Mysql 学习整理
Posted xuezhongdelang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql 学习整理相关的知识,希望对你有一定的参考价值。
1 创建数据库
1.1数据库基本结构
数据库:数据库是表的集合,带有相关的数据。
表:一个表是多个字段的集合。
字段:一个字段是一列数据,由字段名和记录组成
1.2创建数据库
create database 数据库名称;
例:创建名为test的测试数据库
create database test;
1.3查看创建好的数据库:
show create database 数据库名称;
例: 查看创建好的test数据库
show create database test;
1.4查看所有数据库列表:show databases;
1.5 使用数据库:
use 数据库名称;
例: 使用创建好的test数据库
use test;
1.6 删除数据库:
drop database 数据库名称;
例: 删除创建好的test数据库
drop database test;
2 创建数据表
– 数据库是由多个数据表构成的
– 每张数据表存储多个字段
– 每个字段由不同的字段名及记录构成,每个字段有自己的数据结构及约束条件
2.1 创建数据表:
create table 表名(…);
– 例:用SQL语句创建以下员工信息表
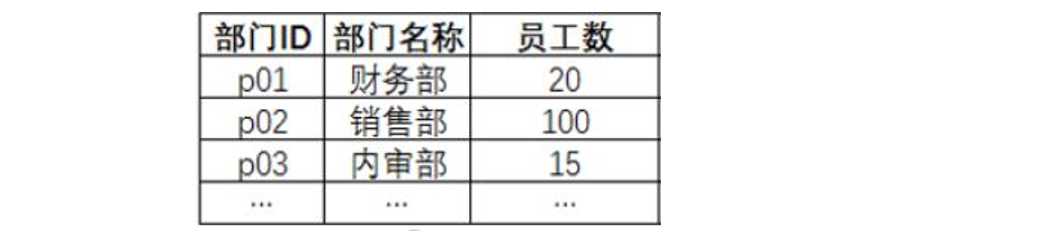 1. 使用test数据库: use test;
1. 使用test数据库: use test;
2. 创建员工信息表:
create table emp(
depid char(3),
depname varchar(20),
peoplecount int
);
3. 查看表是否创建成功: show tables;
4. 删除数据表: drop table emp;
3 数据类型
3.1数值类型:
– INT:有符号的和无符号的。有符号大小-2147483648~2147483647,无符号大 0~4294967295。宽度最多为11个数字- int(11)
– TINYINT:有符号的和无符号的。有符号大小-128~127,无符号大小为0~255。宽 度最多为4个数字- tinyint(4)
– SMALLINT:有符号的和无符号的。有符号大小-32768~32767,无符号大小为 0~65535。宽度最多为6个数字- smallint(6)
– MEDIUMINT:有符号的和无符号的。有符号大小-8388608~8388607,无符号大 小为0~16777215。宽度最多为9个数字- mediumint(9)
– BIGINT:有符号的和无符号的。宽度最多为20个数字- bigint(20)
– FLOAT(M,D):只能为有符号的。默认为(10,2)
– DOUBLE(M,D):只能为有符号的。默认为(16,4)
– DECIMAL(M,D):只能为有符号的。
3.2日期和时间类型 :
– DATE:YYYY-MM-DD格式,在1000-01-01和9999-12-31之间。例如: 1973-12-30
– DATETIME:YYYY-MM-DD HH:MM:SS格式,位于1000-01-01 00:00:00 和9999-12-31 23:59:59之间。例如:1973-12-30 15:30:00
– TIMESTAMP:称为时间戳,在1970-01-01 00:00:00和2037-12-31 23:59:59之间。
例如,1973年12月30日下午15:30,则在数据库中存储 为:19731230153000
– TIME: 以HH:MM:SS格式, -838:59:59~838:59:59
– YEAR(2|4): 以2位或4位格式存储年份值。如果是2位,1970~2069;如 果是4位,1901~2155。默认长度为4
3.3 字符串类型 :
– CHAR(M):固定长度字符串,长度为1-255。如果内容小于指定长度, 右边填充空格。如果不指定长度,默认为1
– VARCHAR(M): 可变长度字符串,长度为1-255。定义该类型时必须 指定长度
– BLOB 或TEXT:最大长度65535。存储二进制大数据,如图片。不能 指定长度。两者区别:BLOB 大小写敏感
– TINYBLOB 和TINYTEXT:最大长度255。不能指定长度。
– MEDIUMBLOB 或MEDIUMTEXT:最大长度16777215 字符
– LONGBLOB 或LONGTEXT:最大长度4294967295 字符
– ENUM:枚举。例如:ENUM(‘A’,’B’,’C’)。NULL 值也可
4 约束条件
– 约束是在表上强制执行的数据检验规则
– 用来保证创建的表的数据完整和正确
– mysql数据库常用约束条件
| 约束条件 | 说明 | 语法 |
| PRIMARY KEY | 主键约束 | 字段名 数据类型 PRIMARY KEY |
| NOT NULL | 非空约束 | 字段名 数据类型 NOT NULL |
| UNIQUE | 唯一约束 | 字段名 数据类型 UNIQUE |
| AUTO_INCREMENT | 自增字段 | 字段名 数据类型 AUTO_INCREMENT |
| DEFAULT | 默认值 | 字段名 数据类型 DEFAULT 默认值 |
4.1 主键约束:
保证表中每行记录都不重复 主键,又称为”主码”,是数据表中一列或多列的组合。
键约束要求主键列的数据必须是 唯一的,并且不允许为空。
使用主键,能够惟一地标识表中的一条记录,并且可以结合外键 来 定义不同数据表之间的关系,还可以加快数据库查询的速度。
主键分为两种类型:
-- 单字段主键:
create table emp(
depid char(3) primary key,
depname varchar(20),
peoplecount int
);
-- 多字段联合主键:
create table emp(
depid char(3),
depname varchar(20),
peoplecount int,
primary key(depname,depid)
);
4.2非空约束
指的是字段的值不能为空:
– 语法:字段名 字段类型 not null
create table emp(
depid char(3) primary key,
depname varchar(20) not null,
peoplecount int
);
4.3唯一性约束
要求该列的值必须是唯一的:
– 允许为空,但只能出现一个空值;
– 一个表中可以有多个字段声明为唯一的;
– 唯一约束确保数据表的一列或几列不出现重复值;
– 语法:字段名 数据类型 unique
create table emp(
depid char(3) primary key,
depname varchar(20) not null,
peoplecount int unique
);
4.4默认约束
指定某个字段的默认值:
– 如果新插入一条记录时没有为默认约束字段赋值,那么系统就会自动为 这个字段赋值为默认约束设定的值
– 语法: 字段名 数据类型 default 默认值
create table emp(
depid char(3) primary key,
depname varchar(20) not null default ‘-‘,
peoplecount int unique
);
4.5自增字段
一个表只能有一个自增字段,自增字段必须为主键的一部分。默认情况下 从1开始自增
例: 创建含各种约束条件的数据表
CREATE TABLE example(
id INT PRIMARY KEY AUTO_INCREMENT, -- 创建整数型自增主键
name VARCHAR(4) NOT NULL, -- 创建非空字符串字段
math INT DEFAULT 0, -- 创建默认值为0的整数型字段
minmax FLOAT UNIQUE – 创建唯一约束小数型字段
);
5 导入数据
5.1 用insert into语句为表插入数据
语法: insert into 表名(字段1,字段2,…) values ……
-- 插入数据
insert into fruits(f_id,s_id,f_name,f_price)
values(‘a1‘,101,‘apple‘,5.2),
(‘b1‘,101,‘blackberry‘,10.2),
(‘bs1‘,102,‘orange‘,11.2),
(‘bs2‘,105,‘melon‘,8.2),
(‘t1‘,102,‘banana‘,10.3),
(‘t2‘,102,‘grape‘,5.3);
5.2 导入外部数据
导入外部文本文件:
-- 为Monthly_Indicator表导入外部txt文件
load data local infile ‘文件路径.txt’ -- 路径不能有中文,复制的路径的的""应改为"\\"或‘‘/‘‘
into table Monthly_Indicator -- 导入表..中
fields terminated by ‘ ‘ -- 字段间的分隔符: ‘ ‘用空格分隔的 , ‘,‘用逗号分隔的
ignore 1 lines; -- 忽略第一行。如果源表中第一行为表头行,则忽略第一行
5.3 检查表数据
对导入表中的数据一般从导入内容、导入数据总行数以及表结构三方面进行检查
-- 检查导入内容 Select * from Monthly_Indicator;
-- 检查导入数据总行数 Select count(*) from Monthly_Indicator;
-- 检查表结构 Desc Monthly_Indicator;
6 修改数据表 alter table...
修改表指的是修改数据库中已经存在的数据表的结构:
– MySQL使用alter table语句修改数据表结构,
包括: 修改表名,修改字段数据类型或 字段名,增加和删除字段,修改字段的排列位置等
– 例:将数据表emp改名为empdep alter table emp rename empdep;
– 例:将数据表empdep中depname字段的数据类型由varchar(20)修改成varchar(30) alter table empdep modify depname varchar(30);
– 例:将数据表empdep中depname字段的字段名改为dep alter table empdep change depname dep varchar(30);
– 例:将数据表empdep中dep字段的字段名改回为depname,并将该字段数 据类型该回为varchar(20)
alter table empdep change dep depname varchar(20);
– 例:为数据表empdep添加新字段maname,新字段数据类型为varchar(10), 约束条件为非空
alter table empdep add maname varchar(10) not null;
– 例:将数据表empdep中maname字段的排列顺序改为第一位 alter table empdep modify maname varchar(10) first;
– 例:将数据表emp中maname字段的排列顺序改到depid字段之后 alter table empdep modify maname varchar(10) after depid;
– 例:删除maname字段 alter table empdep drop maname;
7 修改记录
update…set:为字段赋值,语法为update 表名 set 字段名 = 值;
例: 使用concat函数在f_name字段值前添加‘fruit_’信息
update fruits set f_name = concat(‘fruit_‘,f_name);
delete: 删除数据表中的数据,
语法为DELETE FROM 表名 [WHERE Clause], 如果省略where的话则删除表中所有数据记录
例: 删除f_id为‘b5‘的数据记录
delete from fruits where f_id = ‘b5‘;
8 SELECT语句
8.1SELECT语句的操作符
- 算术操作符 +(加号)、-(减号)、*(乘号)和 /(除号)。
- 比较操作符 =(等于)、>(大于)、<(小于)、<=(小于等于)、>=(大于等于)、!= 或<> (不等于)、!>(不大于)和 !<(不小于),共9种操作符。
- 逻辑操作符
8.2 聚合类函数
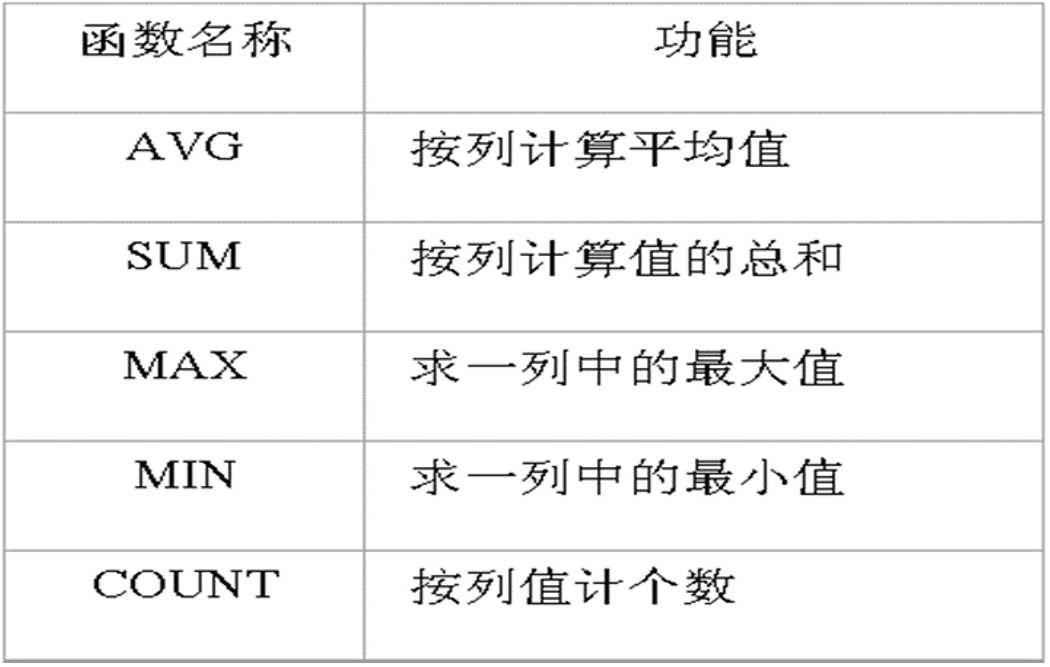
8.3SQL的数据查询功能
SELECT语句的语法
SELECT〈目标列组〉
FROM〈数据源〉
[WHERE〈元组选择条件〉]
[GROUP BY〈分列组〉[HAVING 〈组选择条件〉]]
[ORDER BY〈排序列1〉〈排序要求1〉 [,…n]];
-- 对大气质量表进行有选择的查询
select city_name, avg(pm25), avg(pm10) from Monthly_Indicator
where pm25 > 50
group by city_name, month_key having city_name <> ‘北京’
order by avg(pm25) desc;
8.4 联接查询
联接查询,是将两个或多个表横向联接,再进行查询,一般为1表出维度,多表出值
按联接方向可分为: 左联接,右联接,内联接
8.4.1 内连接: 按照连接条件合并两个表,返回满足条件的行。
SELECT <select_list> FROM A INNER
JOIN B ON A.Key = B.Key;
8.4.2左连接: 结果中除了包括满足连接条件的行外,还包括左表的所有行
SELECT <select_list> FROM A
LEFT JOIN B ON A.Key = B.Key;
8.4.3 右连接: 结果中除了包括满足连接条件的行外,还包括右表的所有行
SELECT <select_list> FROM A
RIGHT JOIN B ON A.Key = B.Key;
8.5 表格合并与联合查询
表格合并可理解为在前表基础上增加记录,即如果字段名相同,把后表的记录增加到前表记录中,如果字段名不同,则自动增加字段名,如果前表中无后表的字段名,再自动为空值。
union: 用于合并两个或多个 SELECT 语句的结果集,并消去表中任何重复行。
例: 用union合并t1与t2表
select t1.* from t1
union
select t2.* from t2;
union all:用于合并两个或多个 SELECT 语句的结果集,保留重复行。
例: 用union all合并t1与t2表
select t1.* from t1
union all
select t2.* from t2;
8.6查询操作符列表
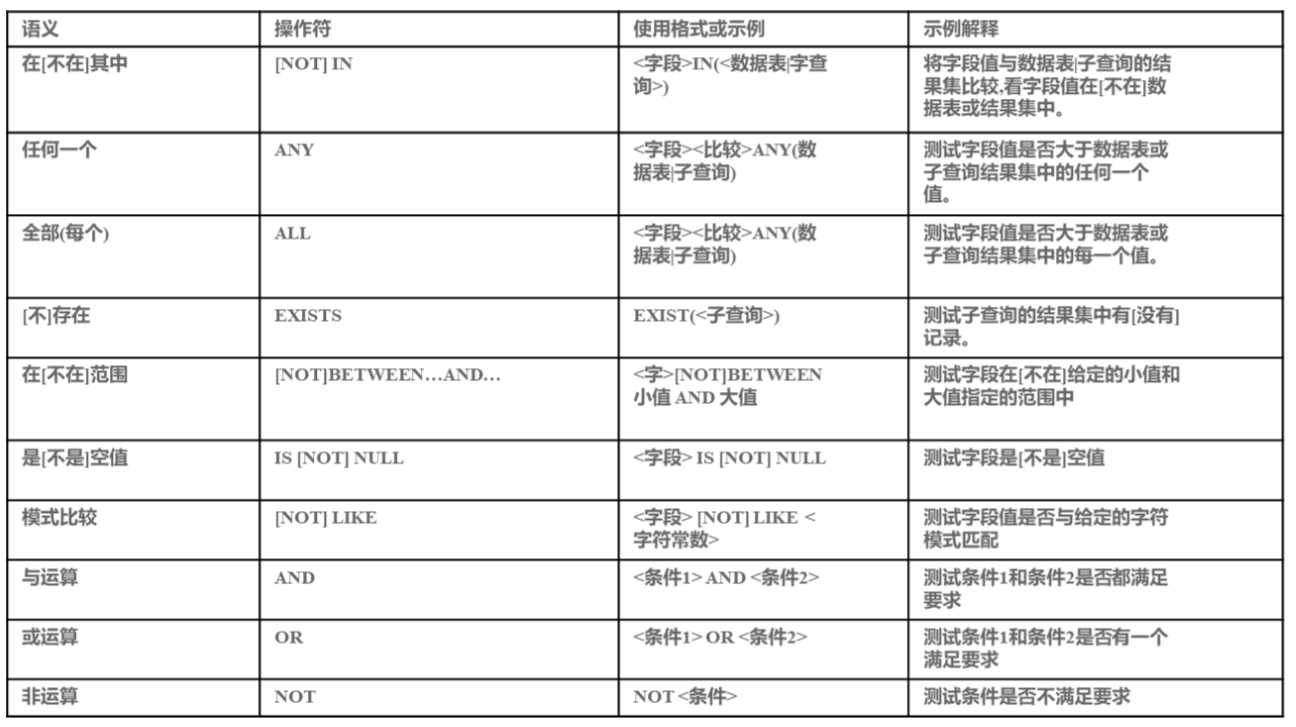
distinct操作符
distinct: 用来消除重复记录。
例: 查询fruits表中所有不重复的s_id
select distinct s_id from fruits;
8.7 子查询
子查询:写在()中,把内层查询结果当做外层查询参照的数据表来用
例: 用in操作符与子查询语句来查询所有f_id对应的f_price在10元到20元之间的水果记录
select * from fruits where f_id in
(select f_id from fruits where f_price between 10 and 20);
例: 用any操作符与子查询语句来查询所有f_id对应的f_price在10元到20元之间的水果记录
select * from fruits where f_id = any
(select f_id from fruits where f_price between 10 and 20);
例: 用all操作符与子查询语句来查询所有f_price大于20元的水果记录
select * from fruits where f_price > all
(select f_price from fruits where f_price < =20);
例: 用exists操作符与子查询语句来查询是否存在f_price大于30元的水果记录
select * from fruits where exists
(select * from fruits where f_price > 30);
8.8 as重命名与limit限制查询结果行数
as:可以将表名重新命名为别的名称使用,只在查询中有效
例: 用as将fruits表名重命名为f后使用
select f.* from fruits as f;
limit:查询后只显示limit指定数字的行数结果
例: 显示f_price金额最大的前三名水果记录
select * from fruits
order by f_price desc
limit 3;
9 常用函数
9.1常用的数学函数:主要用于处理数字值
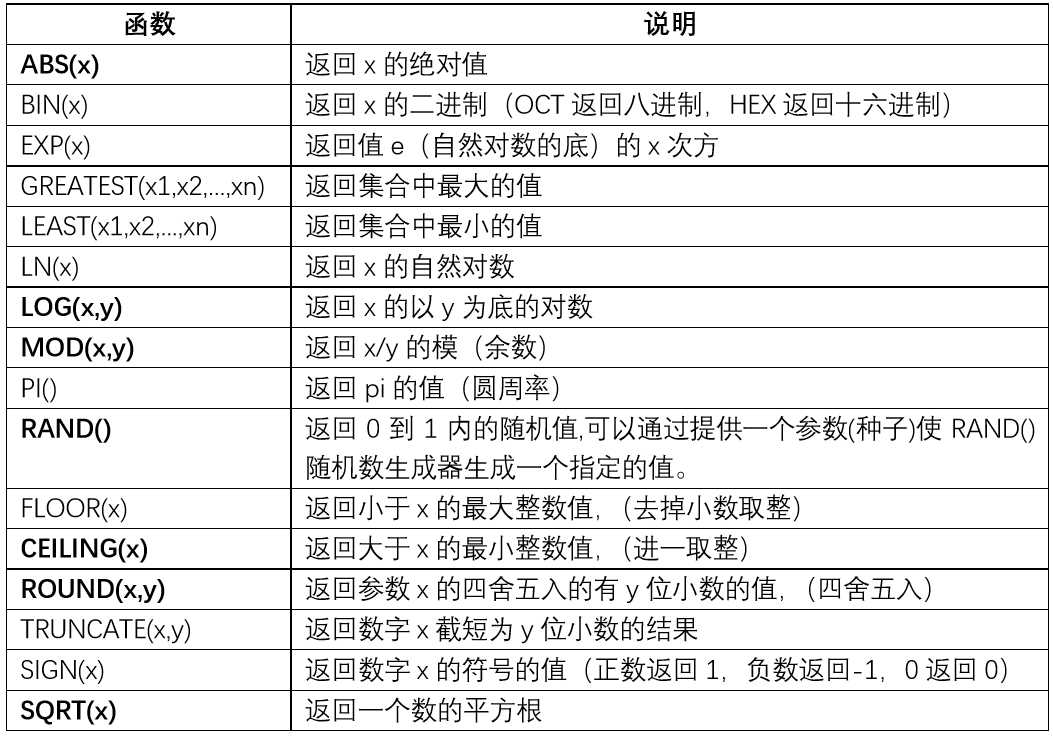
9.2常用的字符串函数:主要用于处理字符串值
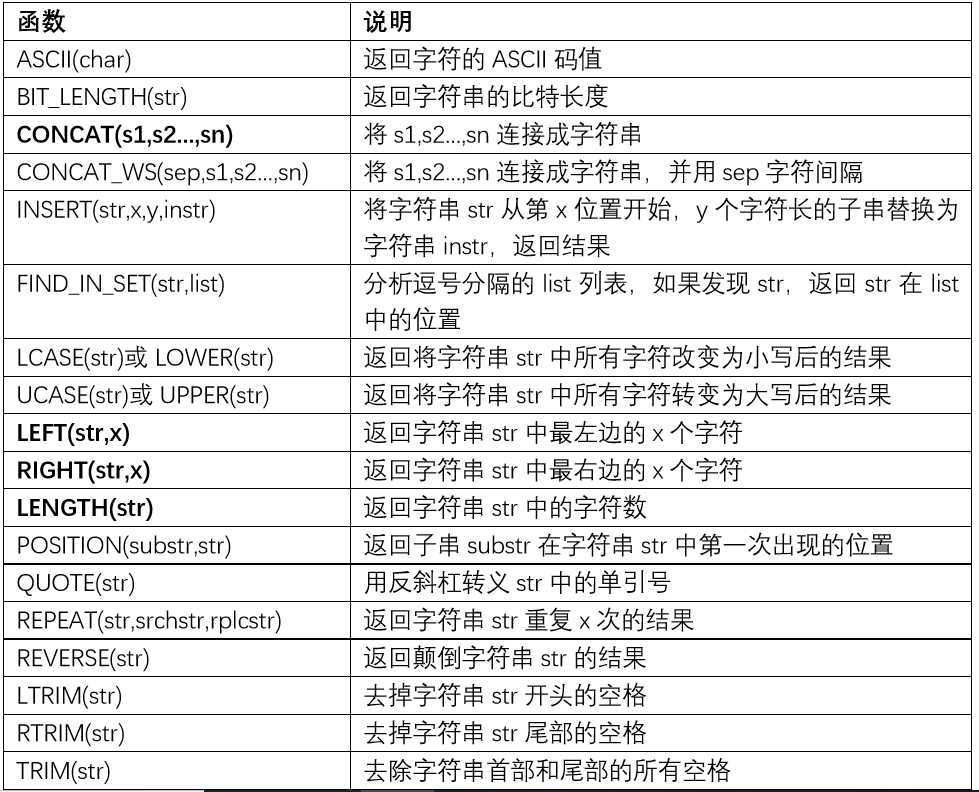
9.3日期及时间函数:用来处理日期时间型数据
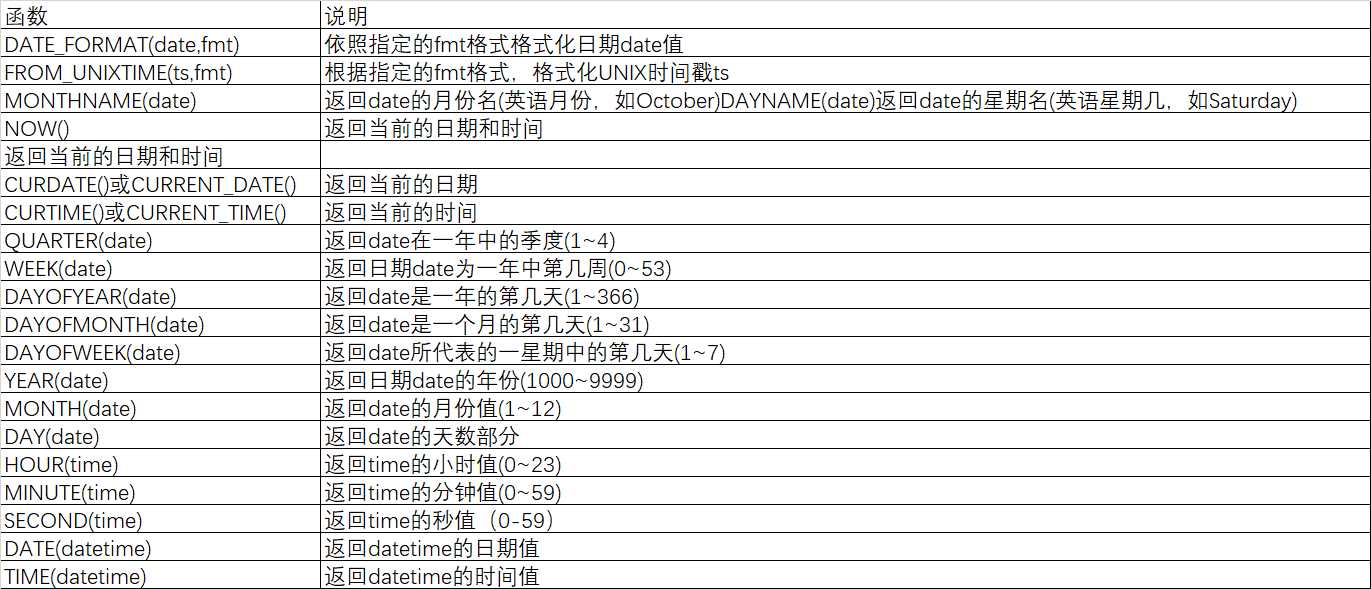
9.4其他函数:除上述函数之外的一些常用函数

※GROUP_CONCAT()函数:常与关键字 GROUP BY 一起使用,能够将分组后指定的字段值都显示出来。
例: 使用group_concat函数查询不同s_id下对应的所有f_name信息
SELECT s_id, GROUP_CONCAT(f_name) FROM fruits
GROUP BY s_id;
CAST函数语法规则是:Cast(字段名 as 转换的类型 ),其中类型可以为:
CHAR[(N)] 字符型
DATE 日期型
DATETIME 日期和时间型
DECIMAL 小数型
SIGNED 整数型
TIME 时间型
将fruits表的f_price 转换为 1位小数
select cast(f_price as decimal(10,1)) as f_price from fruits;
以上是关于Mysql 学习整理的主要内容,如果未能解决你的问题,请参考以下文章