什么是事务日志
事务日志的组成
事务日志大小维护方法
Truncate
Shrink
索引碎片
总结
什么是事务日志
Transaction log 是对数据库管理系统执行的一系列动作的记录,并利用这些记录来保证在遭遇硬件故障,灾难情况下ACID的可用性。从物理上来说,事务日志就是一个记录对数据库更新操作的文件。
事务日志的组成
SQL Server 数据库引擎在内部将每个物理文件分为多个虚拟日志文件。虚拟日志文件没有固定大小和固定数量,这两个值是由数据库引擎动态决定的。
事务日志是一个循环文件。当数据库创建以后,逻辑日志从物理日志文件的起始位置开始。新的日志记录被添加到逻辑日志的后面直到物理日志文件的末尾。日志截取会把LSN(Log Sequential Number)比最小恢复日志序列号(MinLSN)早的虚拟日志记录给释放掉。MinLSN 是要实现一次成功的数据库范围回滚所需要的最小日志记录。
事务日志的结构如下:
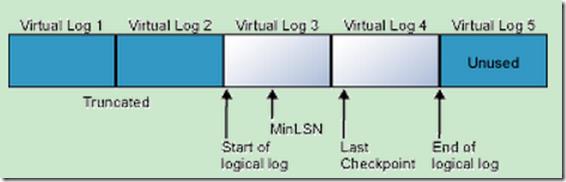
每个虚拟日志有多条记录组成,每条记录都有一个LSN(一条SQL 原子语句)。分析上面的图我们可以看到虚拟日志1和2被截取了,这说明虚拟日志1和2中的事务已经成功提交(并不代表数据修改已经物理上被更新到数据库文件中,因为有一个涉及磁盘IO效率问题)。
当逻辑日志到达物理日志文件的末尾以后,新的日志记录会循环到物理日志的开头位置,如下图所示:
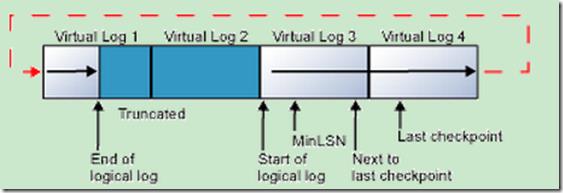
只要逻辑日志尾不超过逻辑日志头,这种循环就永远不会结束。如果旧的日志记录能够被周期性/频繁的截取,那么就会有足够的可用空间留给新添加的日志记录,这样整个物理日志文件大小就会保持在一个相对稳定的范围,反之则会出现以下两种情况之一:
- 如果设置了自动增长,则会按照增长百分比/值来增加物理日志文件大小,这就是为什么我们的事务日志文件经常会变得很大。
- 如果没有设置自动增长或者存储事务日志文件的磁盘没有可用空间了,那么SQL Server 会抛出9002 错误。
注意:如果一个数据库有多个事务日志文件(LDF), 那么除非第一个事务日志文件没有可用空间了,否则不会使用其他的事务日志文件。
事务日志大小维护方法
Truncate
由上面的描述我们可以大概知道Truncate 就是将事务日志中的可以回收的逻辑日志文件标识为可以再次使用,具体的触发条件分为两种情况:
- 对于Recovery Mode 为Simple 的数据库来说,每次事务之后会自动执行CheckPoint 操作,将提交完的逻辑日志空间清空,以保证事务日志文件大小最小。这等同于事务日志中没有日志记录,那么可以理解成没有事务日志,一旦发生灾难,可能会导致数据丢失。
- 对于Recovery Mode 为Full/Bulked-Log 来说,每次进行Backup Log 操作都会自动执行CheckPoint 操作,将提交完的逻辑日志空间清空。换句话说我们能通过周期性的日志备份来维护事务日志文件大小的可控。
打开查询分析器,执行以下查询:
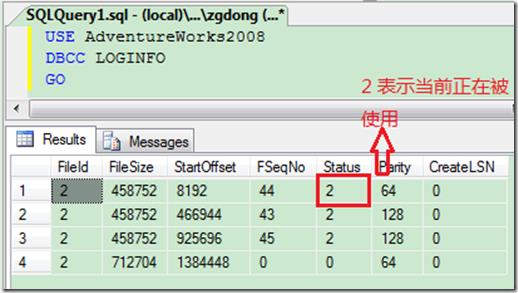
现在对数据库执行一次日志备份, 然后执行LOGINFO命令:

可以看到逻辑日志1,2的状态被标识为0,这意味着逻辑日志1和2都可以被重用了。但是我们再观察下逻辑日志4的偏移和大小,这两个值并没有变,也就意味着整个事务日志大小仍然为:
1384448+712704=2,097,152 字节(纯逻辑日志文件大小 + 8192字节头)

Shrink
Shrink 即是收缩日志,Truncate 操作并不会改变整个事务日志文件大小,只会将原本活跃的逻辑日志标记为不活跃以供下次使用;
Shrink 操作会完全破坏索引的物理结构,导致产生索引碎片,使索引失效。
为什么会这样呢?因为数据文件收缩操作每次执行都会使用GAM 位图算法来找到文件中最大文件,然后将它尽可能地移动到文件头,如此反复(类似冒泡排序)。这样就会完全打乱聚簇索引的顺序,导致它由一个秩序进展的索引变成杂乱无章的索引。
对于DBCC SHRINKFILE, DBCC SHRINKDATABASE, 以及auto-shrink 它们都会产生一样的后果,引入索引碎片, 导致大量I/O操作,CPU 消耗以及事务日志的过载。
来看一个例子,先创建一个数据库:
USE MASTER; GO IF DATABASEPROPERTYEX (\'DBMaint2008\', \'Version\') > 0 DROP DATABASE DBMaint2008; CREATE DATABASE DBMaint2008; GO USE DBMaint2008; GO SET NOCOUNT ON; GO -- Create the 10MB filler table at the \'front\' of the data file CREATE TABLE FillerTable (c1 INT IDENTITY, c2 CHAR (8000) DEFAULT \'filler\'); GO -- Fill up the filler table INSERT INTO FillerTable DEFAULT VALUES; GO 1280 -- Create the production table, which will be \'after\' the filler table in the data file CREATE TABLE ProdTable (c1 INT IDENTITY, c2 CHAR (8000) DEFAULT \'production\'); CREATE CLUSTERED INDEX prod_cl ON ProdTable (c1); GO INSERT INTO ProdTable DEFAULT VALUES; GO 1280
然后查询索引碎片百分比:
-- check the fragmentation of the production table SELECT [avg_fragmentation_in_percent] FROM sys.dm_db_index_physical_stats ( DB_ID (\'DBMaint2008\'), OBJECT_ID (\'ProdTable\'), 1, NULL, \'LIMITED\'); GO
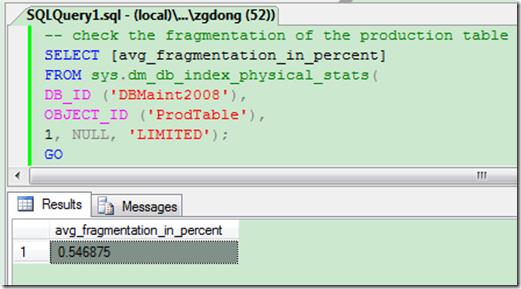
通过上面截图可以发现初始情况下索引的碎片百分比仅0.5%, 这种情况已经非常好了。
我们把刚才创建的表删掉并通过DBCC Shrink 操作回收空间:
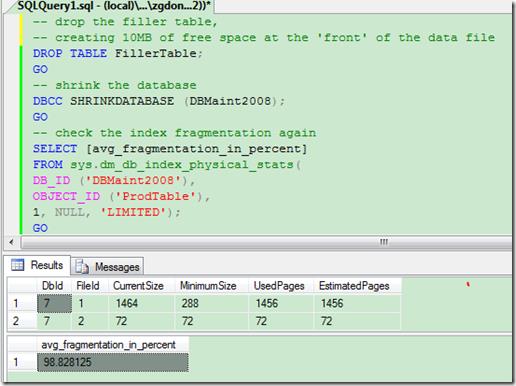
可以看到索引碎片百分比已经接近100%,这样情况下索引不但不会为我们查询数据提高效率,反而会加重系统的负担。
索引碎片
SQL Server 提供了两种命令来处理上述情况:
a. Rebuild 索引
USE DBMaint2008; GO ALTER INDEX ALL ON ProdTable REBUILD GO
b. Reorganize索引
USE DBMaint2008; GO ALTER INDEX ALL ON ProdTable REORGANIZE GO
我们来看一下对上面索引碎片接近100%的表进行索引重组后的效果:
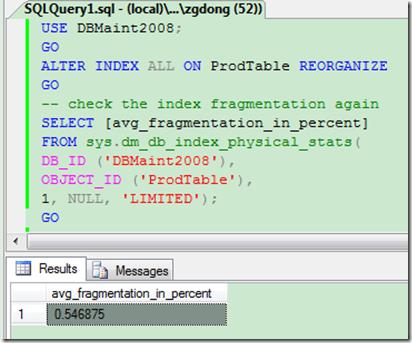
可以看到数据库表的索引恢复了正常,但是这种方案也不完全推荐,对于数据量很大的聚簇索引来说,重建/重组织索引会产生大量I/O, CPU 消耗,所以平时好好维护索引才是我们应该做的。
总结
- Truncate 只会将虚拟日志的活跃部分变成非活跃部分,这样就可以重用这些空间,它并不会影响整体事务日志大小;对于Simple 数据库来说每次事务结束后都会执行CheckPoint 检查,对于Full/Bulked-Log 数据库来说每次日志备份操作以后都会执行CheckPoint 检查。
- Shrink 操作可以减小日志文件的物理文件大小,同时也导致日志文件被重新组织,聚簇索引和非聚簇索引的原有结构都会被打乱,导致产生索引碎片,继而带来的影响是索引失效,磁盘I/O 和 CPU 的资源消耗加大,对于Shrink 我们尽量避免使用它,一旦迫不得已使用Shrink 操作,我们也要按照实际情况决定是否需要重建/重组织索引。
总之,使用周期性的日志备份来维护我们的事务日志文件大小是非常明智的。