Pytorch文本分类(imdb数据集),含DataLoader数据加载,最优模型保存
Posted CongHuang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch文本分类(imdb数据集),含DataLoader数据加载,最优模型保存相关的知识,希望对你有一定的参考价值。
用pytorch进行文本分类,数据集为keras内置的imdb影评数据(二分类),代码包含六个部分(详见代码)
代码地址为:pytorch-imdb-classification 欢迎star~
使用环境:
pytorch:1.1.0
cuda:10.0
gpu:RTX2070
(1)导入相应的库、定义常量以及加载imdb数据
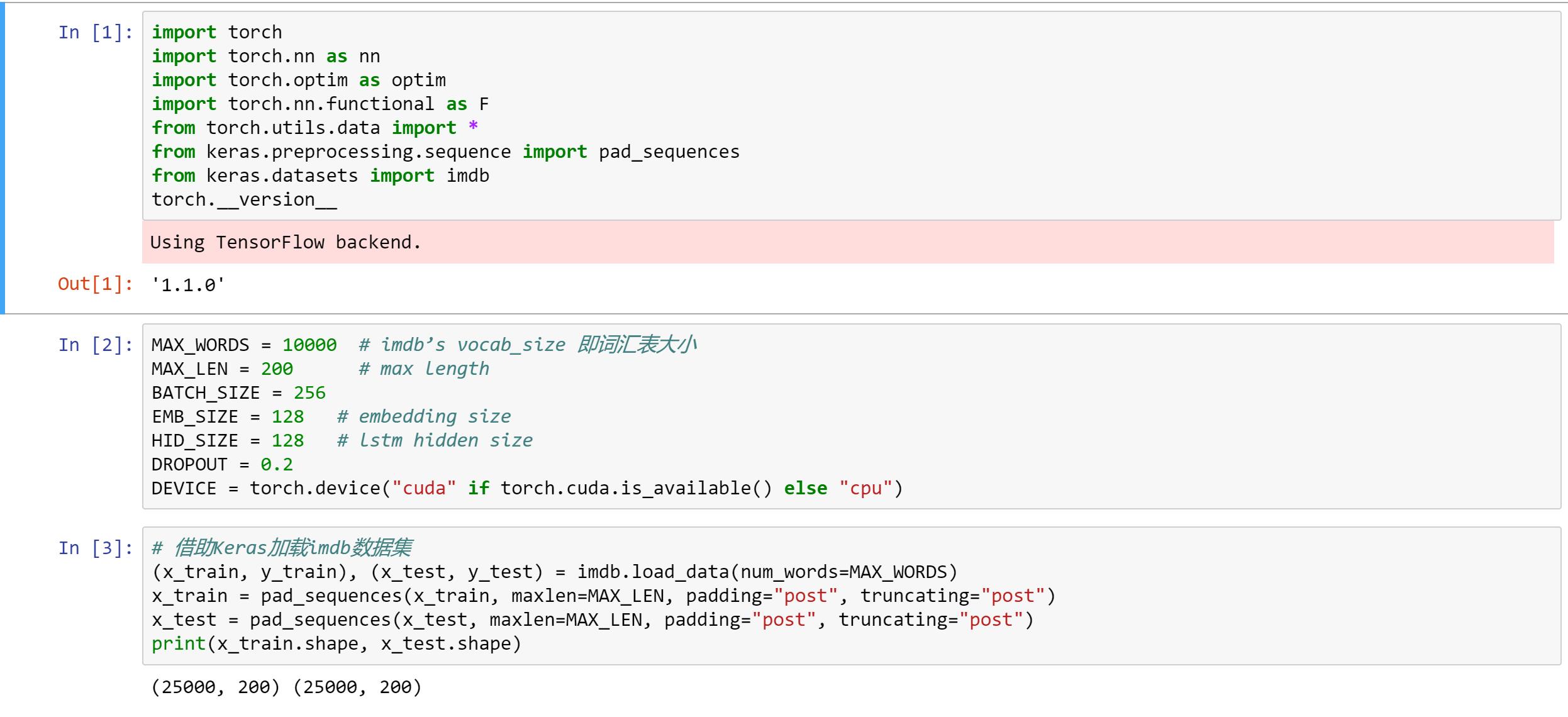
(2)使用DataLoader加载数据

(3)定义LSTM模型用于文本二分类

(4)定义训练函数和测试函数

(5)开始模型的训练(并保存最优模型权重),训练较快,2min左右
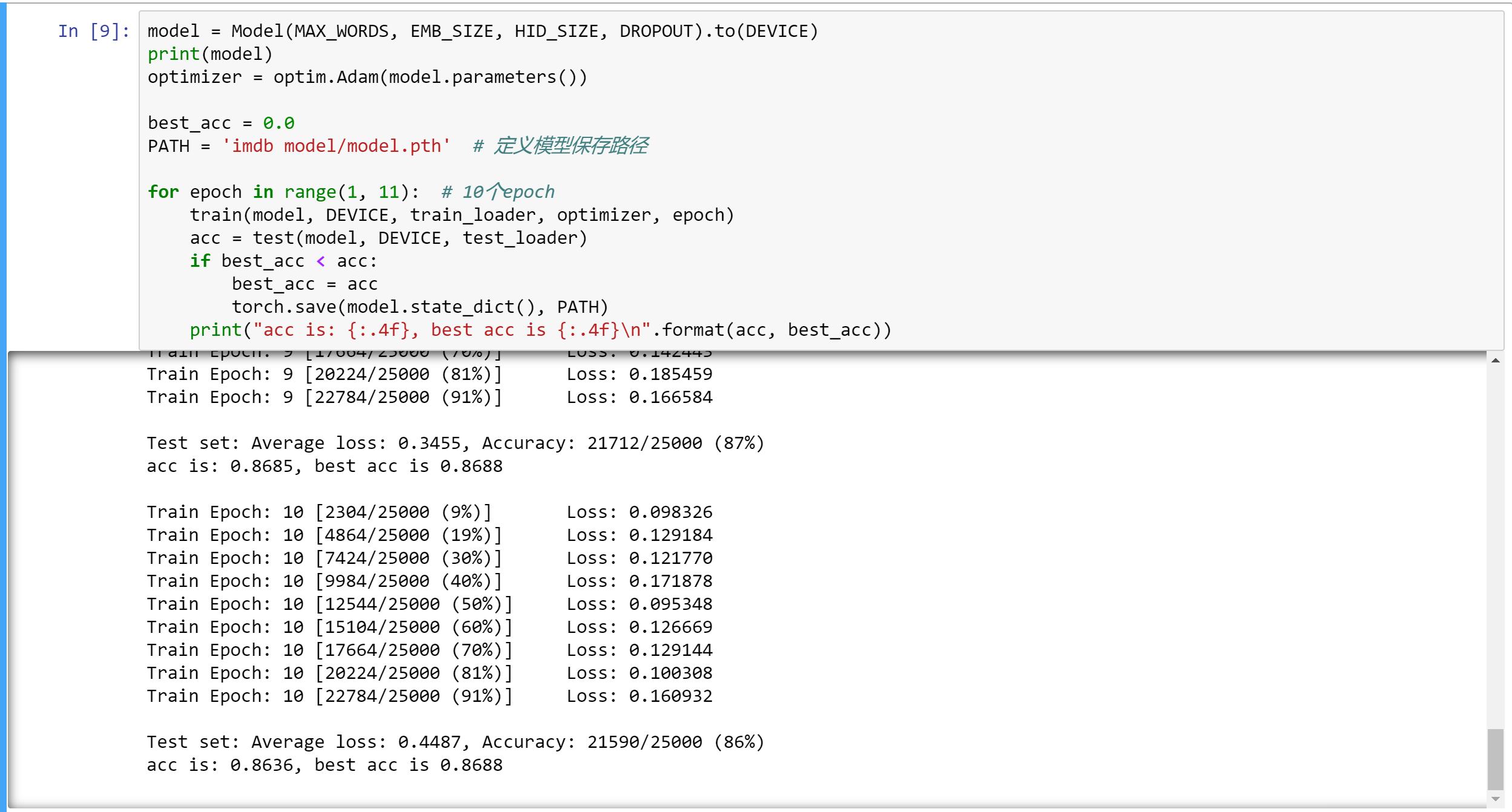
(6)加载模型权重并测试

以上是关于Pytorch文本分类(imdb数据集),含DataLoader数据加载,最优模型保存的主要内容,如果未能解决你的问题,请参考以下文章
PT之Transformer:基于PyTorch框架利用Transformer算法针对IMDB数据集实现情感分类的应用案例代码解析
PyTorch笔记 - IMDB数据集文本分类项目模型与训练
PyTorch笔记 - IMDB数据集文本分类项目模型与训练