大数据概述1
Posted georgeleiyi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据概述1相关的知识,希望对你有一定的参考价值。
一、业务架构
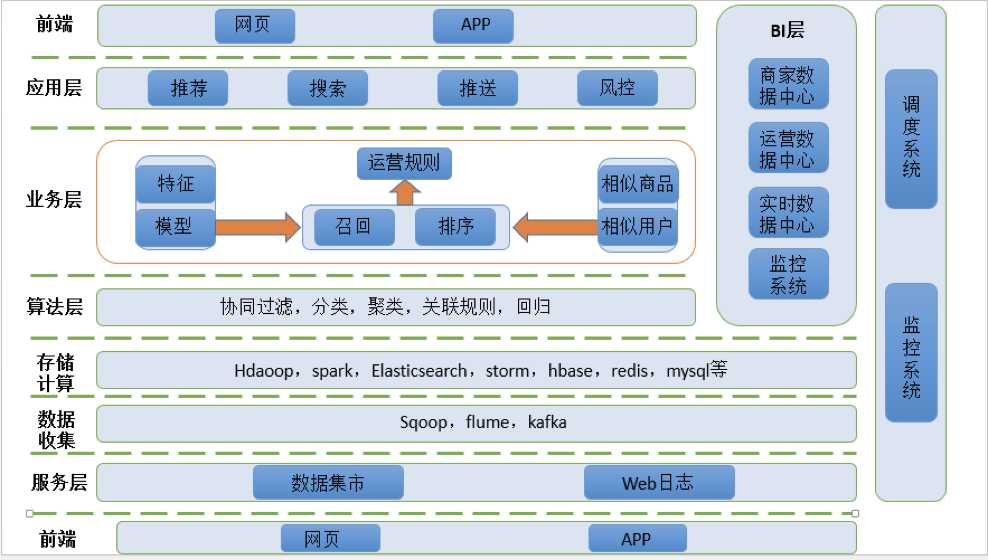
二、大数据全链路架构
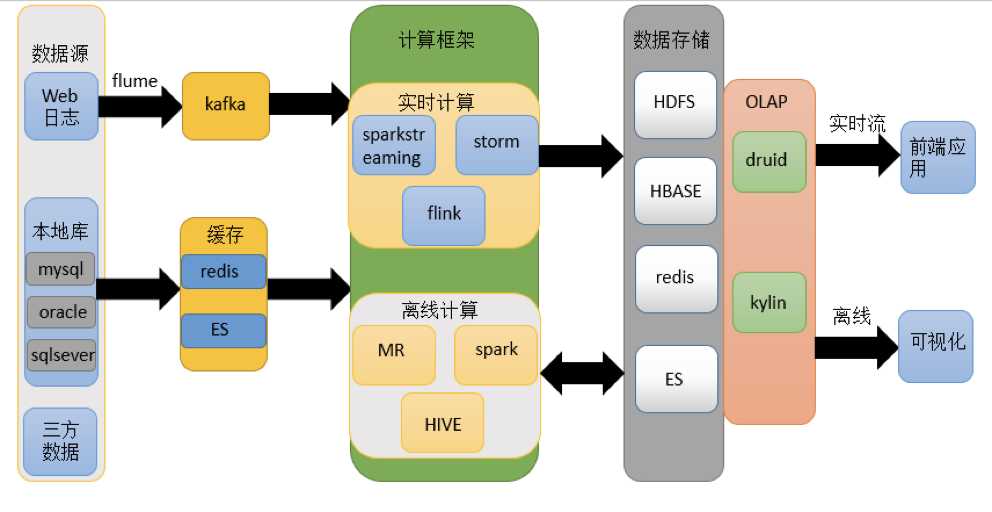
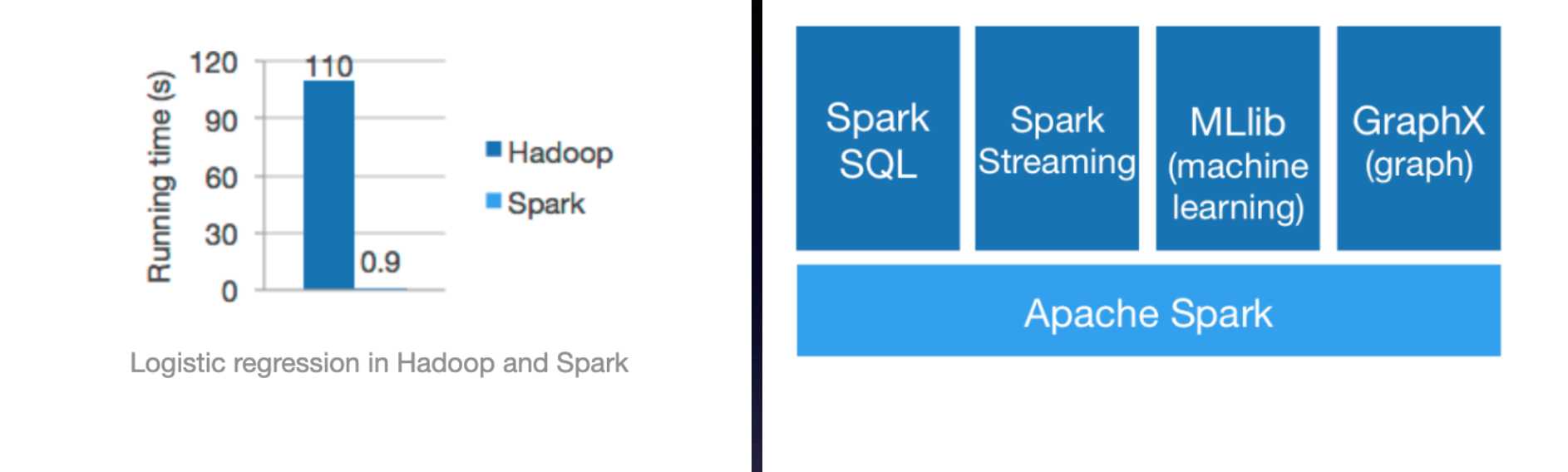
三、主流框架
3.1 第一代大数据框架: 各自为战

3.2 第二代大数据计算框架
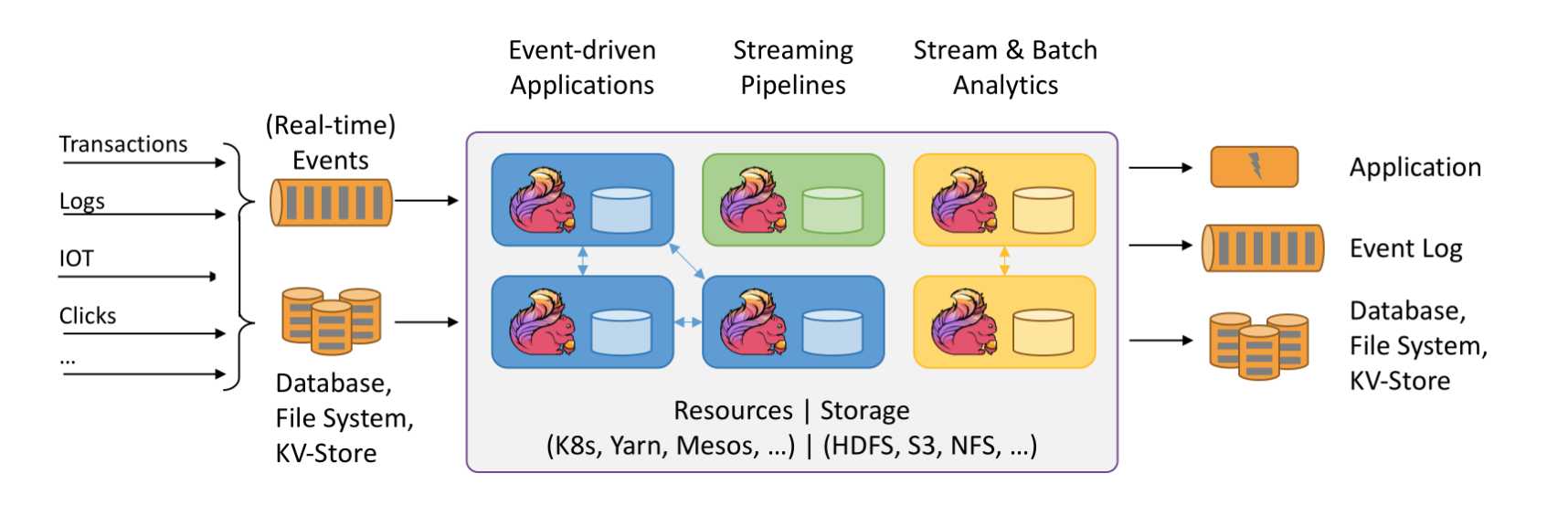
3.3 第三代大数据计算框架 Flink
集群启动
格式化集群
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。格式化操作只有在首次启动的时候需要,以后再也不需要了
node01执行一遍即可
bin/hdfs namenode -format或者bin/hadoop namenode –format
单个节点逐一启动
在主节点上使用以下命令启动 HDFS NameNode:
hadoop-daemon.sh start namenode
在每个从节点上使用以下命令启动 HDFS DataNode:
hadoop-daemon.sh start datanode
在主节点上使用以下命令启动 YARN ResourceManager:
yarn-daemon.sh start resourcemanager
在每个从节点上使用以下命令启动 YARN nodemanager:
yarn-daemon.sh start nodemanager
0以上脚本位于$HADOOP_PREFIX/sbin/目录下。如果想要停止某个节点上某个角色,只需要把命令中的start 改为stop 即可。
脚本一键启动
如果配置了 etc/hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
注意:
启动不了,检查文件的所属用户组和用户,是否是hadoop创建的,修改的命令:
chgrp -R hadoop 文件夹
chown -R hadoop 文件夹
启动集群
node01节点上执行以下命令
第一台机器执行以下命令
cd /kkb/install/hadoop-2.6.0-cdh5.14.2/
sbin/start-dfs.sh
sbin/start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
停止集群:
sbin/stop-dfs.sh
sbin/stop-yarn.sh ?
浏览器查看启动页面
hdfs集群访问地址
http://192.168.52.100:50070/dfshealth.html#tab-overview
yarn集群访问地址
http://192.168.52.100:8088/cluster
jobhistory访问地址:
http://192.168.52.100:19888/jobhistory
我们也可以通过jps在每台机器上面查看进程名称,为了方便我们以后查看进程,我们可以通过脚本一键查看所有机器的进程
所有机器查看进程脚本
在node01服务器的/home/hadoop/bin目录下创建文件xcall
[hadoop@node01 bin]$ cd ~/bin/
[hadoop@node01 bin]$ vim xcall
#添加以下内容
#!/bin/bash
params=$@
i=201
for (( i=1 ; i <= 3 ; i = $i + 1 )) ; do
echo ============= node0$i $params =============
ssh node0$i "source /etc/profile;$params"
done
然后一键查看进程并分发该脚本
chmod 777 /home/hadoop/bin/xcall
xcall jps
xsync /home/hadoop/bin/xcall
一键启动hadoop集群的脚本
我们也可以创建一键启动hadoop的脚本,以后启动hadoop都可以通过一个脚本即可
在node01服务器的/home/hadoop/bin目录下创建脚本
[hadoop@node01 bin]$ cd /home/hadoop/bin/
[hadoop@node01 bin]$ vim hadoop.sh
#!/bin/bash
case $1 in
"start" ){
source /etc/profile;
/kkb/install/hadoop-2.6.0-cdh5.14.2/sbin/start-dfs.sh
/kkb/install/hadoop-2.6.0-cdh5.14.2/sbin/start-yarn.sh
/kkb/install/hadoop-2.6.0-cdh5.14.2/sbin/mr-jobhistory-daemon.sh start historyserver
};;
"stop"){
/kkb/install/hadoop-2.6.0-cdh5.14.2/sbin/stop-dfs.sh
/kkb/install/hadoop-2.6.0-cdh5.14.2/sbin/stop-yarn.sh
/kkb/install/hadoop-2.6.0-cdh5.14.2/sbin/mr-jobhistory-daemon.sh stop historyserver
};;
esac
修改脚本权限
[hadoop@node01 bin]$ chmod 777 hadoop.sh
以上是关于大数据概述1的主要内容,如果未能解决你的问题,请参考以下文章