SparkSql运行原理详细解析
Posted db_record
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkSql运行原理详细解析相关的知识,希望对你有一定的参考价值。
传统关系型数据库中 ,最基本的sql查询语句由projecttion (field a,field b,field c) , datasource (table A) 和 fieter (field a >10) 三部分组成。 分别对应了sql查询过程中的result , datasource和operation ,也就是按照result ——> datasource ——> operation 的顺序来描述,如下图所示:
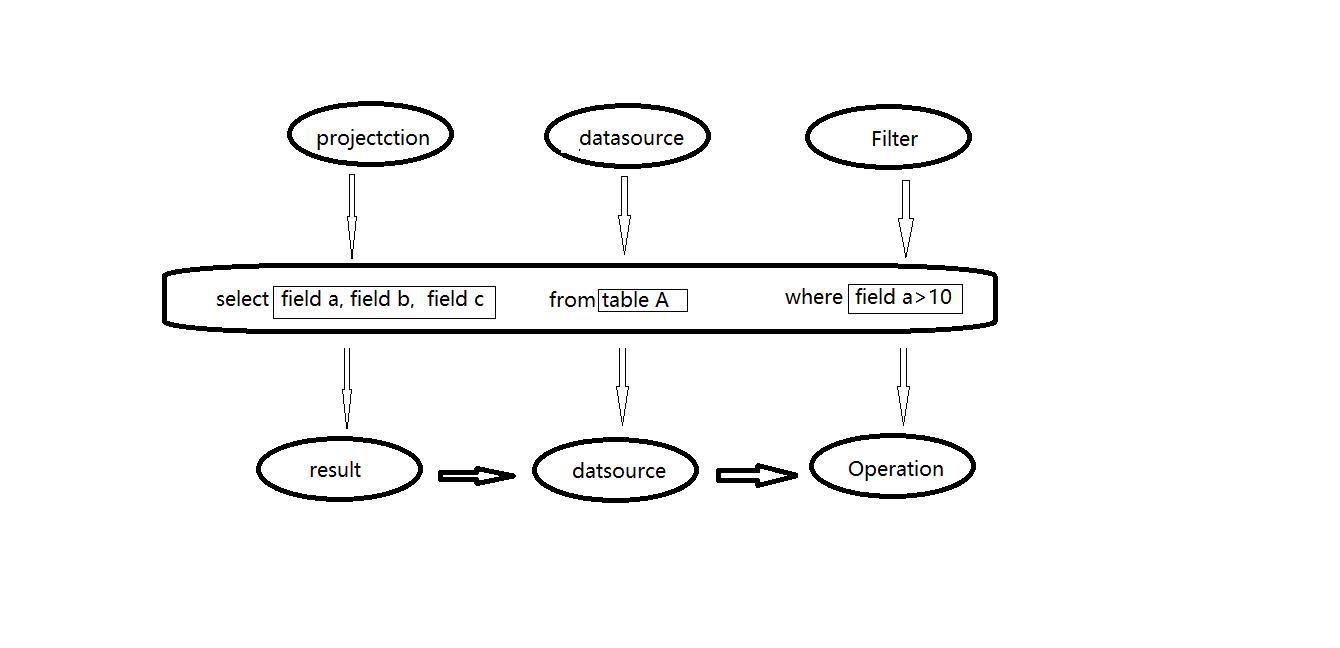
但是sql实际执行过程是按照operation——> datasource——>result 的顺序来执行的这与sql语法正好相反,具体的执行过程如下:
1 . 语法和词法解析:对写入的sql语句进行词法和语法解析(parse),分辨出sql语句在哪些是关键词(如select ,from 和where),哪些是表达式,哪些是projection ,哪些是datasource等,判断SQL语法是否规范,并形成逻辑计划。
2 .绑定:将SQL语句和数据库的数据字典(列,表,视图等)进行绑定(bind),如果相关的projection和datasource等都在的话,则表示这个SQL语句是可以执行的。
3 .优化(optimize):一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划。
4 .执行(execute):执行前面的步骤获取最有执行计划,返回查询的数据集。
SparkSQL的运行架构:
Spark SQL对SQL语句的处理和关系型数据库采用了类似的方法,sparksql先会将SQL语句进行解析(parse)形成一个Tree,然后使用Rule对Tree进行绑定,优化等处理过程,通过模式匹配对不同类型的节点采用不同操作。而sparksql的查询优化器是catalyst,它负责处理查询语句的解析,绑定,优化和生成物理执行计划等过程,catalyst是sparksql最核心部分。
Spark SQL由core,catalyst,hive和hive-thriftserver4个部分组成。
- core: 负责处理数据的输入/输出,从不同的数据源获取数据(如RDD,Parquet文件和JSON文件等),然后将结果查询结果输出成Data Frame。
- catalyst: 负责处理查询语句的整个处理过程,包括解析,绑定,优化,生成物理计划等。
- hive: 负责对hive数据的处理。
- hive-thriftserver:提供client和JDBC/ODBC等接口。
运行原理原理分析:
1.使用SesstionCatalog保存元数据
在解析sql语句前需要初始化sqlcontext,它定义sparksql上下文,在输入sql语句前会加载SesstionCatalog,初始化sqlcontext时会把元数据保存在SesstionCatalog中,包括库名,表名,字段,字段类型等。这些数据将在解析未绑定的逻辑计划上使用。
2.使用Antlr生成未绑定的逻辑计划
Spark2.0版本起使用Antlr进行词法和语法解析,Antlr会构建一个按照关键字生成的语法树,也就是生成的未绑定的逻辑计划。
3.使用Analyzer绑定逻辑计划
在这个阶段Analyzer 使用Analysis Rules,结合SessionCatalog元数据,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划。
4.使用Optimizer优化逻辑计划
Opetimize(优化器)的实现和处理方式同Analyzer类似,在该类中定义一系列Rule,利用这些Rule对逻辑计划和Expression进行迭代处理,达到树的节点的合并和优化。
5.使用SparkPlanner生成可执行计划的物理计划
SparkPlanner使用Planning Strategies对优化的逻辑计划进行转化,生成可执行的物理计划。
6.使用QueryExecution执行物理计划
以上是关于SparkSql运行原理详细解析的主要内容,如果未能解决你的问题,请参考以下文章