对于上一篇文章,我又自己总结归纳并补充了一下,有了第二篇。
概览
<<左移
开始之前,我们先准备点东西:位运算
i<<n 总结为 i*2^n
所以
1<<5 = 2^5
1<<8 = 2^8
1<<16 = 2^16
1<<32 = 2^32
1<<64 = 2^64
SDS 5种数据类型
Redis 3.2 以后SDS数据类型有5个
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
结合上面的位运算,我们也能理解这5个数据类型的命名规则。
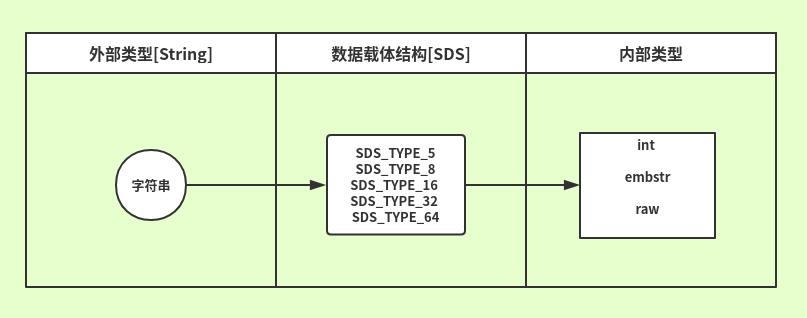
外部类型String 找 SDS结构
我们现在有定义了5种SDS数据类型,那么如何根据字符串长度找这些类型呢?
或者说输入的字符串长度和类型有什么关系?下面我们来看一看他们之间的关系。
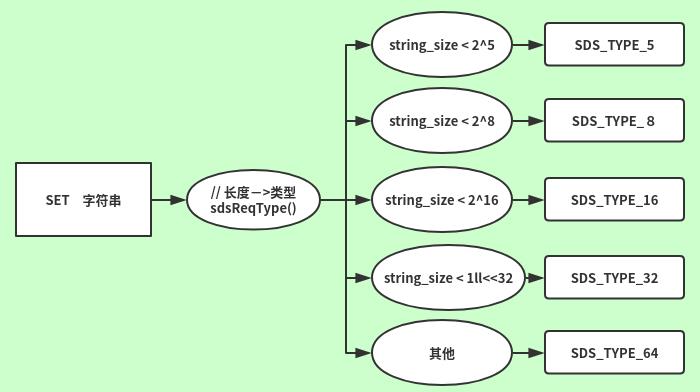
再来看看源码:
static inline char sdsReqType(size_t string_size) {
if (string_size < 1<<5)
return SDS_TYPE_5;
if (string_size < 1<<8)
return SDS_TYPE_8;
if (string_size < 1<<16)
return SDS_TYPE_16;
#if (LONG_MAX == LLONG_MAX)
if (string_size < 1ll<<32)
return SDS_TYPE_32;
return SDS_TYPE_64;
#else
return SDS_TYPE_32;
#endif
}
根据位运算左移公式,我可以得知 1<<8 = 2^8 = 256
那么这里的 256是指什么?这里的256就是字节


也就是说:
SDS_TYPE_5 -- 32 Byte
SDS_TYPE_8 -- 256 Byte
SDS_TYPE_16 -- 64KB
SDS_TYPE_32 -- ...
SDS_TYPE_64 -- ...
现在数据类型找到了,我们再来看看比较典型的几种操作。
追加字符串
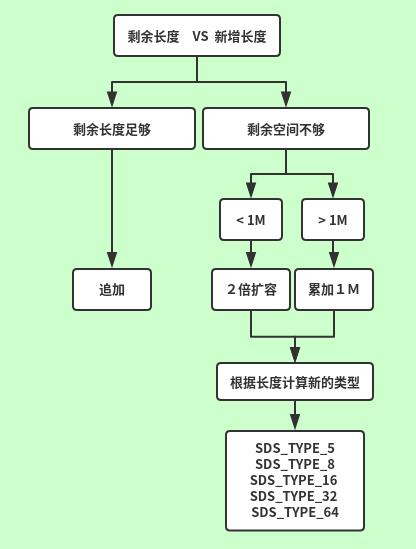
从使用角度讲,追加一般用的频率很少。所以有多大分配多大。
所以这里追加的话,有两种大情况:还有剩余 或 不够用
主要讲一下不够用就要重新申请内存,那么我们如何去申请内存呢?
这里提供了两种分配策略:
<1M ,新空间 = 2倍扩容;
>1M , 新空间 = 累加1M
空间有了,那么我们需要根据最新的空间长度占用,再找到对应的新的SDS数据类型。
看一下源码,增加一下印象:
/* 追加字符串*/
sds sdscatlen(sds s, const void *t, size_t len) {
// 当前字符串长度
size_t curlen = sdslen(s);
// 按需调整空间(原来字符串,要追加的长度)
s = sdsMakeRoomFor(s,len);
// 内存不足
if (s == NULL) return NULL;
// 追加目标字符串到字节数组中
memcpy(s+curlen, t, len);
// 设置追加后的长度
sdssetlen(s, curlen+len);
// 追加结束符
s[curlen+len] = \'\\0\';
return s;
}
/*空间调整,注意只是调整空间,后续自己组装字符串*/
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
// 当前剩下的空间
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* 空间足够 */
if (avail >= addlen) return s;
// 长度
len = sdslen(s);
// 真正的数据体
sh = (char*)s-sdsHdrSize(oldtype);
// 新长度
newlen = (len+addlen);
// < 1M 2倍扩容
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
// > 1M 扩容1M
else
newlen += SDS_MAX_PREALLOC;
// 获取sds 结构类型
type = sdsReqType(newlen);
// type5 默认转成 type8
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
// 头长度
hdrlen = sdsHdrSize(type);
if (oldtype==type) { // 长度够用 并且 数据结构不变
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
// 重新申请内存
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
SDS 和 内部类型
外部字符串类型,找到了SDS结构,现在到了SDS转内部结构
对于字符串类型为什么会分 embstr 和 raw呢?
我们先说一下内存分配器:jemalloc、tcmalloc
这来能为仁兄呢分配内存的大小都是 2/4/8/16/32/64 字节
对于redis 来讲如何利用并适配好内存分配器依然需要好好计算一下。
Redis 给我们实现了很多内部数据结构,这些内部数据结构得有自己的字描述文件-内部结构头对象
不同对象有不同的type,同一个对象有不同的存储形式,还有lru缓存淘汰机制信息,引用计数器,指向数据体的指针。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;
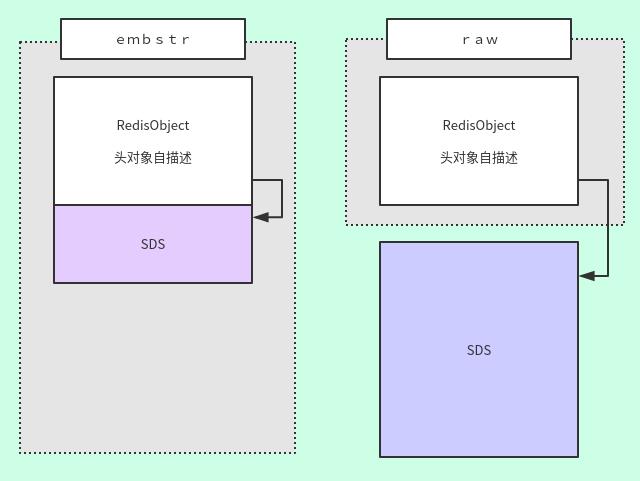
所以SDS和 内部类型的关系类似于这样的:
连续内存,和非连续内存
44 字节
SDS为什么会是这样的两种内部结构呢?
回忆一下上面提到的:SDS结构,最小的应该是 SDS_TYPE_8(SDS_TYPE_5默认转成8)
struc SDS{
int8 capacity; // 1字节
int8 len; // 1字节
int8 flags; // 1字节
byte[] content; // 内容
}
所以从上代码看出,一个最小的SDS,至少占用3字节.
还有内部结构头:RedisObject
typedef struct redisObject {
unsigned type:4; // 4bit
unsigned encoding:4; // 4bit
unsigned lru:LRU_BITS; // 24bit
int refcount; // 4字节
void *ptr; // 8字节
} robj;
16字节 = 32bit(4字节) + 4字节 + 8字节
所以一个内部类型头指针大小为:16字节
再加上最小SDS的3字节,一共 19字节。也就是说一个最小的字符串所占用的内存空间是19字节
还记得上面我们提到过的内存分配器么?(2/4/8/16/32/64 字节)
对,如果要给这个最小19字节分配内存,至少要分配一个32字节的内存。当然如果字符串长一点,再往下就可以分配到64字节的内存。
以上这种形式被叫做:embstr,这种形式使得 RedisObject和SDS 内存地址是连续的。
那么一旦大于64字节,形式就变成了raw,这种形式使得内存不连续,因为SDS已经变大,取得大的连续内存得不偿失。
再回来讨论一下 embstr, 最大64字节内存分配下来,我们实际可以真正存储字符串的长度是多少呢?--44字节
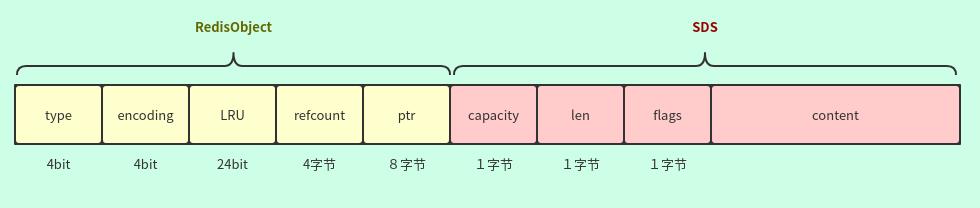
64字节,减去RedisObject头信息16字节,再减去3字节SDS头信息,剩下45字节,再去除\\0结尾。这样最后可以存储44字节。
所以 embstr 形式,可以存储最大字符串长度是44字节。
关于字符串最大是512M
Strings
Strings are the most basic kind of Redis value. Redis Strings are binary safe,
this means that a Redis string can contain any kind of data,
for instance a JPEG image or a serialized Ruby object.
A String value can be at max 512 Megabytes in length.
出个题(redis 5.0.5版本)
SET q sc
encoding:embstr,长度为3

现在做追加操作,APPEND q scadd ,encoding:raw,长度8

为什么从 sc ----> scscadd 简单的追加操作内部类型会从 embstr -----> raw ,如何解释?
喜欢的欢迎加公众号或者留言评论探讨