mysql> delete from `zhangchao` where x=\'NULL\';
Query OK, 0 rows affected (0.00 sec) mysql> delete from `zhangchao` where x=NULL; Query OK, 0 rows affected (0.00 sec) mysql> select * from zhangchao; +------+-------+ | x | y | +------+-------+ | xxx | yyy | | NULL | NULL | | xxx | james | | xxx | lucy | | xxx | alex | +------+-------+ 5 rows in set (0.00 sec) mysql> delete from `zhangchao` where x is null; Query OK, 1 row affected (0.00 sec) mysql> select * from zhangchao; +------+-------+ | x | y | +------+-------+ | xxx | yyy | | xxx | james | | xxx | lucy | | xxx | alex | +------+-------+ 4 rows in set (0.00 sec) mysql>
需要使用is null来进行判断。
SELECT × FROM mytable ORDER BY ABS(type) ASC , addtime DESCTYPE字段类型为 TINYINT 长度为1
取值范围为 0,1,-1
0 未审核,1审核通过,-1被驳回;
目的:实现未审核的数据在列表最上面,根据最近时间再次排序
ABS(X)的用法说明
返回X 的绝对值。
[SQL]as的是否可以省略的问题
数据库中as主要作用是起别名,常规来说都可以省略,但是为了增加可读性,不建议省略。
在MySQL中,写SQL语句的时候 ,可能会遇到You can\'t specify target table \'表名\' for update in FROM clause这样的错误,它的意思是说,不能先select出同一表中的某些值,再update这个表(在同一语句中),即不能依据某字段值做判断再来更新某字段的值。
1、数据准备
product表数据如下:
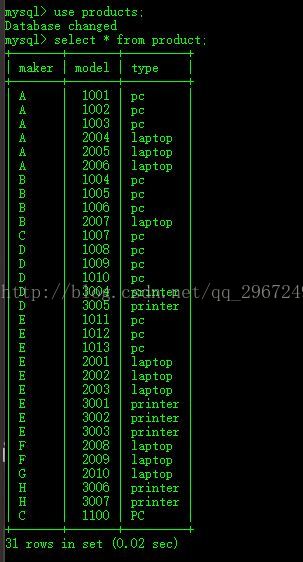
laptop表数据如下:
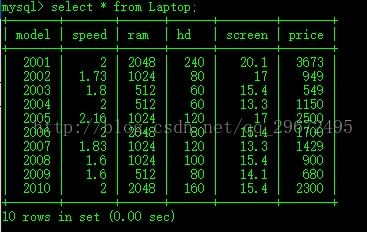
2、要求:#删除所有不生产打印机厂商生产的笔记本电脑
第一步:对aptop表进行操作

操作没有问题,按照本思路对product表进行操作
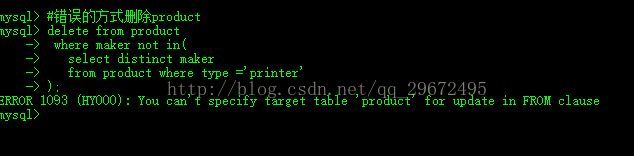
产生You can\'t specify target table \'表名\' for update in FROM clause错误
3、问题解决
将SELECT出的结果再通过中间表SELECT一遍,这样就规避了错误。
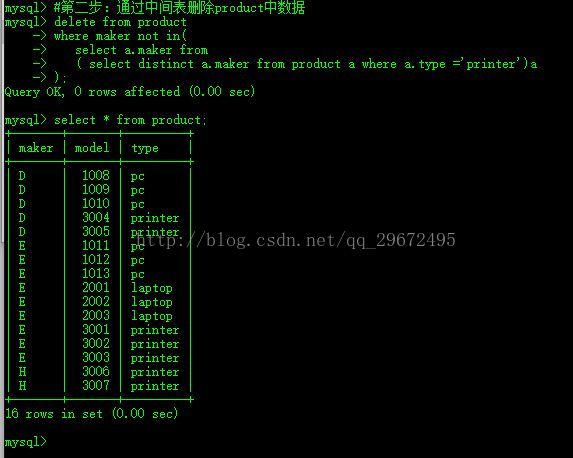
需要注意的是,这个问题只出现于MySQL,MSSQL和Oracle不会出现此问题。
MYSQL中replace into的用法
新建一个test表,三个字段,id,title,uid, id是自增的主键,uid是唯一索引;
插入两条数据
insert into test(title,uid) VALUES (\'123465\',\'1001\'); insert into test(title,uid) VALUES (\'123465\',\'1002\');
执行单条插入数据可以看到,执行结果如下:
[SQL]insert into test(title,uid) VALUES (\'123465\',\'1001\'); 受影响的行: 1 时间: 0.175s
使用 replace into插入数据时:
REPLACE INTO test(title,uid) VALUES (\'1234657\',\'1003\');
执行结果:
[SQL]REPLACE INTO test(title,uid) VALUES (\'1234657\',\'1003\');
受影响的行: 1
时间: 0.035s
当前数据库test表所有数据如下:
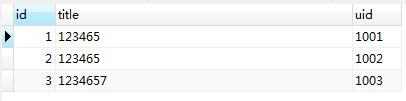
当uid存在时,使用replace into 语句
REPLACE INTO test(title,uid) VALUES (\'1234657\',\'1001\'); [SQL]REPLACE INTO test(title,uid) VALUES (\'1234657\',\'1001\'); 受影响的行: 2 时间: 0.140s

replace into t(id, update_time) values(1, now());
或
replace into t(id, update_time) select 1, now();
replace into 跟 insert 功能类似,不同点在于:replace into 首先尝试插入数据到表中, 1. 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。 2. 否则,直接插入新数据。
要注意的是:插入数据的表必须有主键或者是唯一索引!否则的话,replace into 会直接插入数据,这将导致表中出现重复的数据。
MySQL replace into 有三种形式:
1. replace into tbl_name(col_name, ...) values(...)
2. replace into tbl_name(col_name, ...) select ...
3. replace into tbl_name set col_name=value, ...
第一种形式类似于insert into的用法,
第二种replace select的用法也类似于insert select,这种用法并不一定要求列名匹配,事实上,MYSQL甚至不关心select返回的列名,它需要的是列的位置。例如,replace into tb1( name, title, mood) select rname, rtitle, rmood from tb2;?这个例子使用replace into从?tb2中将所有数据导入tb1中。
第三种replace set用法类似于update set用法,使用一个例如“SET col_name = col_name + 1”的赋值,则对位于右侧的列名称的引用会被作为DEFAULT(col_name)处理。因此,该赋值相当于SET col_name = DEFAULT(col_name) + 1。
前两种形式用的多些。其中 “into” 关键字可以省略,不过最好加上 “into”,这样意思更加直观。另外,对于那些没有给予值的列,MySQL 将自动为这些列赋上默认值。
查询某个数据库中某个表的所有列名
SELECT COLUMN_NAME FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = \'db_name\' AND TABLE_NAME = \'tb_name\';
查询某个数据库中某个表的所有列名,并用逗号连接
SELECT GROUP_CONCAT(COLUMN_NAME SEPARATOR ",") FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = \'db_name\' AND TABLE_NAME = \'tb_name\';
注意:只需要替换db_name(数据库名)和tb_name(表名)
sql语句中的like语句中%和*的区别
sql中的通配符%才代表任意字符,*在sql中没有通配符的意思,虽然在像DOS环境之类下是代表任意字符的意思
select * from sysuser a where a.login_name like \'sys*\';
等于
select * from sysuser a where a.login_name = \'sys*\';
where name like “张%”;
SQL中的子查询
z子查询就是将一个查询(子查询)的结果作为另一个查询(主查询)的数据来源或判断条件的查询。常见的子查询有WHERE子查询,HAVING子查询,FROM子查询,SELECT子查询,EXISTS子查询,子查询要使用小括号();
WHERE子查询
在WHERE子句中进行使用查询
SELECT *
FROM EMP
WHERE SAL < (SELECT AVG(SAL) FROM EMP);- 查询薪资比平均薪资低的员工信息
HAVING子查询
HAVING子句是对分组统计函数进行过滤的子句,也可以在HAVING子句中使用子查询
SELECT JOB,AVG(SAL)
FROM EMP
GROUP BY JOB
HAVING AVG(SAL) = (SELECT MAX(AVG(SAL)) FROM EMP GROUP BY JOB);- 查询平均薪资最高的职位及其平均薪资
FROM子查询
FROM子查询就是将一个查询结构(一般多行多列)作为主查询的数据源
SELECT JOB,AVG(SAL)
FROM (SELECT JOB,AVG(SAL) AS AVGSAL FROM EMP GROUP BY JOB)TEMP
WHERE TEMP.AVGSAL>2000;- 查询平均薪资高于2000的职位以及该职位的平均薪资
SELECT子查询
SELECT子查询在SELECT子句中使用查询的结果(一般会和dual空表一起使用)
SELECT (SELECT COUNT(*) FROM EMP WHERE JOB = \'SALESMAN\')/(SELECT COUNT(*) FROM EMP)
FROM DUAL;- 职位是SALESMAN的员工占总员工的比例
EXISIT子查询
将主查询的数据带到子查询中验证,如果成功则返回true,否则发水false。主查询接收true是就会显示这条数据,flase就不会显示。
SELECT *
FROM EMP E
WHERE EXISIT (
SELECT *
FROM DEPT D
WHERE E.DEPTNO = D.DEPTNO);- 查询有部门的员工信息
查询薪资排名的员工信息(面试)
SELECT *
FROM EMP
WHERE SAL = (SELECT MIN(SAL)
FROM (SELECT ROWNUM,SAL
FROM (SELECT SAL FROM EMP GROUP BY SAL ORDER BY SAL DESC)
WHERE ROWNUM<=n));- 查询薪资排名第n个员工的信息(包括并列排名)
思路:
1.先按薪资降序分组
2.再取前n名薪资中最低的薪资,即第n名的薪资。
3.最后在原表中找出薪资与最低薪资相同的员工信息。