mysql中如何找出重复数据的所有行
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql中如何找出重复数据的所有行相关的知识,希望对你有一定的参考价值。
不是只找出所有指定字段重复的数据对应行id最小的,而是所有的都查出来
上图是查出来的结果,里面还有其它的如张三 三级就可以不显示
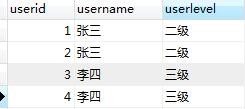
先找出没有重复的userid,然后过滤这些userid,其余的就是有重复的了
参考技术A group的同时count(*),count(*)>1的都是有重复的。追问
写个完整的mysql,可以吗?我的意思是查出来有username 和userlevel字段同时重复的,所有行号即userid
删除 MySQL 中除 One 之外的所有重复行? [复制]
【中文标题】删除 MySQL 中除 One 之外的所有重复行? [复制]【英文标题】:Delete all Duplicate Rows except for One in MySQL? [duplicate] 【发布时间】:2011-06-08 18:46:30 【问题描述】:如何从 MySQL 表中删除所有重复数据?
例如,使用以下数据:
SELECT * FROM names;
+----+--------+
| id | name |
+----+--------+
| 1 | google |
| 2 | yahoo |
| 3 | msn |
| 4 | google |
| 5 | google |
| 6 | yahoo |
+----+--------+
如果是SELECT 查询,我会使用SELECT DISTINCT name FROM names;。
我将如何使用 DELETE 执行此操作以仅删除重复项并仅保留每个记录?
【问题讨论】:
***.com/questions/3311903/… 和 ***.com/questions/2867530/… 的重复项(具有讽刺意味。) 这不是一个完全重复的问题,因为它专门要求 DELETE 命令执行与添加唯一索引的 ALTER 命令相同的操作,以使 MySQL 自动删除重复行。在这种情况下,我们选择删除重复项的确切方式。 那么关于重复的问题有重复吗?嗯 【参考方案1】:编辑警告:此解决方案计算效率低下,可能会导致大型表的连接中断。
注意 - 您需要首先在您的表的测试副本上执行此操作!
当我这样做时,我发现除非我还包含AND n1.id <> n2.id,否则它会删除表格中的每一行。
如果要保留id 值最低的行:
DELETE n1 FROM names n1, names n2 WHERE n1.id > n2.id AND n1.name = n2.name
如果要保留id 值最高的行:
DELETE n1 FROM names n1, names n2 WHERE n1.id < n2.id AND n1.name = n2.name
我在 MySQL 5.1 中使用了这种方法
不确定其他版本。
更新:由于人们在谷歌上搜索删除重复项最终会出现在这里
虽然OP的问题是关于DELETE,但请注意使用INSERT和DISTINCT要快得多。对于一个有 800 万行的数据库,下面的查询耗时 13 分钟,而使用 DELETE,耗时 2 个多小时,但仍未完成。
INSERT INTO tempTableName(cellId,attributeId,entityRowId,value)
SELECT DISTINCT cellId,attributeId,entityRowId,value
FROM tableName;
【讨论】:
优秀的解决方案。它工作得很好。但我有一个建议,我们应该交换条件。而不是 [WHERE n1.id > n2.id AND n1.name = n2.name] 我们应该写 [WHERE n1.name = n2.name AND n1.id > n2.id] 如果我们有这么多,它会提高性能数据。 仅供参考:这将忽略列“名称”为空的行。 这个答案中的 NB 是非常重要的孩子。但这是一个优秀的MySQL。请注意,对于可能重复多次重复的表,您还需要一个GROUP BY n1.id 子句。
我喜欢这个解决方案,但你有什么建议可以在更大的表上优化它吗?
在 10,000 条记录的表上花费了 171 秒,其中有 450 个重复项。 OMG Ponies 的回答耗时 4 秒。【参考方案2】:
如果要保留id 值最低的行:
DELETE FROM NAMES
WHERE id NOT IN (SELECT *
FROM (SELECT MIN(n.id)
FROM NAMES n
GROUP BY n.name) x)
如果您想要最高的id 值:
DELETE FROM NAMES
WHERE id NOT IN (SELECT *
FROM (SELECT MAX(n.id)
FROM NAMES n
GROUP BY n.name) x)
子查询中的子查询对于 MySQL 是必须的,否则会报 1093 错误。
【讨论】:
“x”有什么作用? @GDmac 它用作内部查询的别名。如果不指定,会抛出错误。 @wbinky 它用作内部查询的别名。如果不指定,会抛出错误。 但是 x 是干什么用的? (开个玩笑) 看来这个 sql 也删除了唯一的行。实际上所有行以上是关于mysql中如何找出重复数据的所有行的主要内容,如果未能解决你的问题,请参考以下文章