javascript中的事件处理函数中的return false/true问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了javascript中的事件处理函数中的return false/true问题相关的知识,希望对你有一定的参考价值。
就是javascript里 事件处理函数中 return false /true 什么意思 这是我在网上找的答案(还不是太明白) 在所有的事件(onkeypress、onmouseover、onclick等)处理代码里面,如果最后一个处理语句的结果为false,则原定的事件停止执行(所写的代码取代原来的功能),否则原定的事件继续执行(所写的代码添加在原来功能的前面)。 我还买了本书 书中有个例子我不太明白 例子如下 <html> <head> <title>onerror</title> <script language="javascript"> window.onerror = function() alert("出错啦!"); return true; //屏蔽系统事件 </script> </head> <body onload="nonExistent()"> </body> </html> 复制代码例子的效果是 弹出 出错啦 窗口 不弹出ie的错误窗口 按照网上找的答案 return true 的时候 原定的事件继续执行,所写的代码添加在原来功能的前面. 我认为原定的事件就是弹出ie的错误窗口,可是return true 时却不弹出ie的错误窗口. 而改为return false时却弹出ie的错误窗口. 大家来说说怎么回事.
参考技术A 看来JavaScript的事件机制你还不是很明白呢你这里事没有搞懂window.onerror的含义,所以,你认为return
false才是阻止事件的发生。不过实际上,你的想法是错误的。onerron就是在发生错误的时候捕获错误交给程序员来处理,你return
false就是代表不处理,那么自然会报错。
你可以把这段代码复制上去看看效果
window.onerror
=
function(msg,url,line)
if(onerror.num
++
<
onerror.max)
alert('发生错误:'
+
msg
+
'\n地址:'
+
url
+
'\n行数:'
+
line);
return
true;
onerror.num
=
0;
onerror.max
=
3;
你还可以看看JavaScript操作dom怎么阻止默认事件的,还有事件的传播等等,会对你有所帮助
javascript中的正确错误处理------------引用
JavaScript的事件驱动机制让JavaScript更加丰富,浏览器好比就是一个事件驱动的机器,错误也是一种事件。当一个错误发生时,一个事件就在某个点抛出。
解释起来就是,当发生错误时,JavaScript会去调用栈检查异常事件。

开始时,这个函数定义了一个空的对象foo,注意 bar() 没有在任何地方定义,我们用一个测试用例来看下它是如何引爆炸弹的。

这个单元测试是用 mocha 和 should.js 写的。mocha 是一个测试框架,should.js 是一个断言库。如果你熟悉它们后,你会感觉写起来很爽。测试一般使用 it(\'description\') 开始,然后在 should 中使用 ` pass/fail` 结束。好消息是测试用例可以在node端运行而不需要浏览器。我建议多关注这些测试,因为它们能帮助我们提升代码的质量。
正如所显示的, error() 定义了一个空的对象,然后尝试访问一个方法,因为 bar() 方法在对象中不存在而会抛出一个异常。使用JavaScript这种动态语言运行一定会出错。
错误的方式
对于一些错误的处理,我从按钮的而事件中抽离出异常处理的方式,下面是单元测试函数的代码:

这个处理函数接收一个 fn 回调函数作为输入,这个函数然后在处理器函数里面被调用,单元测试如下:
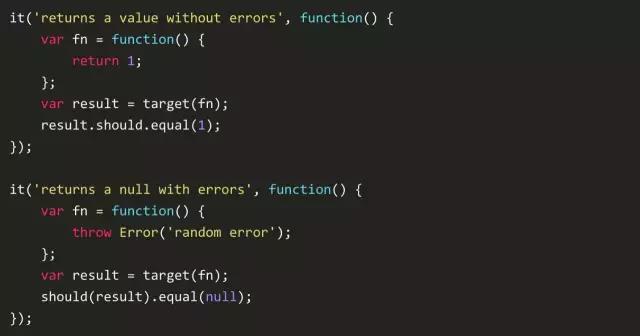
如你所见,这个糟糕的处理函数如果有地方出错就会返回null,回调函数 fn() 可以指向一个正确的方法或者一个异常,下面的点击处理函数会显示最终的处理结果。
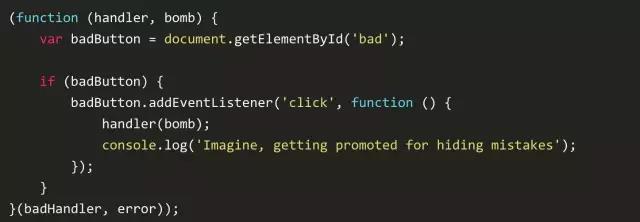
可恶的是,这里返回了一个null,当我想找哪里出了问题时整个人都蒙逼了。这种失败沉默的方式会影响用户体验和数据混乱。更令人崩溃的是,我花了几个小时来进行debugg,但却没有使用 try-catch,这个糟糕的处理函数吞没了错误并认为它没有问题,这样继续执行下去不会降低代码质量,但是隐藏的错误未来会让你花几个小时来debugg。在一个多层的深调用时,基本上不可能发现哪里出了问题。而在这些少数的地方使用 try-catch 是正确的。但是一旦进入错误处理函数,就比较糟糕了。
失败沉默策略会让你不容易发现错误所在,JavaScript提供了一个更优雅的方式来处理这些问题。
比较差的方式
继续,是时候说下一个稍微好点的方法了。我先跳过事件绑定到dom上的部分。这个函数处理和刚刚我们看到的没什么不同。所不同的是单元测试中它处理异常的方式。
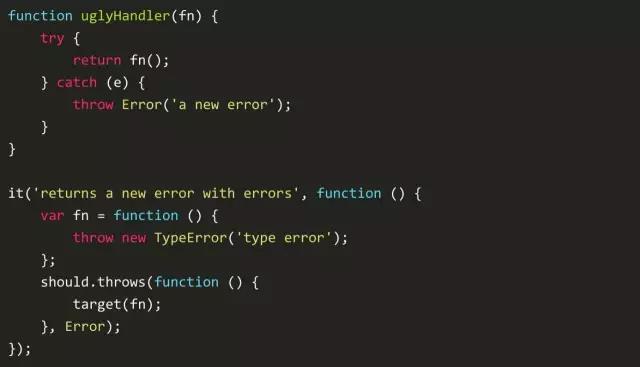
这里定义在原来的基础上改进了。这里异常事件在调用栈中进行冒泡,我喜欢的是现在错误现在会离开方便debugg的调用栈。在这个异常中,解释器会遍历整个栈寻找另一个错误处理函数。这样就可以有机会在调用栈的顶端处理这些错误。不幸的是,因为这个方法,我不知道错误是从哪个地方抛出来的。所以我又得反向遍历这个栈找到错误异常的源头。但至少我知道某个地方出错了,并能找到是哪个地方抛出的错误。
离开调用栈
所以,一个抛出异常处理的方法是直接调用栈的顶端使用 try-catch,就像:
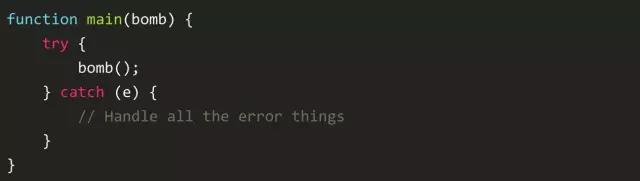
但是,记住我说的浏览器是事件驱动的。是的,JavaScript中的错误也不过是一个事件。解释器在当前的执行上下文中执行后释放。结果是,我们可以利用一个 onerror 的全局异常事件处理函数,它大概是这样的:
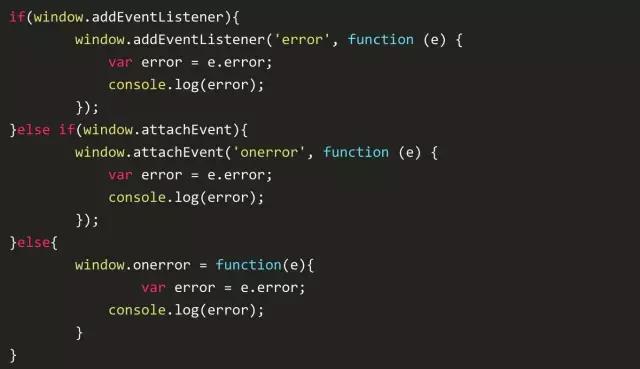
这个处理函数能捕获任何执行上下文中的错误异常。包括任何类型的任何错误。而且它能定位到代码中的错误处理。就像其它任何事件一样,你能捕获特定错误的具体信息。这样能使异常处理器只专注于一件事情,如果你允许这样做的话。这些处理函数也可以在任何时候注册,解释器会尽可能的遍历更多的处理函数,我们再也不用使用 try-catch 块这种带有瑕疵的debug方式了。尤其是在对待像JavaScript这类事件驱动机制的语言时,onerror的优势就更大了
现在我们可以使用全局处理函数来离开栈了,我们可以用来干什么呢。毕竟,调用栈还是存在的。
捕获栈信息
调用栈在定位问题时超级有用。好消息是,浏览器提供了这个信息。理所当然,查看错误异常中的栈属性不是标准的一部分,但是只在新的浏览器中可以使用。所以,你就可以这样来把错误日志发送给服务器了。
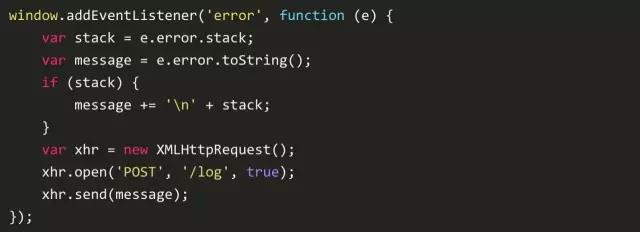
可能从代码样例来说不是很明显,但是上面的代码一定会出错。上面提到了,每个处理函数都只处理一个功能。我关心的是这些信息是怎样被服务器捕获的。如下:
些信息来自FireFox 46的开发版本,通过一个正确的错误处理函数,记录了出错的情况。这里没必要隐藏错误,我可以看到什么地方出现的什么错误。这样代码debugg就很爽了。这些信息也可以保存在持续化缓存中以便于以后分析。
调用栈对于debugg来说是很有用的,永远不要低估调用栈的力量。
异步处理
处理异步时,JavaScript的异步处理代码不在当前的指向上下文中,这意味着 try-catch 语句会有问题(不能捕获到异常):

单元测试的结果如下:
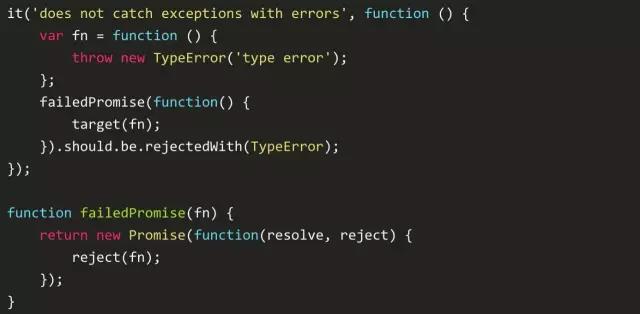
我必须用promise包含这个处理器来获取这个错误。注意的是,一个未被处理的异常发生时,尽管我将代码使用 try-catch 包含起来了,是的, try-catch 只能在单一的作用域内有效。在一个异常被抛出的同时,解释器就会从 try-catch 中离开,ajax也是一样的。所以有两种选择,一种是在异步调用里面捕获异常:

这种方法很有效,但是很多地方可以改进。首先,try-catch 块在这里用很混乱。实际上,之前是这么做的,但是有问题。另外,V8引擎不鼓励在函数中使用try-catch(V8是chrome和nodejs中的JavaScript引擎)。它们的建议是最外层写这些块。
所以我们该怎么办?我说过全局异常处理可以在任何执行上下文中执行,如果给window对象增加一个错误处理函数,就OK了。这样是不是既能处理捕获处理错误又能保持代码的优雅呢。全局的错误处理能让你的代码干净整洁。
下面是服务器收集到的错误日志,注意的是如果你使用同样的代码再不同浏览器上执行,你会看到收集到的日志也是不同的:
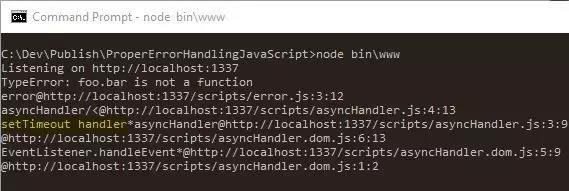
这个处理函数甚至告诉我们错误是从异步代码中抛出的吗,它告诉我们来至 setTimeout() 函数。
结论
总得来说,进行异常处理至少有两种方法。一个是失败沉默的方法,在错误发生时忽略错误不作为而不影响后面的继续执行。另一种是发生后迅速找到错误发生的地方。明显我们知道那种方法更具有优势。我的选择是:不要隐藏错误。没人会因为你代码中有问题而鄙视你,用户多试一次是可以接受的。代码距离完美是很远的,错误也是不可避免的,重要的是你发现错误后会怎么做。
译者注:文章浅显的分析了错误处理的方式和一些正反案例,其实处理错误的最终目的还是提供前端代码的质量,关于错误处理上报可以参考下 badjs 的思路,基于现代前端开发模块化的基础,使用全局onerror 和 try-catch 相结合的方式更能有效进行错误定位。
以上是关于javascript中的事件处理函数中的return false/true问题的主要内容,如果未能解决你的问题,请参考以下文章