Spark如何将RDD的前几个元素存入HDFS中。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark如何将RDD的前几个元素存入HDFS中。相关的知识,希望对你有一定的参考价值。
比如,原始RDD内容有:
(44,5)
(34,766)
(23,4545)
(54,56)
(23,67)
(34,67)
想要将括号和第二个参数去掉,并且加上一列序号,并且只取前4个元素存入hdfs中:
1,44
2,34
3,23
4,54
不知道该怎么写scala程序来实现,请各位帮帮忙~
rdd.map(_._1).take(n).map(v =>
val c = count.get
count.add(1)
(c, v)
)saveAsTextfile("hdfs://.....")
hive如何取出数据array的前几个元素
今天遇到个问题,例如
select
company_name,concat_ws(',',collect_set(contract_num)) contract_nums
from table
group by contract_num
如果这个contract_nums数量有100个,我只显示5个。
那么怎么办呢?
1.基础版
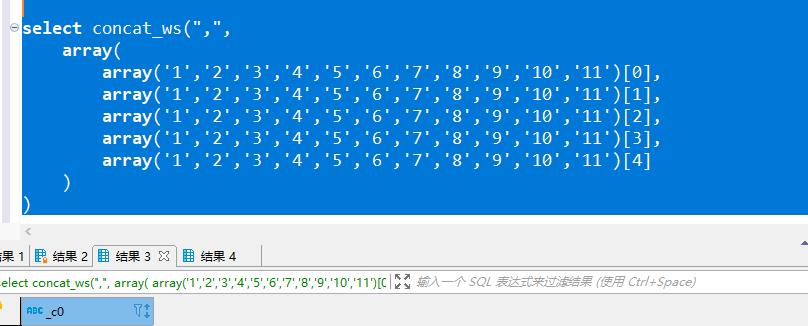
select concat_ws(",",
array(
array('1','2','3','4','5','6','7','8','9','10','11')[0],
array('1','2','3','4','5','6','7','8','9','10','11')[1],
array('1','2','3','4','5','6','7','8','9','10','11')[2],
array('1','2','3','4','5','6','7','8','9','10','11')[3],
array('1','2','3','4','5','6','7','8','9','10','11')[4]
)
)
2.函数版
 select substring_index(concat_ws(",",array('1','2','3','4','5','6','7','8','9','10','11')),',',5)
select substring_index(concat_ws(",",array('1','2','3','4','5','6','7','8','9','10','11')),',',5)
3. row_number 版本
select
company_name ,concat_ws(",",collect_list(contract_num))contract_nums
from (
select company_name,contract_num,
row_number() over(partition by company_name) rn
from (
select 'cclovezbf' as company_name, array('1','2','3','4','5','6','7','8','9','10','11') contract_nums
)t lateral view explode(contract_nums) tmp as contract_num
)t
where rn <5
group by company_name
这个直接跑不出来,报错 IllegalArgumentException Size requested for unknown type: java.util.Collection:
因为collect_list()这个函数和sum 有点不一样,好像是实现类的方法种要计算元素的个数,换成sum也差不多可以看结果了。
以上是关于Spark如何将RDD的前几个元素存入HDFS中。的主要内容,如果未能解决你的问题,请参考以下文章