如何获取redis内的所有内容
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何获取redis内的所有内容相关的知识,希望对你有一定的参考价值。
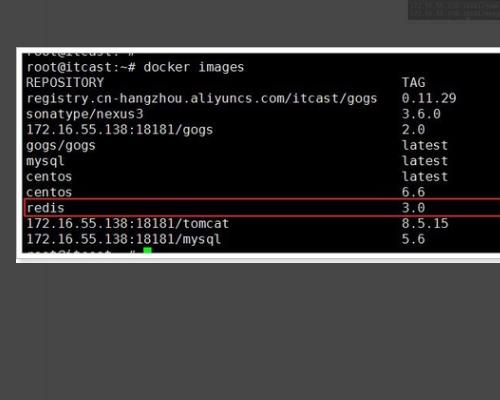
1、到远程的仓库进行搜索。
2、点击查看详情,查看tag。
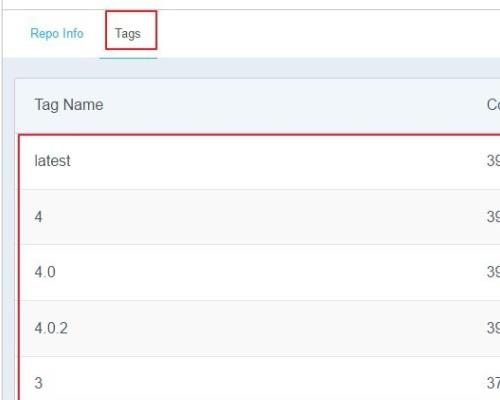
3、找到我们想要的3.0.0,最新的tag可以用latest标识。
4、执行命令:docker pull redis:3.0。
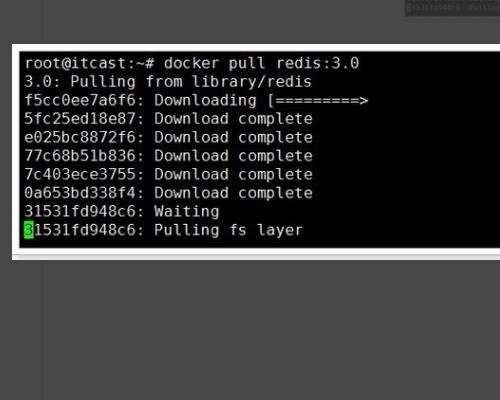
5、通过docker images查看镜像。
2、使用HSCAN 迭代哈希键中的键值对;
最后,hash的HGETALL在生产环境一定要慎用啊!!本回答被提问者采纳
如何在 Javascript 中获取 HTML 标记内的内容(仅)到单级?
【中文标题】如何在 Javascript 中获取 HTML 标记内的内容(仅)到单级?【英文标题】:How to get content (only) inside HTML tag up-to single level in Javascript? 【发布时间】:2019-11-10 10:13:47 【问题描述】:TLDR:这个问题需要 javascript 解决方案Search and replace HTML Text, not tags
我已经通过很多答案说明不使用 RegX,但没有人对此给出确切的解决方案。我想遍历页面上的每个 DOM 元素。根据其文本查找一个单词并在单词的相同位置替换一个 HTML。
$(document).ready(function()
function isJson(item)
item = typeof item !== "string"
? JSON.stringify(item)
: item;
try
item = JSON.parse(item);
catch (e)
return false;
if (typeof item === "object" && item !== null)
return true;
return false;
function loop(elements, words)
elements.each(function()
element = $(this);
var text = element.html();
for (k in words)
if(isJson(words[k]))
defObj = JSON.parse(words[k]);
for (var j = defObj["data"].length - 1; j >= 0; j--)
if (defObj["data"][j]["definition"])
liText = (defObj["data"][j]["wordtype"] ? defObj["data"][j]["wordtype"] : defObj["data"][j]["partOfSpeech"]) + "; "+ defObj["data"][j]["definition"];
else
liText = defObj["data"][j]["translatedText"];
else
liText = words[k];
li = '<li>'+liText+'</li>';
ol = '<ol style="padding: 15px !important; padding-right: 0px !important; margin: 0 auto !important;">'+li+'</ol>';
var regex = new RegExp('(\\b)'+k+'(\\b)', 'ig');
// replace the matched word with the ol list created above.
text = text.replace(regex, ol);
if (element.html() !== text)
element.html(text);
)
function getElements(el)
return $(el).withinviewport();
chrome.storage.sync.get(null, function(result)
//result is an object literal with words as key and its meaning as json string
if (result)
loop($("li"), result);
loop($("h5"), result);
loop($("h6"), result);
);
); 到目前为止,上面的代码做得很好。但它错过了以下情况,以 settle 关键字为例,我不想匹配以下情况,但我的正则表达式也匹配这些。
1. <h5 title="this settle line should not match"> This settle line should match </h5>
2. <li> this settle line should match <div> this settle line should not match </div> </li>
3. <li> <a href="abc"> this settle line should not match </a> this settle line should match </li>
4. <h6> this settle line should match
<div>
something random without settle word, so should not match
<h6> this settle line should also not match </h6>
</div>
</h6>
如果我想用文本替换这些情况可以避免。但是对于 HTML,如果标签中的某些内容匹配,它会破坏布局。我从2年开始就面临这个问题,请帮忙。我愿意接受任何解决方案。
【问题讨论】:
您的 sn-p 不起作用,""ReferenceError: $ is not defined","您使用任何 javascript 库吗?你能举一个改变前的整个网站和改变后的整个页面的例子吗?最好作为网站链接。 【参考方案1】:我的答案是指问题的第一部分,“在示例中的 python 中执行相同的操作:Search and replace HTML Text, not tags”
在此基础上,您应该弄清楚如何开发一个解决方案,以更改问题第 2 部分中描述的标签内容。
代码有效,但它只是一个概念,需要重构。
// the data:
var input = '<!DOCTYPE html>\
<html>\
<head>\
<title>Hello HTML</title>\
</head>\
<body>\
<a href="#">abc</a>\
<p>Hello 1</p>\
<p>Hello 2</p>\
<p>Hello 3</p>\
<p>Hello 4</p>\
</body>\
</html>';
function string2xml(text)
try
var xml = null;
if (window.DOMParser)
var parser = new DOMParser();
xml = parser.parseFromString(text, 'text/xml');
var foundErr = xml.getElementsByTagName('parsererror');
if (!foundErr || !foundErr.length || !foundErr[0].childNodes.length)
return xml;
return null;
catch (e)
;
// xml object input data:
var xmldoc = string2xml(input);
var out='';
out += '<!DOCTYPE html><html>';
// the head nodes:
out += xmldoc.getElementsByTagName('head')[0].outerHTML;
out += '<body>\n';
// the body nodes:
var nodes=xmldoc.getElementsByTagName('body')[0].children;
for (var i = 0; i < nodes.length; i++)
if(nodes.item(i).nodeName == 'p')
regex=/^[^4]*$/;
out += '<p>'+(nodes.item(i).innerHTML).replace(regex,"replaced")+'</p>\n';
else
out += nodes.item(i).outerHTML+'\n';
out += '</body></html>';
// the output data:
console.log(out);【讨论】:
以上是关于如何获取redis内的所有内容的主要内容,如果未能解决你的问题,请参考以下文章
如何使用正则表达式获取 `<body>` 标签内的全部内容?