大数据组件——nova
Posted 东木刀纹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据组件——nova相关的知识,希望对你有一定的参考价值。
nova提供了一种配置计算实例,支持创建虚拟机,裸机服务器。nova在linux上作为一组守护进程运行,以提供该服务
nova分成两类节点:一个是nova-compute计算节点,另一个是控制节点
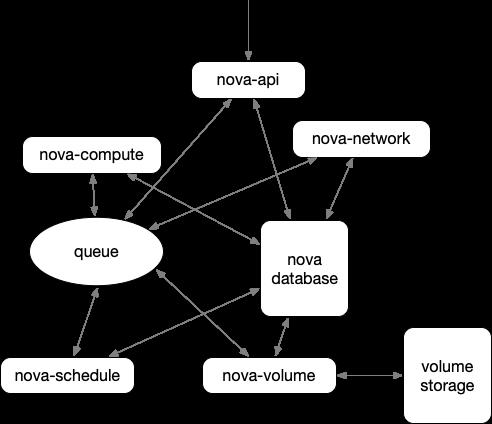
API部分
nova api:负责接收和响应外部请求,外部访问nova的唯一途径,接受外部请求并通过Message Queue将请求发送给其他的服务组件
Compute Core部分
nova scheduler:云主机调度,决策虚拟机应该创建在哪个计算节点上。决策一个虚拟机应该调度到哪个物理节点上(过滤,计算权值)
nova computer:运行在计算节点上,通过message queue接收并管理KVM的生命周期。管理虚拟机的核心服务,通过调用hypervisor API实现虚拟生命周期管理
hypervisor:计算节点上跑的虚拟化管理程序,虚拟机管理最底层的程序。不同虚拟化技术提供自己的hypervisor
nova conductor:计算节点访问数据库的中间件,nova-computer经常需要更新数据库(比如虚拟机环境),但不会直接访问数据库,而是将这个任务委托给nova-conductor
Console Interface部分
nova consoleauth:控制台的授权验证,需要打开vnc需要在consoleauth进行授权认证
nova-console: 用户可以通过多种方式访问虚机的控制台,例如nova novncporxy:提供一个代理,用来访问正在运行的实例;nova-spicehtml5proxy:基于html5浏览器的spice访问
nova cert:服务器守护进程向nova cert服务提供x509证书
其他一些概念
消息队列:在守护进程之间传递消息的中心。nova通过message queue作为子服务的信息中转站
SQL数据库:存储云主机在构建时和运行时的状态,为云基础设施,包括:可用实例类型,使用中的实例,可用网络,项目
flavor:规定了主机的内存,cpu等的大小,并且可以用来限制虚拟机的一系列参数,使用同一个flavor创建出来的虚拟机,在规格上基本保持一致
availability_zones:可用区是主机的聚合,主机组可以认为是可用区的进一步划分,主机组只对管理员可见而可用区用户可见(主机可以属于多个组,但只属于一个可用区)
host aggregates:主机组是一组主机compute节点的集合,默认只开放给管理员,可以通过策略配置修改访问权限
aggregates:主机组管理metadata,可以向主机中添加,或者移除一个主机,也可以管理metadata
常用的一些nova命令
nova help |grep flavor
查询对应ip主机的uuid:nova list | grep ip
查询虚机:nova show uuid
查询flavor:nova flavor-show flavor_id
nova_aggregate 一些常用命令
nova aggregate-create <name> [<availability-zone>]
<name> 集合的名称; <availability-zone> 集合的可用域
nova aggregate-delete <aggregate>
<aggregate> 聚合的名称或ID
nova aggregate-add-host <aggregate> <host>
<aggregate> 聚合的名称或ID; <host> 添加到指定聚合的主机
nova aggregate-remove-host <aggregate> <host>
<aggregate> 聚合的名称或ID; <host> 指定聚合的主机
nova aggregate-list
以上是关于大数据组件——nova的主要内容,如果未能解决你的问题,请参考以下文章