关于MySQL的一些骚操作——提升正确性,抠点性能
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于MySQL的一些骚操作——提升正确性,抠点性能相关的知识,希望对你有一定的参考价值。
概要
回顾以前写的项目,发现在规范的时候,还是可以做点骚操作的。
假使以后还有新的项目用到了mysql,那么肯定是要实践一番的。
为了准备,创建测试数据表(建表语句中默认使用utf8mb4以及utf8mb4_unicode_ci,感兴趣的读者可以自行搜索这两个配置):
CREATE TABLE `student` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`no` int(11) unsigned NOT NULL DEFAULT ‘0‘ COMMENT ‘编号‘,
`name` varchar(30) NOT NULL COMMENT ‘名称‘,
PRIMARY KEY (`id`),
UNIQUE KEY `unq_no` (`no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;插入冲突时更新数据
SQL执行插入时,可能因为种种原因插入失败,比如UNIQUE索引冲突导致插入失败。比如某个不晓得DBA插入了一条错误的学生记录("3", "小明"),悲剧的是小明的编号是1。常规做法就是判断当前的数据库记录中是否存在小明的记录,如果有则更新其对应其编号,否则就插入小明的记录。当然存在更好的做法:
INSERT INTO student(`no`, `name`) VALUES (3, "xiaoming");
INSERT INTO student(`no`, `name`) VALUES (1, "xiaoming"), (2,"xiaohong")
ON DUPLICATE KEY UPDATE `no` = VALUES(`no`);那就是使用ON DUPLICATE KEY UPDATE,这是mysql独特的语法(语句后面可以放置多个更新条件,每个条件使用逗号隔开即可)。需要注意,这里的VALUES(no)是将冲突的no数值更新为用户插入数据中的no,这样每条冲突的数据就可以动态的设置新的数值。
忽略批量插入失败中的错误
批量插入比单条数据挨个插入,普遍会提高性能以及减少总的网络开销。但是,假如批量插入的数据中心存在一个臭虫,在默认的情况下,这就会导致批量插入失败(没有一条数据插入成功)。当然,我们可以选择忽略,MongoDB都能够做到的事情,MySQL自然是可以做到。
INSERT INTO student(`no`, `name`) VALUES (1, "xiaoming");
INSERT IGNORE INTO student(`no`, `name`) VALUES (1, "xiaoming"), (2,"xiaohong"),(3, "xiaowang");只需要在批量插入的语句中,插入IGNORE,那么某几条数据的插入失败就会被忽略掉,正确的数据依然可以插入库中。但是,我建议这个功能谨慎使用,使用mysql数据库本身就是看中数据的正确性,没必要为了批量插入的性能而自动放弃数据的正确性,如果真心觉得这个数据不重要,那么为什么不将此数据存入NoSQL中呢,MongoDB就是不错的选择。
IGNORE还有些副作用,感兴趣的可以自行查询。
使用JOIN替换子查询
MySQL的子查询优化不是太好,它的运行有点反我们的直觉(我们写的代码终究会在某些时候和我们的直觉相悖,这大概就是优化产生的根源之一吧)。其中最糟糕的一类是WHERE子句中包含IN的子查询语句(详情可见《高性能MySQL》一书的6.5章节,标题名字起得就很nice,为MySQL查询优化器的局限性)。概括下就是在部分情况下,在部分情况下MySQL可能会在挨个执行外部记录时执行子查询,如果外部记录数量较大,那么性能就会堪忧。
SELECT * FROM student WHERE no > (SELECT no FROM student WHERE `name`=‘xiaoming‘);
SELECT s.* FROM student s JOIN (SELECT no FROM student WHERE `name`=‘xiaoming‘) t ON s.no > t.no;看上述代码,可以知道使用JOIN还是比较容易替换子循环,代码虽然会稍显晦涩,但是也许可以避免在并发量大的某个晚上你被叫起来检讨自己的错误。MySQL一直在优化子查询,在部分条件下子查询可能会比JOIN具有更高的效率,因此在有时间进行验证的情况下选择最佳的SQL语句。
JOIN中的WHERE和AND坑
为了更好的说明坑,我这里需要创建一个新的表,并在原来的学生表中添加字段:
CREATE TABLE `class` (
`id` smallint(6) unsigned NOT NULL AUTO_INCREMENT,
`no` int(10) unsigned NOT NULL COMMENT ‘编号‘,
`name` varchar(30) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT ‘名称‘,
PRIMARY KEY (`id`),
UNIQUE KEY `unq_no` (`no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
ALTER TABLE `student`
ADD COLUMN `cls_no` smallint(6) unsigned NOT NULL DEFAULT 0 AFTER `no`;伪造一些数据,假设有4个班级,4班没有相对应的学生。使用如下的查询语句就能发现不同之处:
select c.*, s.`name` from class c left join student s on c.no = s.cls_no and c.no < 4 order by c.no asc;查询结果如下图所示:
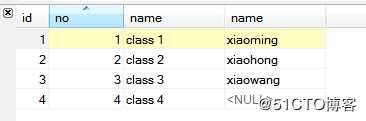
需要注意的是,此处我再查询条件中设置了c.no < 4这一JOIN条件,但是明显的没有起到作用,查询结果中仍然显示了no=4的结果,这是因为此次查询使用的JOIN是LEFT JOIN,class作为左表,在匹配条件无法完全满足的情况下,亦会将左表的所有数据显示出来,引入了NULL值。
换成使用WHERE呢,参照下句:
select c.*, s.`name` from class c left join student s on c.no = s.cls_no where c.no < 4 order by c.no asc;查询结果如下图所示:
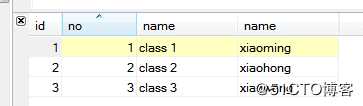
为什么同样是使用LEFT JOIN,查询结果就不同了呢?这是因为可以认为SQL是分成两部分进行执行的(伪SQL,意思到位):
(1) select c., s.name?from class c left join student s on c.no = s.cls_no as tmn;
(2)select c., s.name?from tmp where c.no < 4 order by c.no asc;
需要注意的是,此处首先执行JOIN部分查询,再对查询结果执行WHERE。在执行INNER JOIN时,以上问题还可以忽略,但是如果使用的是LEFT JOIN或者RIGHT JOIN,则需要加倍小心查询条件了。
分页查询优化
查询的优化,最初是在研究MongoDB的分页查询时学到的,只能说大多数的数据库都是差不多的(当然现在存在时序数据库,分页查询那是更加骚气的)。大多数的分页查询都是类似如下的写法:
SELECT * FROM student WHERE cls_no > 1 LIMIT 1000, 10 ORDER BY id;这样的写法存在性能损耗,数据库会将所有符合条件的数据查询出来,挨个数到第1000条记录,最后选取前10条记录进行交差。前面的1000条数据,就会显得很浪费,在LIMIT数值很大的情况下,这个性能损耗就是无法忍受的了(百度就会默认禁止查询76页以后的数据)。
因为分页一般是逐页翻下去的(如果是跳页进行查询,那就只能用上面的查询语句慢慢查询搜寻结果了),那么每次分页完都能获取当前的最大ID,我们可以基于ID确定我们的搜索起始点,基于此点向后查询10条满足要求的结果,改动如下(让前端多传一个当前页的最大ID,这个小小的要求当然是可以满足的):
SELECT * FROM student WHERE id > 1000 AND cls_no > 1 LIMIT 10 ORDER BY id;以上是基于当前的ID是连续ID(其中若干记录没有被物理删除掉),如果是非连续ID,那么基于ID确定起始查询点是不恰当的,此时我们就可以使用JOIN:
SELECT s.* FROM student s JOIN (SELECT id FROM student LIMIT 1000, 10) t ON s.id = t.id;其实,此处我们是id的索引表,从而快速的确定ID,因此查询简化成根据索引表查询的ID确定数据记录(不过需要注意,此处的索引表是无法添加WHERE子句的),因此这种写法在实际环境中几乎是个鸡肋。
UPDATE/DELETE改动多个表记录
工作中,经常需要修改多个表中的关联记录。一般的做法是将相关表中的记录查询出来,再挨个进行修改。如果修改的逻辑较为复杂,那么这样做是没有问题的,但是若是只是简单的修改(比如修改boolean变量),那么可以通过一条SQL语句完成此任务。
SQL中只要提及多个表,那么大致上就会出现JOIN的身影。我们有个需求,就是将3班的学生转移到5班(原有的3班更改为5班),使用JOIN语句的话就可以按照如下方式完成任务。
UPDATE student s JOIN class c ON c.no =3 AND c.no = s.cls_no SET c.no = 5, s.cls_no = 5; 通过JOIN既可以完成此任务,可以拓展到修改多个表中数据内容,也可以扩展至DELETE语句中。
SELECT COUNT(*)/COUNT(1)/COUNT(列名)掉书袋
此处,就简单的总结一下:
- SELECT COUNT(*):是SQL 92中定义的标准统计行数的语法(所以肯定是做了很多优化的);
- SELECT COUNT(1): 查询符合条件的行数;
- SLECT COUNT(列名): 查询符合条件的,且指定的列名所对应值非NULL行数。
对于SELECT COUNT(*)/COUNT(1),在MySQL的官方文档中,其实现思路是一样的,不存在性能差异,那么自然是推荐更加标准的写法了。
以上是关于关于MySQL的一些骚操作——提升正确性,抠点性能的主要内容,如果未能解决你的问题,请参考以下文章
最新 IDEA 2022.1 版本即将发布,骚操作真不少...