Hadoop原生搭建
Posted zxd-8520
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop原生搭建相关的知识,希望对你有一定的参考价值。
版本:(centos7.6)
在开始搭建平台前我已经预装了mysql
ps:MySQL创建用户并授权:
1 grant all privileges on *.* to ‘root‘@‘localhost‘ identified by ‘123456‘ with grant option
好了,不多说,开始配置:
我采用了master,slave1,slave2三个节点,我自己是利用kvm化的虚拟机。
对应IP地址:
master:172.16.90.145
slave1:172.16.90.147
slave2:172.16.90.148
1、为了方便,加上自己在虚拟机上搭建,关闭Selinux,firewalld
2、更改hosts,即配置主机映射,更改完成scp拷贝
echo ‘172.16.90.145 master‘ >> /etc/hosts echo ‘172.16.90.147 slave1‘ >> /etc/hosts echo ‘172.16.90.148 slave2‘ >> /etc/hosts scp /etc/hosts slave1:/etc/hosts scp /etc/hosts slave2:/etc/hosts
3、配置ssh免密:(这里为了方便我设置的空密码,并做的三方免密)
ssh-keygen ssh-copy-id master ssh-copy-id slave1 ssh-copy-id slave2
4、安装jdk(即Java)
导入jdk后解压,创建软连接,加入环境变量,source环境变量文件,最后查看版本号
tar zxvf jdk-8u111-linux-x64.tar.gz ln -s /usr/local/jdk1.8.0_111 /usr/local/java echo ‘export PATH=$PATH:$JAVA_HOME/bin‘ >> /etc/profile echo ‘JAVA_HOME=/usr/local/jdk1.8.0_111‘ >> /etc/profile source /etc/profile java -version
5、安装Hadoop:
解压
tar zxvf hadoop-2.9.0.tar.gz
创建软连接
ln -s /usr/local/hadoop-2.9.0/ /usr/local/hadoop
加入环境变量并使之生效
echo ‘HADOOP_HOME=/usr/local/hadoop-2.9.0/‘ >> /etc/profile echo ‘export PATH=$PATH:$HADOOP_HOME/bin,sbin‘ >> /etc/profile source /etc/profile
修改配置文件
在master主机上建立namenode本地数据目录
mkdir -p /data/nn
在slave1,slave2中建立datanode本地数据目录
mkdir -p /data/dn
在master中编辑core-site.xml,在 <configuration> 节点中增加如下内容
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
在master中编辑 hdfs-site.xml,在 <configuration> 节点中增加如下内容
<property>
<name>dfs.nameslave.name.dir</name>
<value>file:///data/nn</value>
</property>
<property>
<name>dfs.dataslave.data.dir</name>
<value>file:///data/dn</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.nameslave.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</proper
在master中,将mapred-site.xml.template 复制一份 ,变成mapred-site.xml,编辑mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master:9001</value>
</property>
在master中,编辑yarn-site.xml,
<property>
<name>yarn.slavemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.slavemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.slavemanager.resource.memory-mb</name>
<value>2048</value>
</property>
将 master服务器上已经完成的 hadoop 配置 复制到各个节点对应位置上,输入以下命令进行 scp 传送:
scp -r /usr/local/hadoop/* slave1: /usr/local/hadoop/ scp -r /usr/local/hadoop/* slave2: /usr/local/hadoop/
在master中,初始化hadoop的namenode
启动hadoop
hadoop-daemon.sh namenode -format
./start-all.sh
最后使用jps命令查看节点启动的服务是否正确
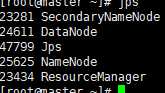
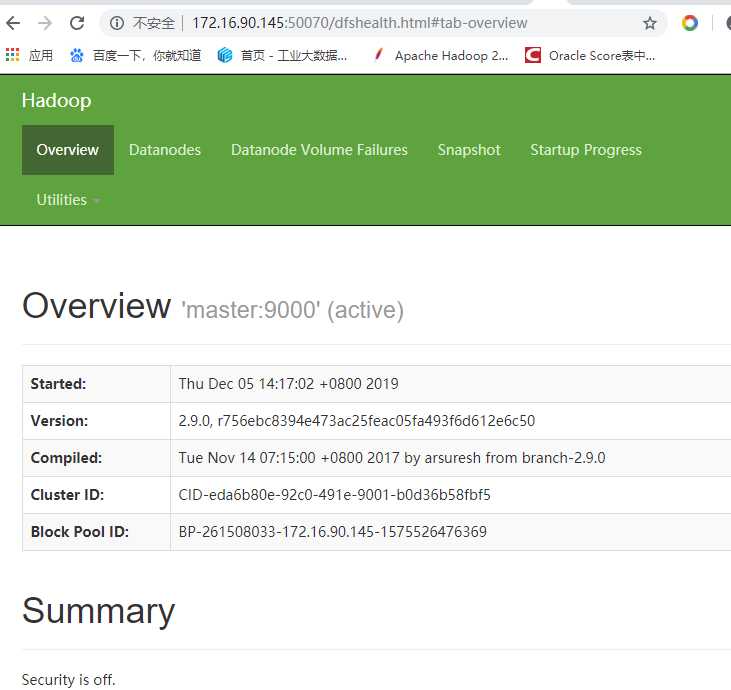
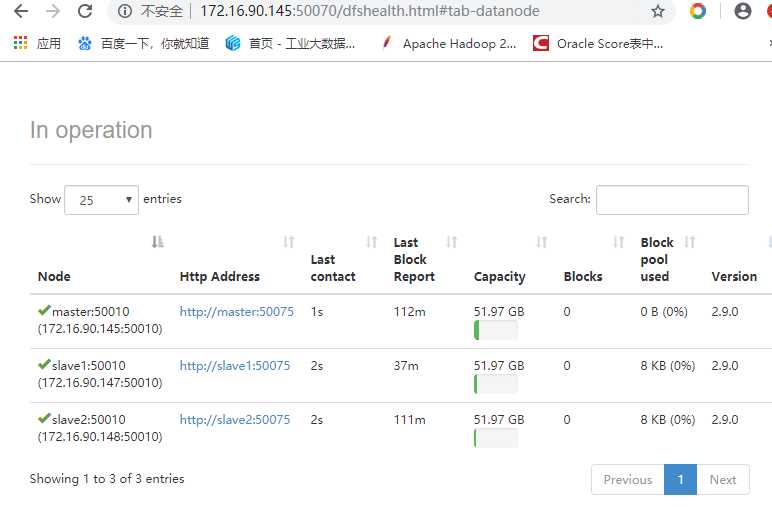
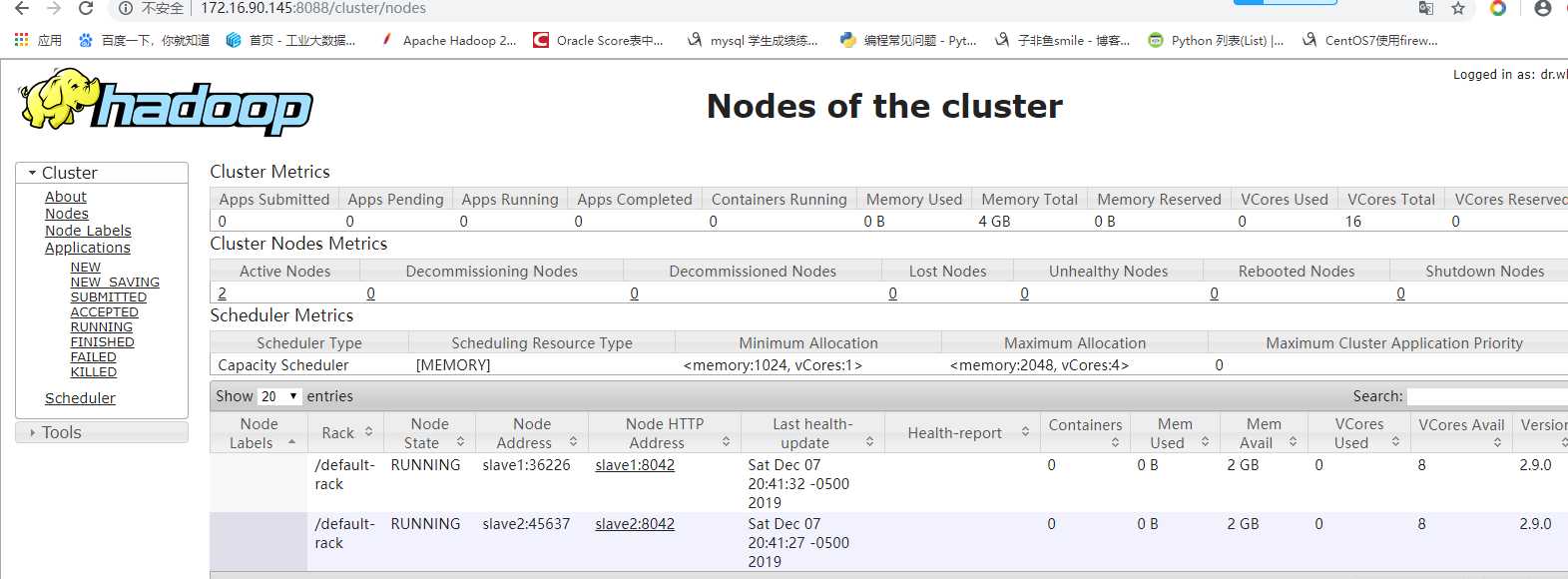
启动成功可以查看web界面了
以上是关于Hadoop原生搭建的主要内容,如果未能解决你的问题,请参考以下文章