python urllib2.urlopen(url).read()乱码
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python urllib2.urlopen(url).read()乱码相关的知识,希望对你有一定的参考价值。
url="http://www.google.com/"
content = urllib2.urlopen(url).read()
print content
结果如图所示,所有网页内的内容都是乱码(除了html代码本身)。试了好几个网页都是这样,不知该怎么办?
运行环境是ubuntu 32位,python版本为2.7
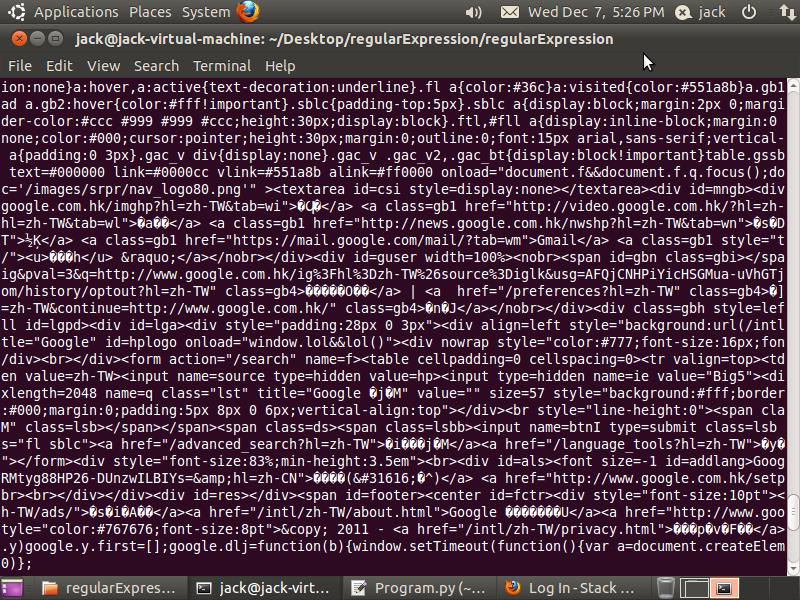
url="网址"
content = urllib2.urlopen(url).read()
print content.decode('big5').encode('utf8') 参考技术A 修改你的编码吧。估计是因为你的shell编码格式和网页编码格式不一致。google应该是UTF8编码。 参考技术B 在python脚本的第二行制定utf-8编码。若还不行,需要先把输入的网页给iconv转编码~ 参考技术C 你指定一下编码格式吧,试一下gb2312
文件头加上这句
# -*- coding: gb2312 -*-
Python urllib2爬虫豆瓣小说名称和评分
#-*- coding:utf-8 -*- import urllib2 import re url = ‘https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4‘ request = urllib2.Request(url) urlopen = urllib2.urlopen(request) content = urlopen.read() reg_0 = re.findall(r‘title.+"\s*on‘, content) reg_1 = re.findall(r‘rating_nums">.*<‘, content) for title,score in zip(reg_0,reg_1): title = re.split(r‘"‘,title) score = re.split(r‘>|<‘,score) print title[1],score[1] #<span class="rating_nums">8.6</span>