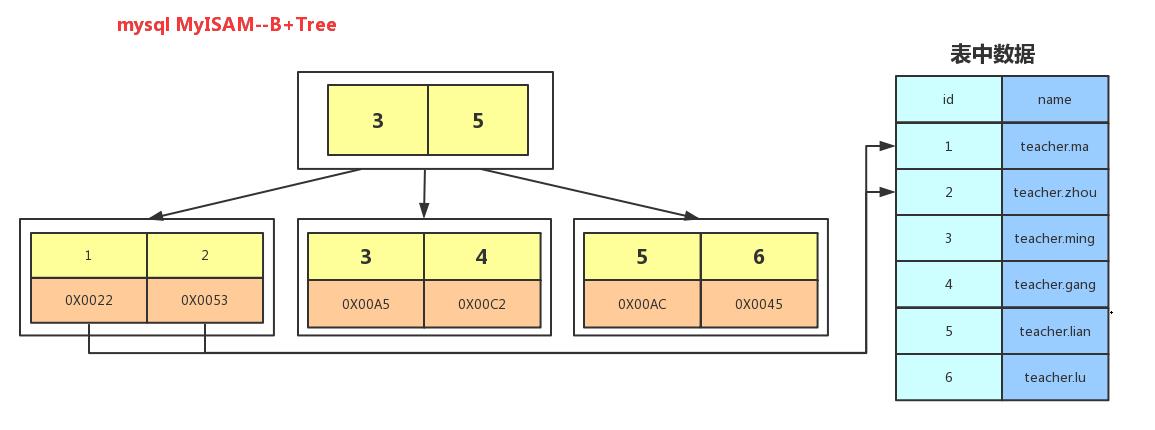
2.Mylsam和InnoDB使用B+树
优点:
1.B+树每个叶子节点可以包含更多的节点(相比于二叉树,平衡二叉树,红黑树等),既降低了树的高度,又将数据范围变为多个区间,加快了检索速度。
2.非叶子节点仅存储key值(B树非叶子节点也存储数据),叶子节点存储key值和数据(Mylsam存储引擎存储的是数据文件的地址)。
3.叶子节点两两之间指针连接,顺序查询性能更高。
聚簇索引和非聚簇索引
聚簇索引
数据和相邻的键值存储在一起;访问速度更快,在同一个树中;使用覆盖索引查询可以直接取出数值。

非聚簇索引
数据文件跟索引文件分开存放,先查询到索引,再去对应的文件位置查询数据
索引B+树的高度计算
B+TREE高度
了解B+Tree索引的大概结构后,我们接下来讲解一下如何计算索引树的高度。
我们先做如下假设:
表的记录数是N;
每个BTREE节点平均有B个索引KEY(即1,2,3,4,5… …),这时候B+TREE索引树的高度就是logB/logN。
另外我们知道,由于索引树每个节点大小固定,所以索引KEY越小,B值就越大,即每个BTREE节点上可以保存更多的索引KEY。并且索引树的高度是logBN,那么B值越大,索引树的高度越小,那么基于索引查询的性能就越高。所以我们可以得到结论:相同表记录数的情况下,索引KEY越小,索引树高度就越小。
每个索引节点一般都是操作系统页的整数倍,操作系统页可通过命令得到该值得大小,且一般是4094,即4k。而InnoDB的pageSize可以通过命令得到,默认值是16k。
关于预读:在索引树上查到某个KEY(例如id=3),需要先找到这个KEY所在的叶子节点(因为B+Tree索引只有叶子节点上有具体的数据),这个查找过程从根节点到叶子节点,需要经过整个树。当找到叶子节点后,会根据预读原理将整个节点数据全部加载到内存中,然后基于二分法找到最终的KEY。
OK,到这里,我们距离真正计算一个拥有1600w数据的表的索引树的高度,只差每个索引KEY所占空间了。
以BIGINT为例,存储大小为8个字节。INT存储大小为4个字节(32位)。索引树上每个节点除了存储KEY,还需要存储指针。所以每个节点保存的KEY的数量为pagesize/(keysize+pointsize)(如果是B-TREE索引结构,则是pagesize/(keysize+datasize+pointsize))。
假设平均指针大小是4个字节,那么索引树的每个节点可以存储16k/((8+4)*8)≈171。那么:一个拥有1600w数据,且主键是BIGINT类型的表的主键索引树的高度就是(log10^7)/log171 ≈ 24/7.4 ≈ 3.2。
假设平均指针大小是6个字节,那么索引树的每个节点可以存储16k/((8+6)*8)≈146。那么:一个拥有1600w数据,且主键是BIGINT类型的表的主键索引树的高度就是(log10^7)/log146 ≈ 24/7.2 ≈ 3.3。
假设平均指针大小是8个字节,那么索引树的每个节点可以存储16k/((8+8)*8)≈128。那么:一个拥有1600w数据,且主键是BIGINT类型的表的主键索引树的高度就是(log10^7)/log128 ≈ 24/7 ≈ 3.4。
由上面的计算可知:一个千万量级,且存储引擎是MyISAM或者InnoDB的表,其索引树的高度在3~5之间。
索引监控
show status like \'Handler_read%\';
Handler_read_first:读取索引第一个条目的次数
Handler_read_key:通过index获取数据的次数
Handler_read_last:读取索引最后一个条目的次数
Handler_read_next:通过索引读取下一条数据的次数
Handler_read_prev:通过索引读取上一条数据的次数
Handler_read_rnd:从固定位置读取数据的次数
Handler_read_rnd_next:从数据节点读取下一条数据的次数
数值越大,说明索引利用率更高
索引使用注意事项
1.回表
主键查询不会触发回表,其他索引会触发回表。
因为innodb的主键索引树叶子结点上保存的是全行数据,主键查询可以一次定位到数据的行数,取出数据内容;
而其他索引需要两次查询,第一次查询到主键值,再根据主键值查询出对应的数据。
2.覆盖索引
explain的输出结果Extra字段为Using index时,能够触发索引覆盖。只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
3.索引覆盖
将需要查询的结果字段建立组合索引
能够一次取出索要查询的结果字段,不需要回表
4.最左匹配
索引查询从最左边开始匹配
组合索引需要考虑索引的顺序和分组的合理性,如下,建立a、b、c三个索引,查询结果如表所示

5.前缀索引
在一个很长的字符串上建立索引,选取长度过长会消耗太多的内存,让索引查询效率变慢,所以需要选择一个合适的长度。
可以截取字符串的前几位和总数做对比,取出一个合适的长度。
前缀索引是一种能使索引更小更快的有效方法,但是也包含缺点:mysql无法使用前缀索引做order by 和 group by。
6.索引下推
mysql默认启用索引下推,我们也可以通过修改系统变量optimizer_switch的index_condition_pushdown标志来控制
SET optimizer_switch = \'index_condition_pushdown=off\';
索引下推适合INNODB引擎的二级索引。即第一次用第一级索引取出符合条件的部分数据,然后第二级别索引继续过滤条件查询,最终结果再回表根据主键查询。如下SQL:
现有student表建有组合索引(name,score),要求查询分数在90分以上且姓赵的同学。
SELECT *FROM student WHERE name LIKE \'赵%\' AND score>90;
先查询出姓赵的同学,然后根据分数过滤拿到主键id,根据主键id回表查询
Like:匹配模式必须要左边确定不能以通配符开头
7.union all,in,or都能够使用索引,但是推荐使用in
必须要保证 OR 两端的条件都存在可以用的索引,该查询才可以使用索引
8.范围列可以用到索引,但是范围列后面的列无法用到索引,索引最多用于一个范围列,范围条件是:<、<=、>、>=、between
9.强制类型转换会全表扫描
本来有一个字符串的字段建立了索引,查询的时候字符串后面匹配一个整型值,会导致全表扫描。
oracle数据库类型不匹配会报错
10.阿里规范,join表最好不超过三张,非要使用在关联条件上创建索引
11.更新频繁的字段不是和建索引,索引维护消耗资源,增删改都会重新更新索引。更新索引时会有页分裂和合并等IO操作。
一般区分度在80%以上的时候就可以建立索引,区分度可以使用 count(distinct(列名))/count(*) 来计算
12.合理使用索引,并不是越多越好。
单表索引建议控制在5个以内
单索引字段数不允许超过5个(组合索引)
能使用limit的时候尽量使用limit