Oracle中如何删除重复数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle中如何删除重复数据相关的知识,希望对你有一定的参考价值。
参考技术A我们可能会出现这种情况 某个表原来设计不周全 导致表里面的数据数据重复 那么 如何对重复的数据进行删除呢?
重复的数据可能有这样两种情况 第一种时表中只有某些字段一样 第二种是两行记录完全一样
一 对于部分字段重复数据的删除
先来谈谈如何查询重复的数据吧
下面语句可以查询出那些数据是重复的
select 字段 字段 count(*) from 表名 group by 字段 字段 having count(*) >
将上面的>号改为=号就可以查询出没有重复的数据了
想要删除这些重复的数据 可以使用下面语句进行删除
delete from 表名 a where 字段 字段 in
(select 字段 字段 count(*) from 表名 group by 字段 字段 having count(*) > )
上面的语句非常简单 就是将查询到的数据删除掉 不过这种删除执行的效率非常低 对于大数据量来说 可能会将数据库吊死 所以我建议先将查询到的重复的数据插入到一个临时表中 然后对进行删除 这样 执行删除的时候就不用再进行一次查询了 如下
CREATE TABLE 临时表 AS
(select 字段 字段 count(*) from 表名 group by 字段 字段 having count(*) > )
上面这句话就是建立了临时表 并将查询到的数据插入其中
下面就可以进行这样的删除操作了
delete from 表名 a where 字段 字段 in (select 字段 字段 from 临时表);
这种先建临时表再进行删除的操作要比直接用一条语句进行删除要高效得多
这个时候 大家可能会跳出来说 什么?你叫我们执行这种语句 那不是把所有重复的全都删除吗?而我们想保留重复数据中最新的一条记录啊!大家不要急 下面我就讲一下如何进行这种操作
在oracle中 有个隐藏了自动rowid 里面给每条记录一个唯一的rowid 我们如果想保留最新的一条记录
我们就可以利用这个字段 保留重复数据中rowid最大的一条记录就可以了
下面是查询重复数据的一个例子
select a rowid a * from 表名 a
where a rowid !=
(
select max(b rowid) from 表名 b
where a 字段 = b 字段 and
a 字段 = b 字段
)
下面我就来讲解一下 上面括号中的语句是查询出重复数据中rowid最大的一条记录
而外面就是查询出除了rowid最大之外的其他重复的数据了
由此 我们要删除重复数据 只保留最新的一条数据 就可以这样写了
delete from 表名 a
where a rowid !=
(
select max(b rowid) from 表名 b
where a 字段 = b 字段 and
a 字段 = b 字段
)
随便说一下 上面语句的执行效率是很低的 可以考虑建立临时表 讲需要判断重复的字段 rowid插入临时表中 然后删除的时候在进行比较
create table 临时表 as
select a 字段 a 字段 MAX(a ROWID) dataid from 正式表 a GROUP BY a 字段 a 字段 ;
delete from 表名 a
where a rowid !=
(
select b dataid from 临时表 b
where a 字段 = b 字段 and
a 字段 = b 字段
);
mit;
二 对于完全重复记录的删除
对于表中两行记录完全一样的情况 可以用下面语句获取到去掉重复数据后的记录
select distinct * from 表名
可以将查询的记录放到临时表中 然后再将原来的表记录删除 最后将临时表的数据导回原来的表中 如下
CREATE TABLE 临时表 AS (select distinct * from 表名);
drop table 正式表;
insert into 正式表 (select * from 临时表);
drop table 临时表;
如果想删除一个表的重复数据 可以先建一个临时表 将去掉重复数据后的数据导入到临时表 然后在从
临时表将数据导入正式表中 如下
INSERT INTO t_table_bak
lishixinzhi/Article/program/Oracle/201311/17477
oracle如何实现去重和分页
一:oracle实现去重:
user数据表:

分两步:1.查询重复数据 2.删除重复数据
1.查询重复数据:
在oracle中实现查询重复数据,可以借助于rowid这个伪列。oracle中每个表物理上都存在一个rowid的列,这个列
是每行数据在oracle中唯一标识,每个表的主键可以保证数据在本表中不重复,rowid可以保证该条数据在数据库
中的所有表中都不重复。
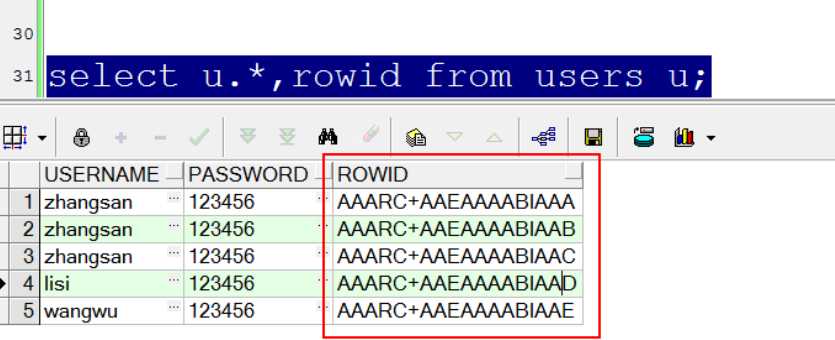
--查询重复数据 用户名和密码都相同的数据叫重复数据 select u1.*,rowid from users u1 where exists ( select 1 from users u2 where u1.username=u2.username and u1.password=u2.password and u1.rowid>u2.rowid );
--删除重复数据 delete from users u1 where exists ( select 1 from users u2 where u1.username=u2.username and u1.password=u2.password and u1.rowid>u2.rowid );
例:把用户表的主键id加上,去重重复数据,只要用户名相同,就认为这条数据重复了。
delete from users u1 where exists ( select 1 from users u2 where u1.username=u2.username and
u1.id>u2.id);
二:oracle实现分页
mysql中怎么实现分页,使用limit m,n m从第几条数据开始取,下标从0开始。n代表最多取多少条数据。
在oracle中不能再使用limit进行分页。可以使用rownum来进行分页。和rowid差不多,rownum也是一个伪列,
rowid是物理上存在的一个伪列,rownum是物理上不存在的。只在查询的时候赋值。用的时候和rowid差不多。
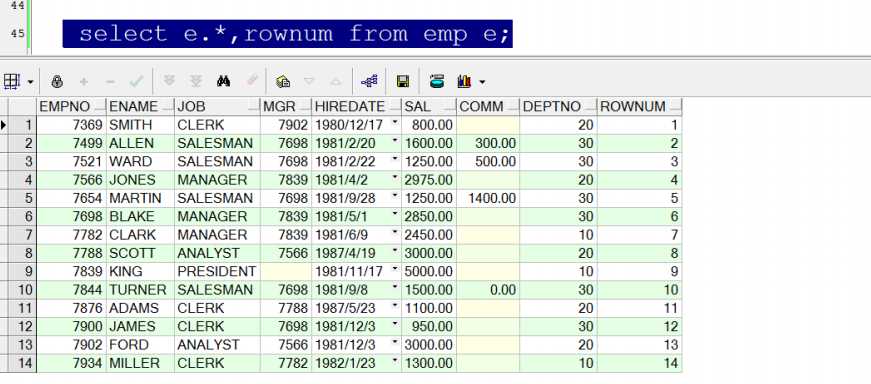
举例:
查询前5条数据:
select * from emp where rownum <6;
查询第6到第10条数据:(错误的)
select * from emp where rownum>5 and rownum<11;
执行直接sql语句,查询不出结果,是因为rownum如果使用大于号查询不到数据:
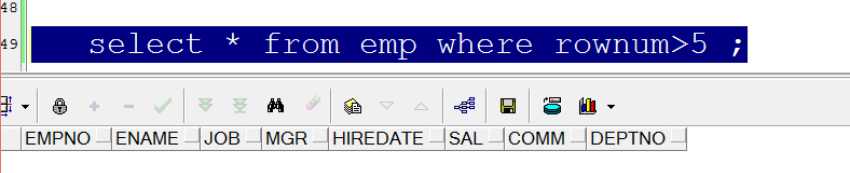
rownum是先查询再赋值。如果查询返回的数据满足条件就获取一个rownum赋值,rownum从1开始赋值,接着 2 3 4 5 6
解决方法:
通过子查询把rownum从伪列变成实际的列。
select * from (select e.*,rownum r from emp e where rownum<11) where r>5
对emp表按empno倒序排列,获取从第6到第10条数据。
select * from ( select e.*,rownum r from ( select * from emp order by empno desc)e where rownum<11 )
where r>5;
以上是关于Oracle中如何删除重复数据的主要内容,如果未能解决你的问题,请参考以下文章