Spark在Hadoop集群上运行时虚拟内存超出限制
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark在Hadoop集群上运行时虚拟内存超出限制相关的知识,希望对你有一定的参考价值。
参考技术A在内网搭建了一套Hadoop,接着想在yarn上运行spark-shell,之前单机运行spark-shell没有任何问题,但是当跑到yarn集群的时候问题就来了。 运行时候的报错总是莫名其妙,Google错误后,发现都不是我的情况,所以一直卡了两天都没有头绪,后来看到so上说,可以查每个节点上面的错误信息,查了yarn-nodemanager的日志, 发现了问题的所在,日志里面有这么一条
Container [xxx] is running beyond virtual memory limits. Current usage: 324 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
原来是超出了内存的限制,所以改配置文件就可以了,我就顺手改了配置,将 yarn.nodemanager.resource.memory-mb 的值改为了8192,结果还是报错
这时候发现原来这个只是改变了每台机器划分来给yarn的调度的内存的大小而不是其给每个容器分配的内存大小,后来继续Google后才知道了容器资源分配相关的一些参数,如下:
所以这个异常可以通过一下方式解决
Hadoop集群+Spark集群搭建基于VMware虚拟机教程+安装运行Docker
Hadoop集群+Spark集群搭建+安装运行Docker
目录
一、准备工作
1.软件工具(可从百度网盘获取)
若虚拟机应未安装则根据以下连接进行安装,若已安装则往下看:
VMware Fusion: https://www.vmware.com/cn/products/fusion/fusion-evaluation.html
- JDK 1.8 (jdk-8u221-linux-x64.rpm)
- Hadoop 2.7.7 (hadoop-2.7.7.tar.gz)
- Spark 3.1.1 (spark-3.1.1-bin-hadoop2.7.tgz)
复制这段内容后打开百度网盘App,操作更方便哦。
链接:https://pan.baidu.com/s/1C5knD8CVvL_0RM3D8tQ69Q 提取码:4o9z
2.网络规划
本次规划搭建3台机器集群模式,IP与计算机名分别如下:
node01:192.168.159.80 (主机)
node02:192.168.159.81
node03:192.168.159.82
IP地址可以在虚拟机中点击菜单栏的编辑,再点击虚拟网络编辑器,选择NAT模式,并找到子网IP,IP地址第四位数自行拟定。

二、在虚拟机上安装CentOS 7
虚拟机安装使用的镜像CentOS-7-x86_64-DVD-2009.iso
下载地址:http://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/
1.打开虚拟机(VMware Fusion),点击文件,选择新建虚拟机,如下图所示:
2.选择典型安装。
3.选择稍后安装操作系统。
4.选择Linux系统,选择与我们自己下载的CentSO一致的版本。

5.将虚拟机的名字改成node01(可以根据自己的喜好进行修改),并改变文件存储位置。

6.将最大磁盘大小改为50GB(50已经足够了),并按下图进行选择:
7.观察上述信息,与之前设置的是否一致,并点击自定义硬件。
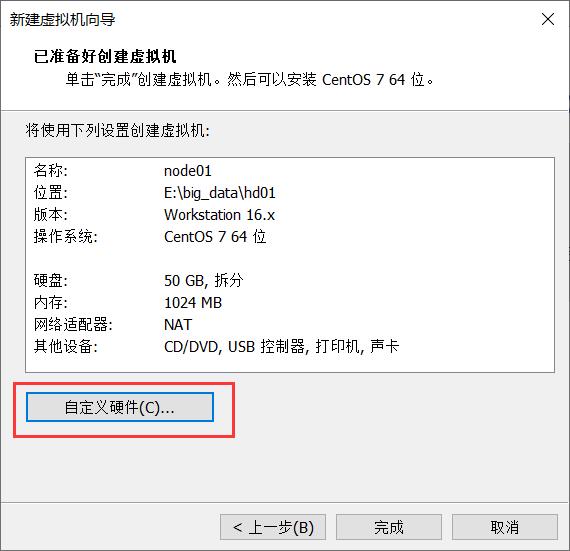
8.点击新CD/DVD(IDE),找到之前下载镜像的路径。点击关闭,完成虚拟机的建立。

9.点击关闭页面后,再点击完成,跳出以下页面,随后点击运行按钮,打开虚拟机。

10.选择第一项,进行CentOs 7的安装,按回车健等待加载。

11.加载完成后,进入安装页面,选择语言(中文),点击继续。

12.点击日期与时间,观察地点是否再上海,如果在则不需要修改。
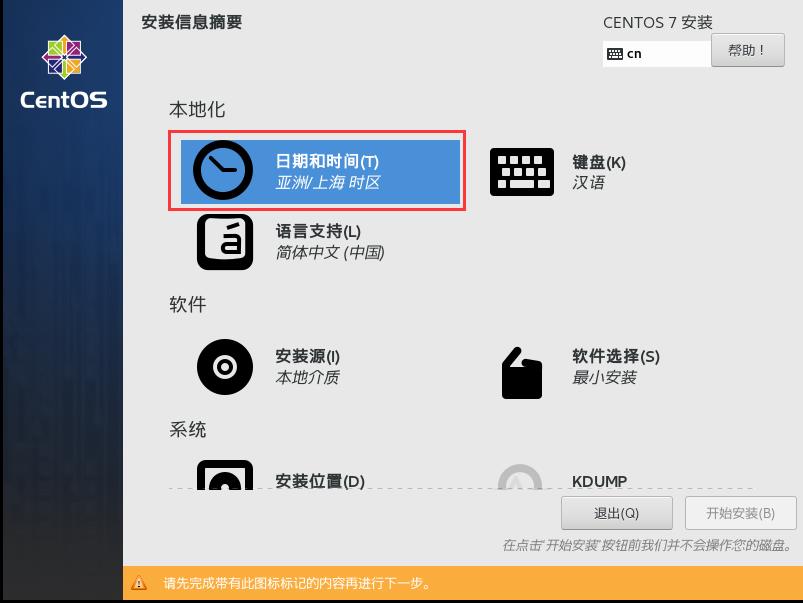
13.点击安装位置,以确认全盘安装。
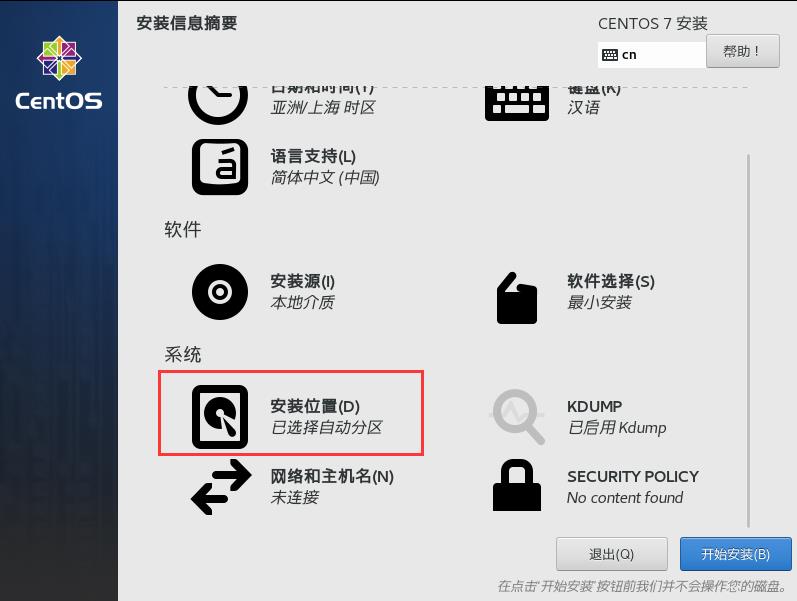
14.确认完毕,点击左上角的完成。
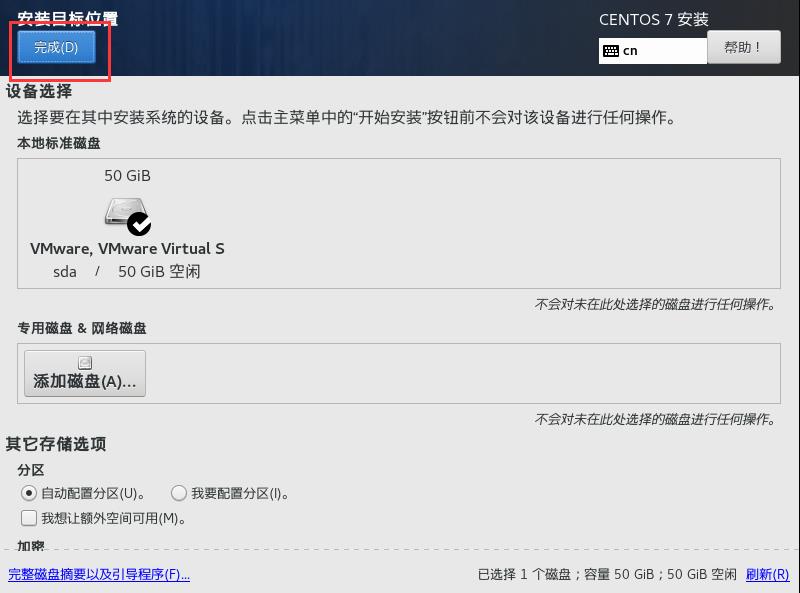
15.点击网络和主机名,配置网络和主机名。
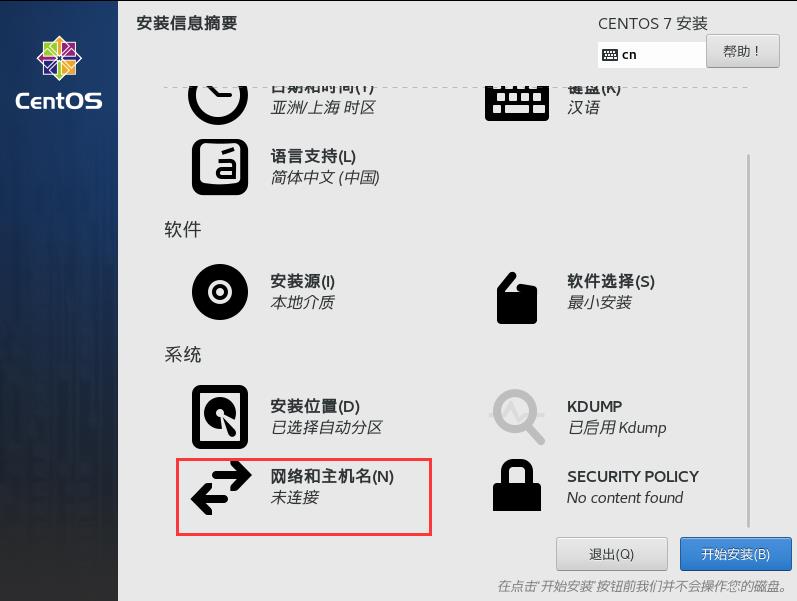
16.将网络打开,并拍照记住,以便后面使用,随后点击配置,进行网络配置。

17.点击IPv4设置,选择手动的方式,为了后面能够进行远程连接以及Hadoop集群间的通信。然后点击Add对地址进行添加,将我们之前规划的主机地址填下,子网掩码为刚才我们拍照记录的数据,网关将其设为刚才看到的默认路由的IP地址。同时将DNS服务器栏的地址填写成我们的网关地址,最后点击保存。

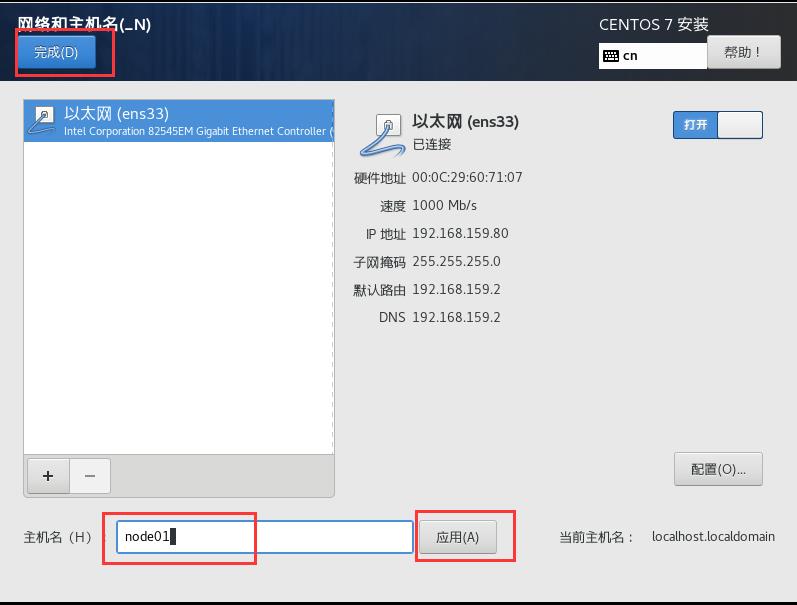
18.将主机名修改成node01(主机),点击应用。并观察图内信息是否有误,如果没有则点击完成。
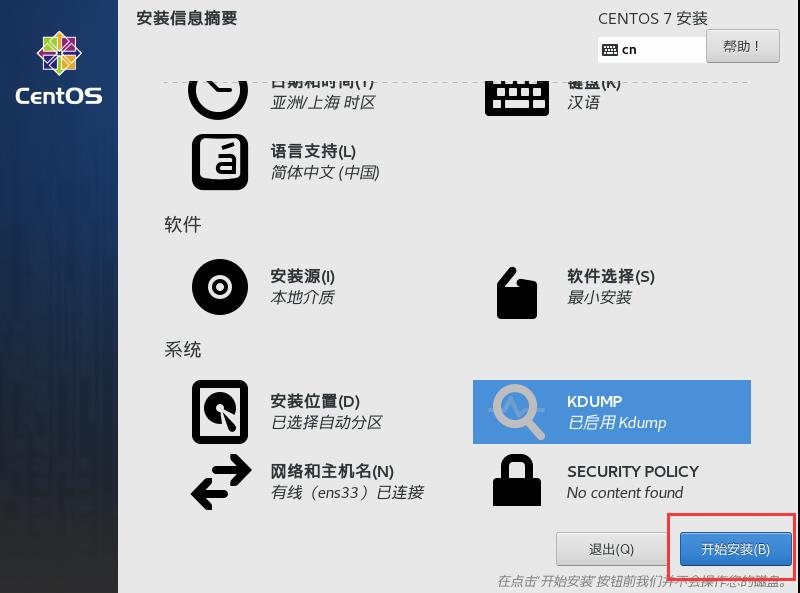
19.点击开始安装。
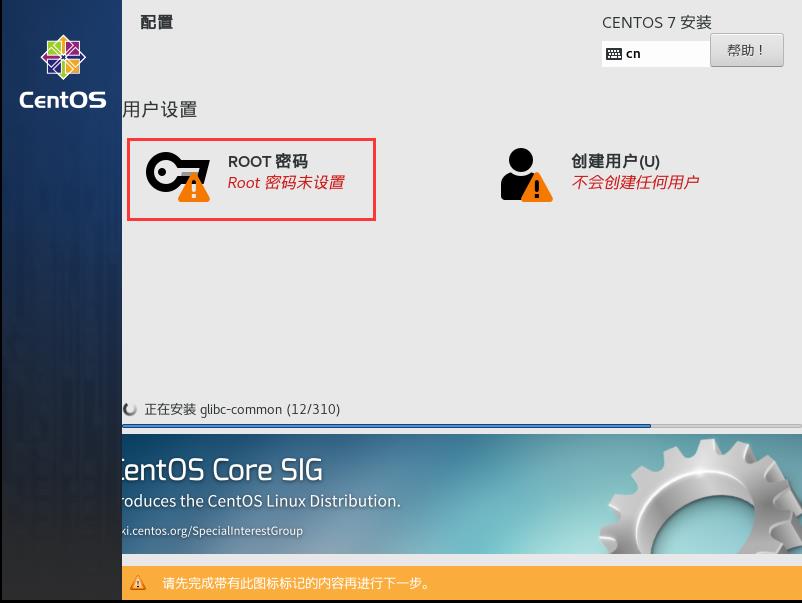
20.在安装的同时,点击ROOT密码,进行密码的设置(此处将密码设置为123456)。
21.点击创建用户,对用户名进行设置。
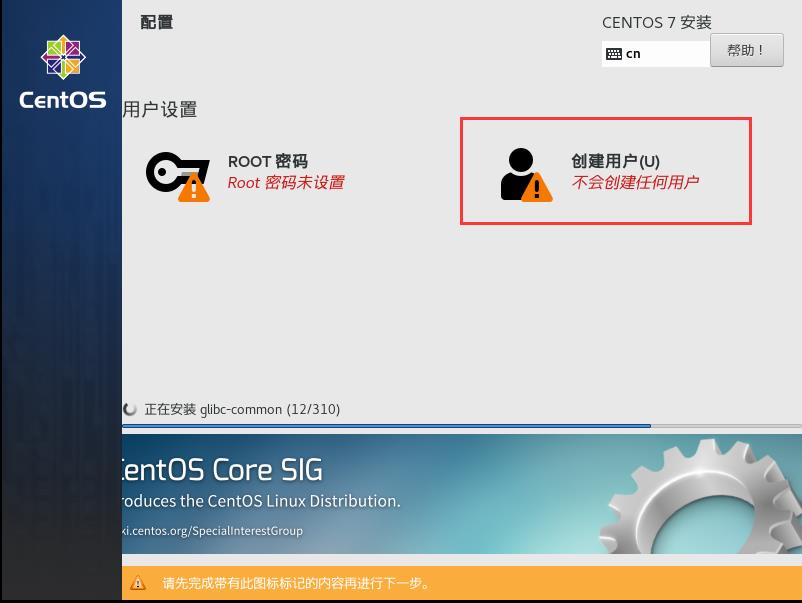
22.将用户名设置成你想要的名字即可(此处设置成rain),密码也与刚才的相似(123456),设置完后点击完成。
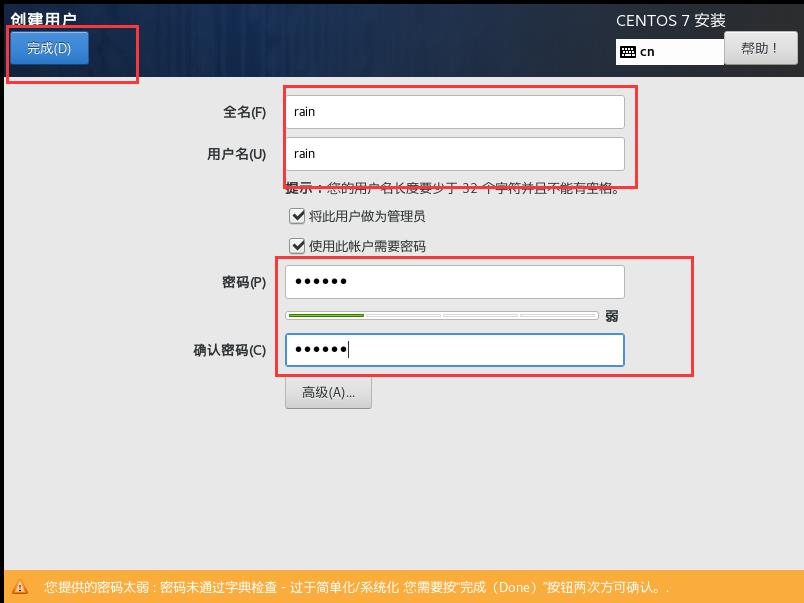
23.设置完并安装完成后,点击重启。

24.在node01 login后输入刚才设置的用户名rain,然后回车,输入密码123456(此处密码不显示)。当显示再次输入框,则表示安装成功。
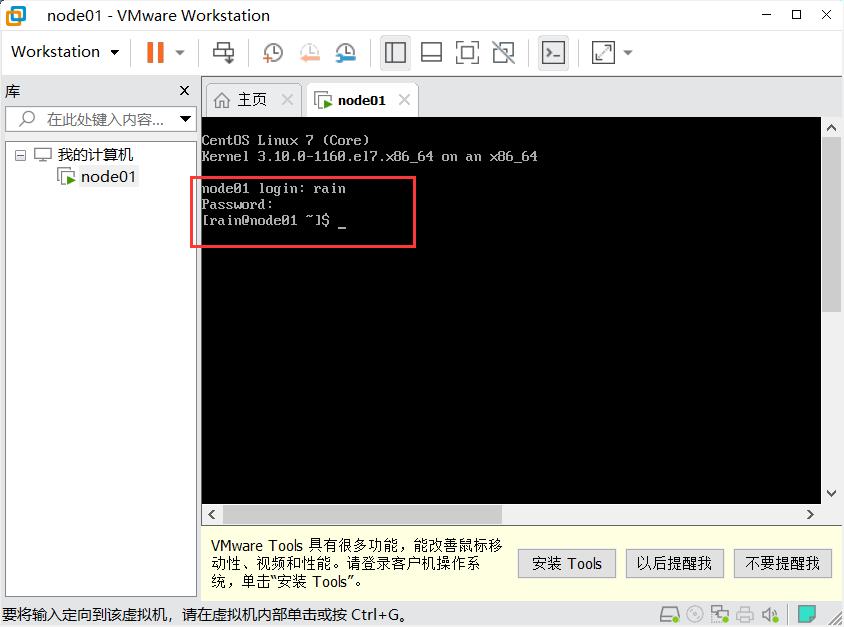
25.输入 ping www.baidu.com 命令,测试虚拟机是否与互联网相连。若出现以下截图情况则表示连接外网成功。(按 ctrl+c 结束ping命令)

26.CentOS安装成功。
三、hdfs的环境准备
配置hdfs环境需要使用MobaXterm(一款增强型远程连接工具)。若没有这款软件,可以进行网盘提取。
链接:https://pan.baidu.com/s/1o0K7pX8lMmkWx6mmktSjPg
提取码:h4yr
1.建立一个session,为了与虚拟机进行一个连接,对其进行配置。输入主机的IP地址,以及用户名,随后点击OK。
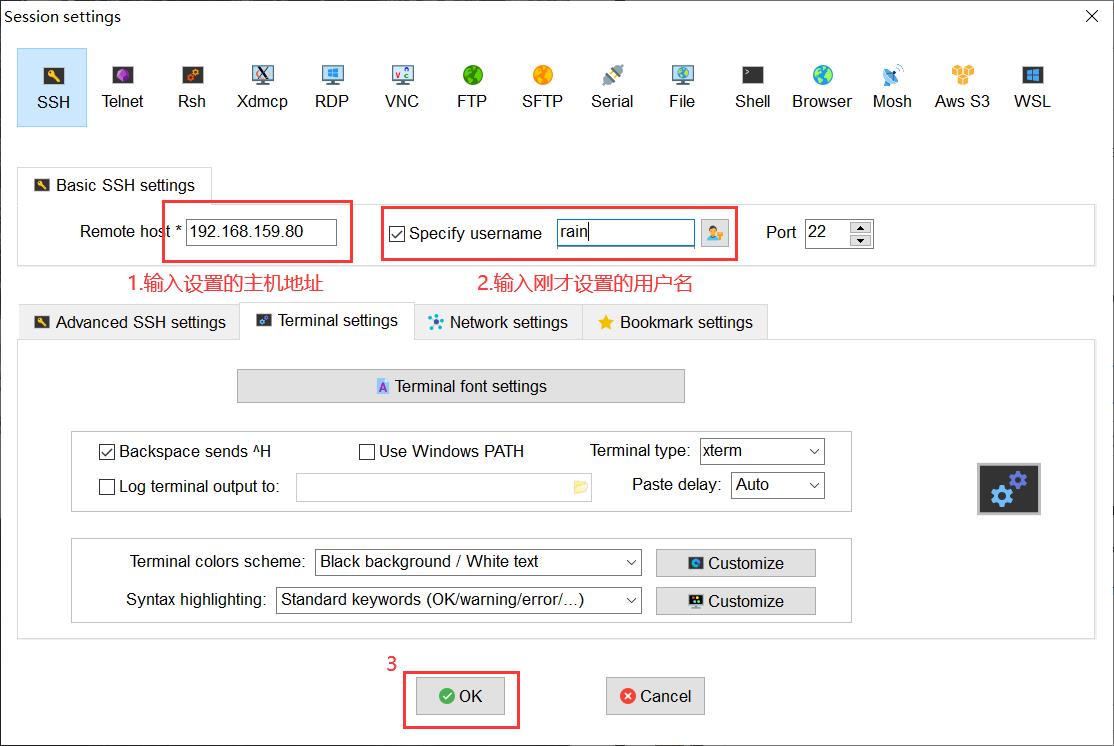
2.创建成功后,输入密码进行登录即可。随后安装基础工具(yum),运行命令
sudo yum install net-tools
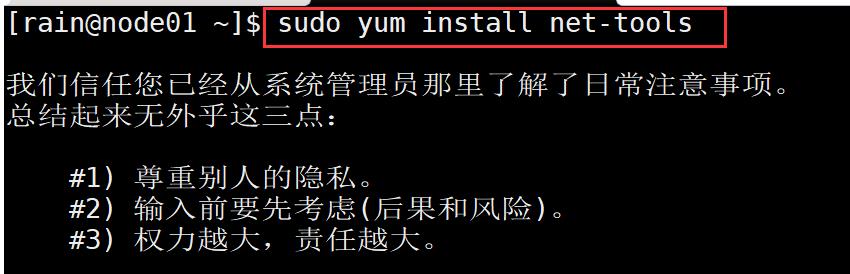
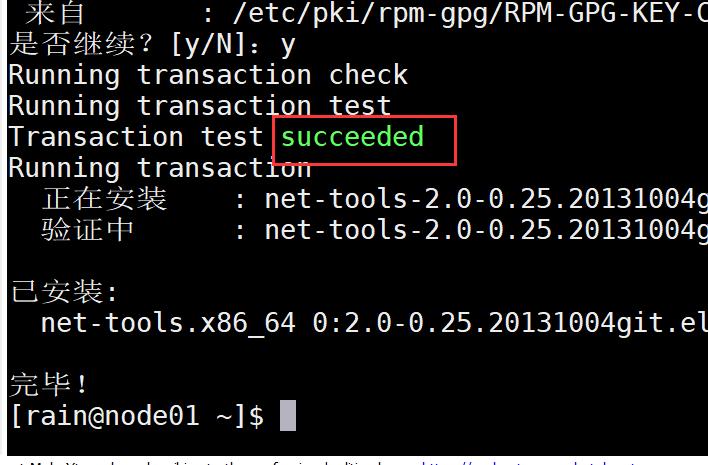
当看到 succeeded 提示时证明yum工具安装成功
3.输入 sudo yum install vim 安装 vim 编辑器,这个和 vi 命令一样,是 vi 命令的增强版,有语法高亮功能,对后面修改Hadoop配置会有所帮助。
4.创建soft文件夹,后面将所有的文件存放在该文件夹下。在rain用户根目录下新建soft文件夹,依次输入以下命令:
mkdir soft
cd soft/

5.点击 soft 文件夹,将下载的网盘文件 jdk-8u221-linux-x64.rpm、hadoop-2.7.7.tar.gz 拖入soft文件夹下。

6.解压刚才上传的2个压缩包。
输入命令:sudo rmp -ivh jdk-8u221-linux-x64.rpm
sudo tar -zxvf hadoop-2.7.7.tar.gz -C /opt/ (解压至 C盘中的opt目录下)


7.进入opt目录,查看当前使用权限,若当前权限不为用户(rain),则应该设置将所有的文件目录归为用户管理。若当前权限为用户(rain),则不做修改。依次输入以下命令进行修改:
cd /opt/ (进入opt目录)
ls -l (查看当前的权限)

查看后发现,当前权限不为用户,则需修改,依次输入命令:
sudo chown -R rain:rain /opt/hadoop-2.7.7
ls -l

8.关闭防火墙(由于Hadoop集群间后面通信过程中也是要求关掉防火墙的,局域网内通信没必要开防火墙)。
临时关闭防火墙 systemctl stop firewalld.service
永久关闭防火墙 systemctl disable firewalld.service
先输入临时关闭防火墙的命令,将当前系统的防火墙关闭,然后再输入永久关闭防火墙命令,这个是防止重启系统防火墙自动开启。

9.关闭Linux系统安全内核selinux(若不关Hadoop集群在进行文件传递时会出现错误)。
输入命令:sudo vim /etc/selinux/config ,进入编辑selinux的配置文件。
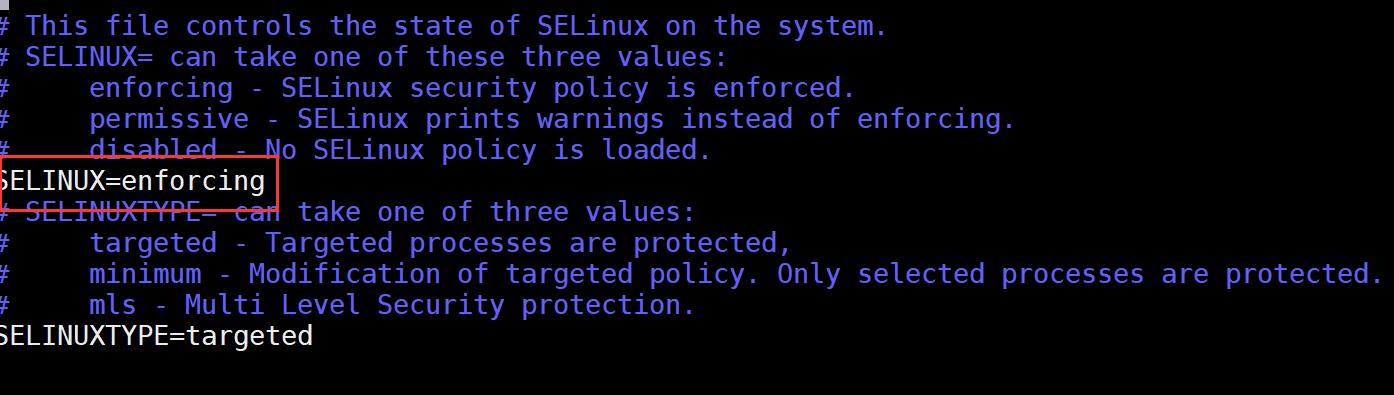
按下按键上的字母键i,进入编辑模块(左下角会提示当前为INSERT状态,表明可修改内容)。
找到 SELINUX=enforcing 这一行,修改SELINUX=disabled。随后按下按钮 esc 键,按下 : 键,输入 wq 保存退出 (q为退出)。
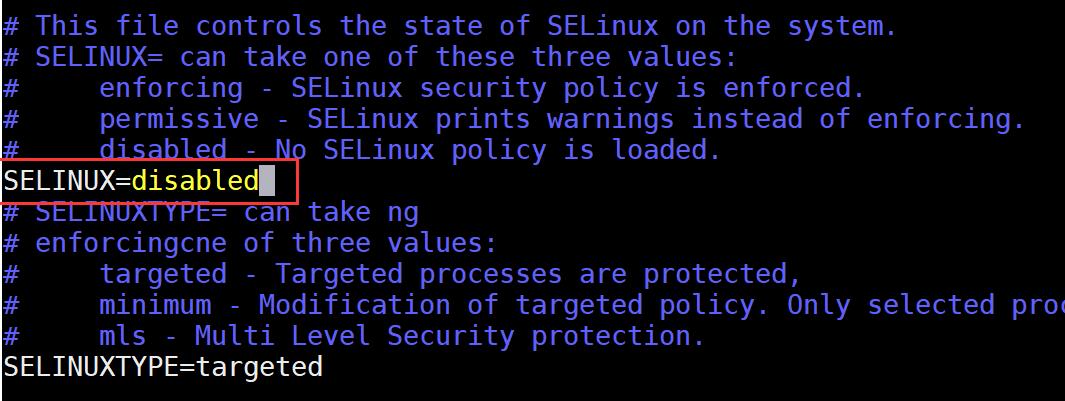
10.输入 sudo reboot 回车重启系统,使以上命令生效
11.添加hfds的环境变量。
先进入到sbin目录下:cd /opt/hadoop-2.7.7/sbin/
输入 sudo vim /etc/profile 多按几次 Tab 查看profile文件
然后加上在 profile 文件里面添加 hdfs.sh 文件 ,并用vim对文件进行编辑。
输入命令:sudo vim /etc/profile.d/hdfs.sh

将以下内容添加到文件中:
export HADOOP_HOME=/opt/hadoop-2.7.7
export PATH=$PATH:$HADOOP/bin:$HADOOP_HOME/sbin

随后按下按钮 esc 键,按下 : 键,输入 wq 保存退出 (q为退出)。
保存后,输入以下命令使修改的配置生效:
source etc/profile
12.创建目录 big_data ,以便以后将数据存入。
在sbin目录下输入创建命令:sudo mkdir /var/big_data

该目录现在不归用户(rain)管理,所以对用户权限进行修改。
输入命令:sudo chown -R rain:rain /var/big_data

至此,hdfs的环境准备工作完毕。
四、hdfs配置文件的修改
1.修改hadoop-env.sh
先cd到 hadoop-2.7.7 文件夹下,输入命令:cd /opt/hadoop-2.7.7/etc/hadoop/
输入命令:vim hadoop-env.sh ,修改 hadoop-env.sh 。
将原来export JAVA_HOME那一项修改为以下值(指明本机JAVA_HOME的路径),然后wq保存退出:
export JAVA_HOME=/usr/java/default
2.修改yarn-env.sh
先cd到 hadoop-2.7.7 文件夹下,输入命令:cd /opt/hadoop-2.7.7/etc/hadoop/
输入命令:vim yarn-env.sh ,修改 yarn-env.sh 。
同样修改 JAVA_HOME=/usr/java/default ,然后wq保存退出。
# some Java parameters
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/usr/java/default
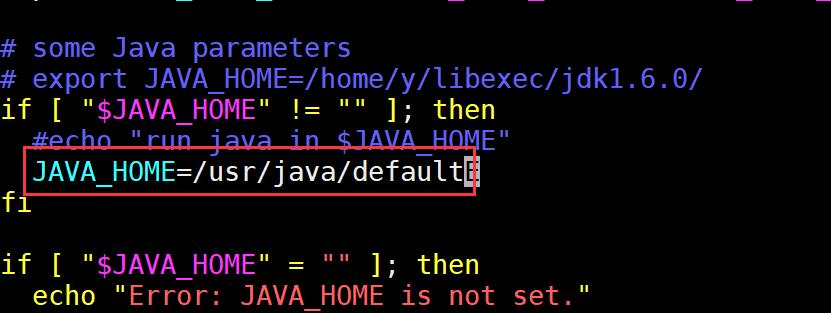
3.修改core-site.xml
先cd到 hadoop-2.7.7 文件夹下,输入命令:cd /opt/hadoop-2.7.7/etc/hadoop/
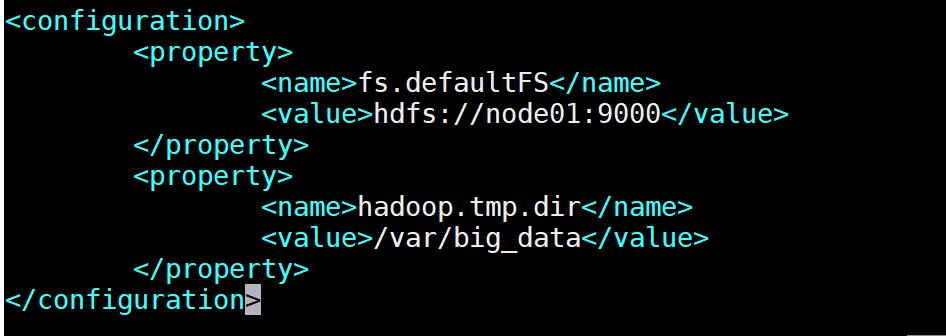
输入命令:vim core-site.xml ,修改 core-site.xml 。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node01:9000</value>
</property>
<!--用来指定hadoop运行时产生的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/big_data</value>
</property>
</configuration>
4.修改hdfs-site.xml
先cd到 hadoop-2.7.7 文件夹下,输入命令:cd /opt/hadoop-2.7.7/etc/hadoop/
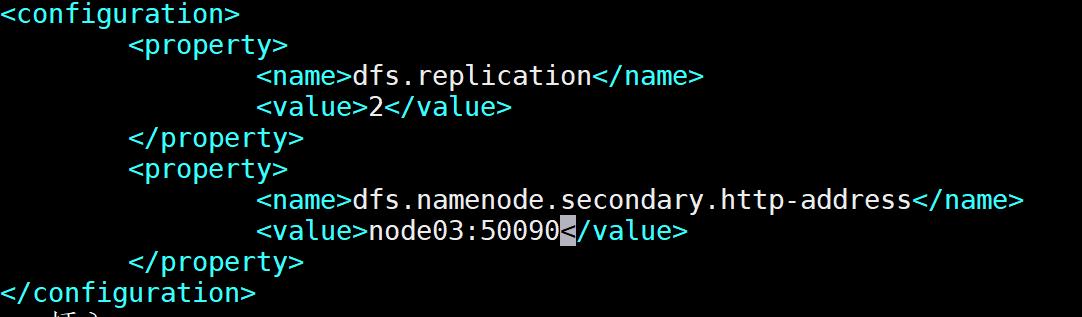
输入命令:vim hdfs-site.xml ,修改 hdfs-site.xml 。
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node03:50090</value>
</property>
</configuration>
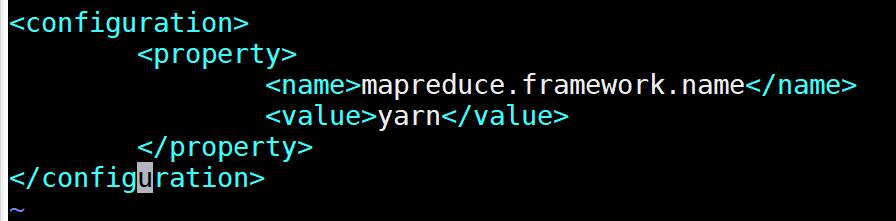
5.修改mapred-site.xml
先cd到 hadoop-2.7.7 文件夹下,输入命令:cd /opt/hadoop-2.7.7/etc/hadoop/
输入命令:cp mapred-site.xml.template mapred-site.xml 先复制一下文件,在对其进行修改。
输入命令:vim mapred-site.xml ,修改 mapred-site.xml 。
将以下内容复制粘贴到文件中,保存退出:
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
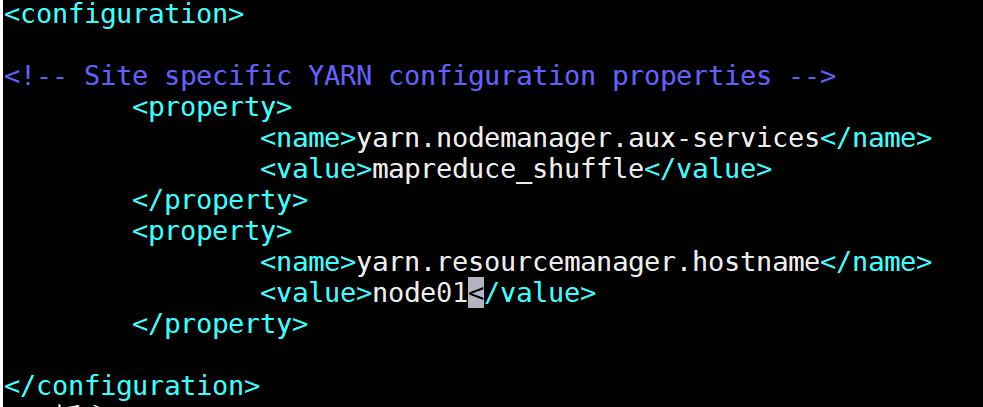
6.修改yarn-site.xml
先cd到 hadoop-2.7.7 文件夹下,输入命令:cd /opt/hadoop-2.7.7/etc/hadoop/
输入命令:vim yarn-site.xml ,修改 yarn-site.xml 。
将以下内容复制粘贴到文件中:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
</configuration>
7.修改slaves
先cd到 hadoop-2.7.7 文件夹下,输入命令:cd /opt/hadoop-2.7.7/etc/hadoop/
输入命令:vim slaves ,修改 slaves 。
将以下内容复制粘贴到文件中:
node01
node02
node03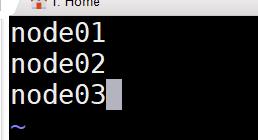
8.准备主机名解析文件,为了后面克隆做好准备。
输入命令:sudo vim /etc/hosts ,进入编辑。
将刚看到的里面的前两行删除掉,下图圈出的部分。
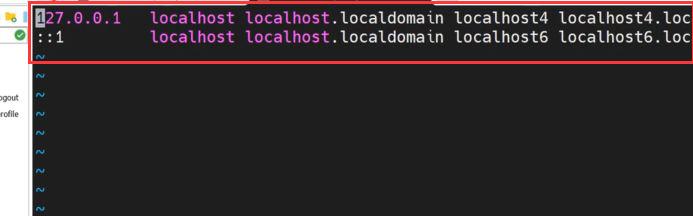
将其内容改为我们之前规划的三台机子的IP以及名称。

至此,hdfs配置文件的修改工作完成。
五、克隆(复制虚拟机)
1.克隆时虚拟机不能为开机状态,所以先将虚拟机关机(强关即可),按下图操作关闭虚拟机。

2.将鼠标放置在虚拟机上右击,选择管理->克隆,随后点击下一步。
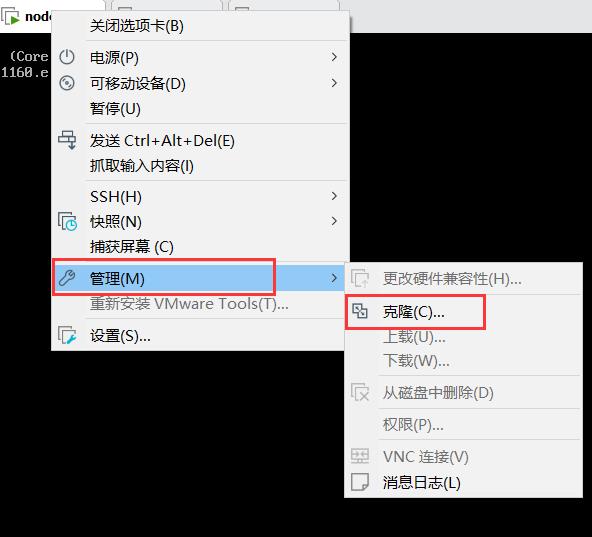
3.选择 虚拟机中的当前状态 进行克隆。
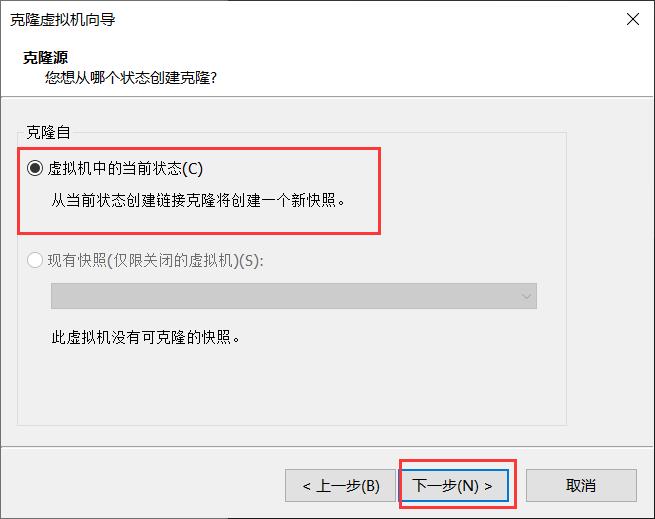
4.选择创建完整克隆,点击下一步。
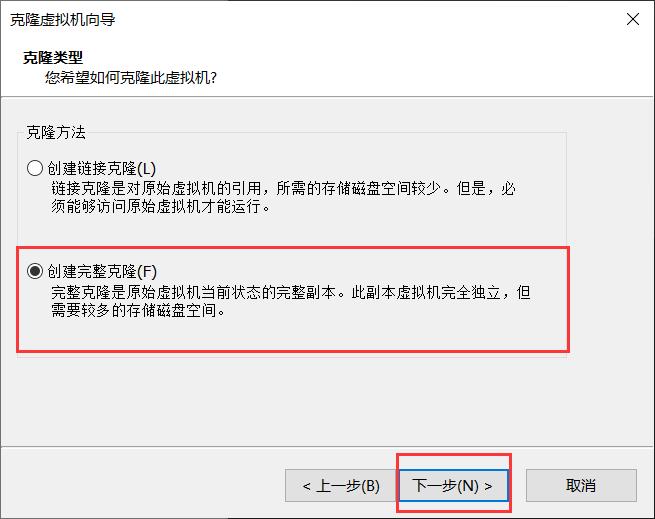
5.输入你要克隆生成的虚拟机名字以及将其所存放的位置,点击完成,等待克隆完毕。

(第三个虚拟机克隆的步骤也是一样的,再次循环步骤1.2.3.4.5)
6.克隆完后,需要node02、node03的IP 和主机名进行修改。
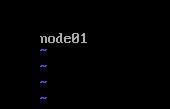
a.在当前虚拟机 node02 页面,输入命令:sudo vim /etc/hostname ,对其主机名进行修改。
将里面 node01 修改为 node02 。
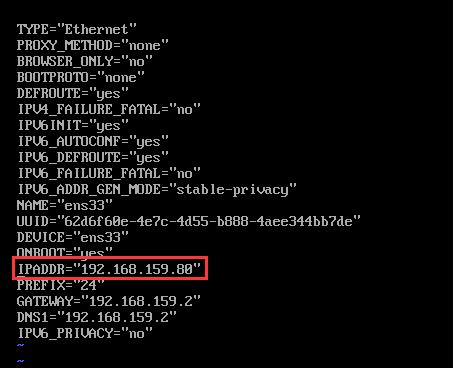
b.在当前虚拟机 node02 页面,输入命令:sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33 ,对其IP地址进行修改。
将图下圈出的地方的IP设置为 192.168.159.81 ,保存后退出。
7.输入 sudo reboot 对虚拟机进行重启。
第三台虚拟机(node03)的配置与上述一致,配置内容与之前规划的一致即可。
至此,虚拟机的克隆完成。
六、制作免密码登陆
1.使用MobaXterm,建立一个 node02、node03 的session,为了与虚拟机进行一个连接,对其进行配置。输入主机的IP地址,以及用户名,随后点击OK(步骤三、1与上述一致)。
2.点击菜单栏上的  按钮,使其三个虚拟机同时进行。
按钮,使其三个虚拟机同时进行。
3.在 node01 中输入命令: ssh-keygen -t rsa ,然后一路按回车,直到命令运行结束。

4.在 node01 依次输入以下命令:
ssh-copy-id node01
ssh-copy-id node02
ssh-copy-id node03
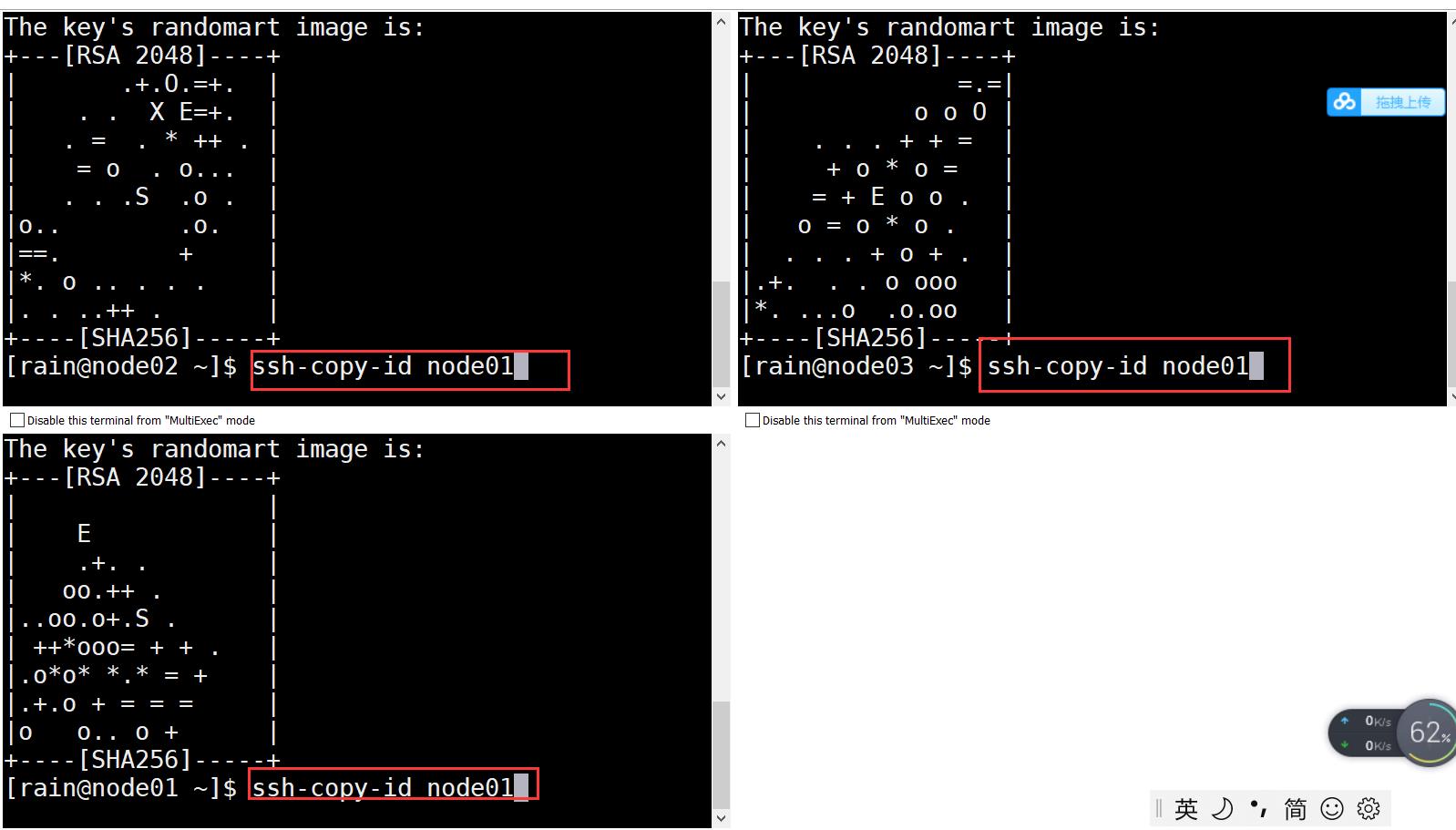
5.此时退出该页面,通过ssh命令测试互相登陆,如果相互登陆都不需要密码的话,表示免密码登陆设置成功。
node01 主机(node02、node03跟该步骤一致):

至此,免密完成。
七、一行命令启动 Hadoop 集群
1.格式化hadoop文件系统(该命令只能在node01上执行,且只能执行一次,不可多次执行。)
输入命令:hdfs namenode -format

当看到如上图中所示 successfully 提示信息则表示格式化成功。
2.输入命令:start-dfs.sh ,开始集群。

3.用宿主机浏览器访问 http://192.168.159.80:50070 查看启动是否成功。
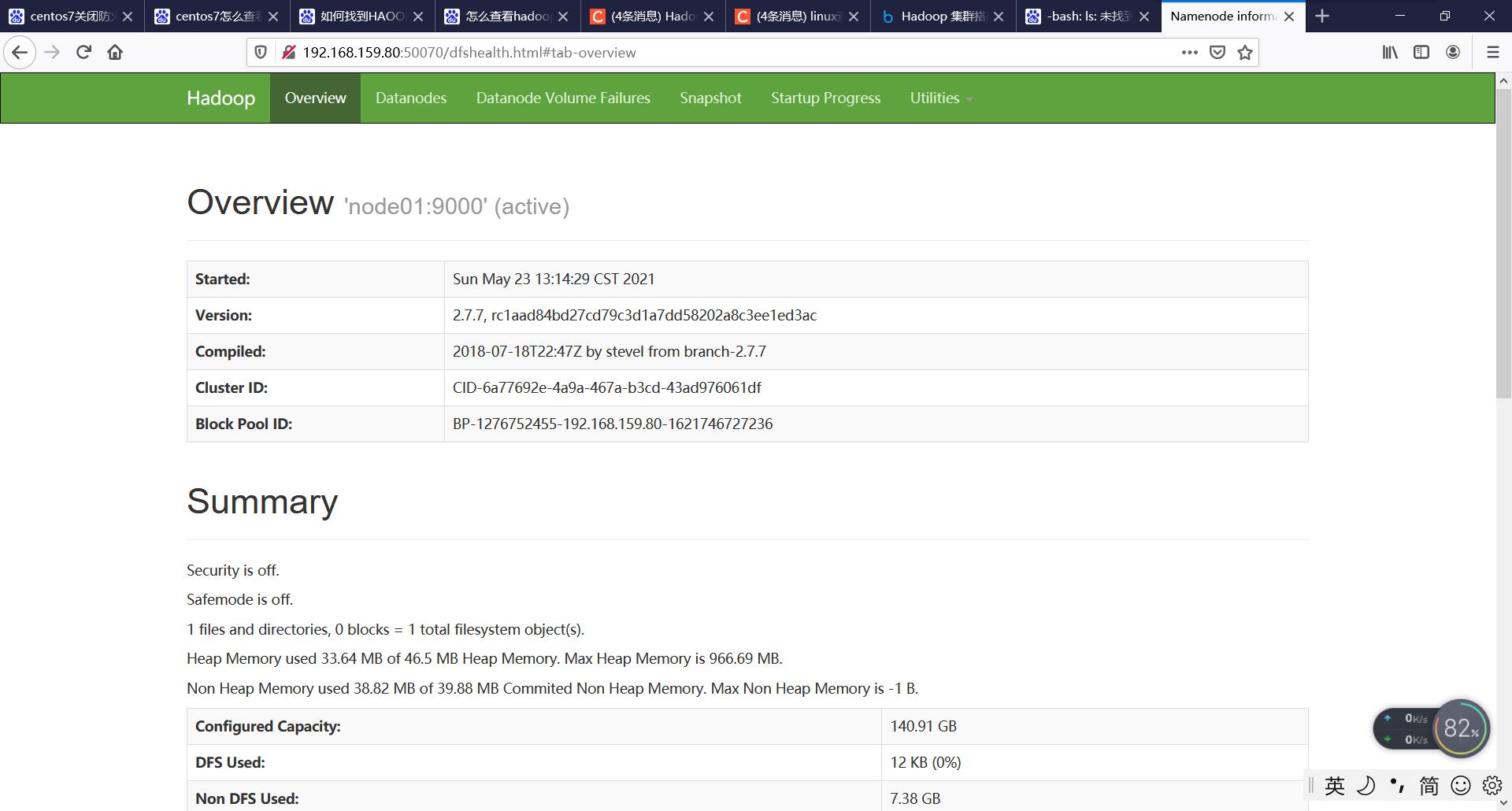
找到网页中的summary,点开livenodes查看现在是否有3台节点同时在线,如果不是3台,则说明配置有问题,需要重新排错,按照教程前面内容仔细检查,如果显示是3台主机在线,则表明配置成功。

3.测试hadoop是否集群成功
输入命令:hdfs dfs -mkdir /t01
然后访问 http://192.168.159.80:50070 查看情况

至此,hadoop集群搭建完成。
八、Spark集群
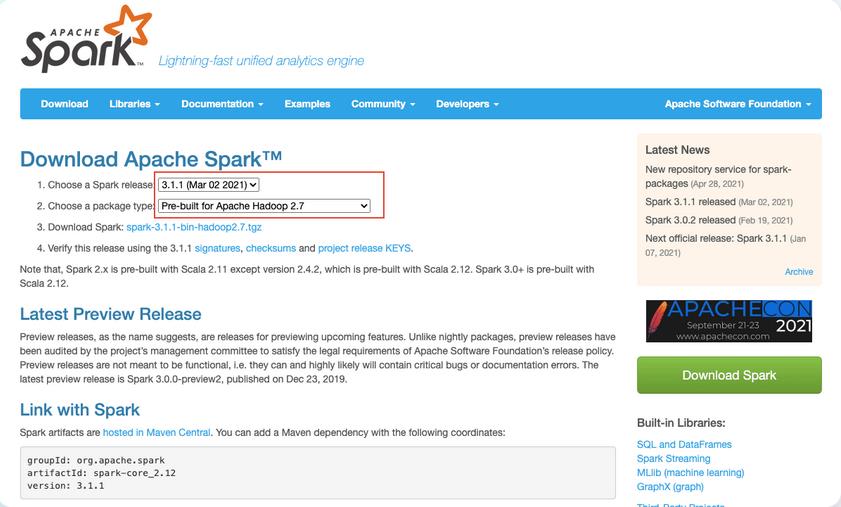
1.登陆Apache spark官网下载spark
地址:http://spark.apache.org/downloads.html
选择如下图所示版本进行下载
2.将刚才下载的压缩包拖入soft文件下,进行解压。
按以下命令依次输入查看soft文件夹下是否已上传刚才的文件:
先cd到opt目录 : cd /opt/
然后查看: ls

然后执行解压缩命令 sudo tar -zxvf spark-3.1.1-bin-hadoop2.7.tgz
3.修改环境变量,添加spark
先进入到sbin目录下:cd /opt/hadoop-2.7.7/sbin/
输入命令:sudo vim /etc/profile.d/hdfs.sh
然后在末尾添加以下内容:
export SPARK_HOME=/opt/spark-3.1.1-bin-hadoop2.7
export PATH=$JAVA_HOME/bin:SPARK_HOME/bin:$PATH

随后按下按钮 esc 键,按下 : 键,输入 wq 保存退出 (q为退出)。
保存后,输入以下命令使修改的配置生效:
source etc/profile
4.编辑spark-env.sh
先进入conf文件夹 cd /opt/spark-3.1.1-bin-hadoop2.7/conf/
首先复制一份spark-env.sh,并将其改名 cp spark-env.sh.template spark-env.sh
编辑spark-env.sh vim spark-env.sh
将以下内容添加到文件中:
export JAVA_HOME=/usr/java/default
export SPARK_MASTER_IP=192.168.159.80
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/opt/hadoop-2.7.7/etc/hadoop

5.添加node01,node02,node03节点信息
输入命令: vim /opt/spark-3.1.1-bin-hadoop2.7/conf/slaves
6.将spark文件夹复制到node01,node02
依次运行下面命令:
cd /opt/
scp -r spark-3.1.1-bin-hadoop2.7 root@node02:/opt/
scp -r spark-3.1.1-bin-hadoop2.7 root@node03:/opt/
7.进入spark文件夹,启动spark
依次运行以下命令:
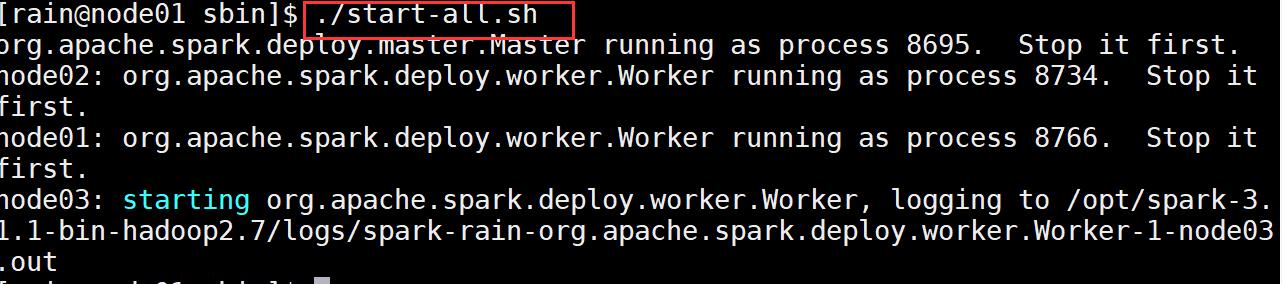
cd /opt/spark-3.1.1-bin-hadoop2.7/sbin/
/start-all.sh
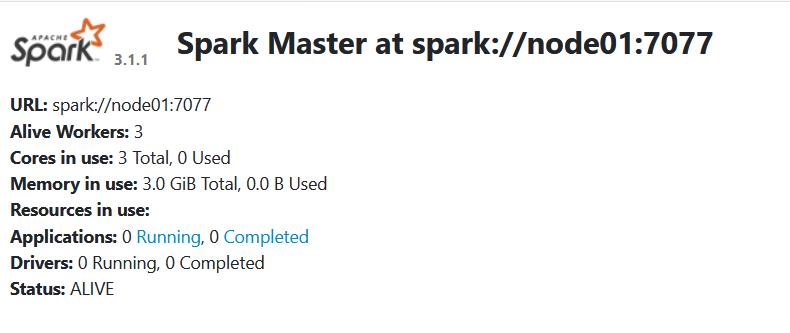
8.在宿主机的浏览器中访问地址:http://192.168.159.80:8080 ,查看是否能成功访问,如果可以,则spark启动成功。
9.测试spark运行是否正常
依次运行以下命令:
cd ~
/opt/spark-3.1.1-bin-hadoop2.7/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://nde01:7077 /opt/spark-3.1.1-bin-hadoop2.7/examples//jars/spark-examples_2.12-3.1.1.jar 100然后打开spark的WebUI查看运行情况

至此,Spark集群完毕。
九、MapReduce示例
1.进入到Hadoop-2.7.7文件夹,选取测试文件。
依次输入以下命令:
cd /root/Hadooptools/hadoop-2.7.7
ls -all

此处选择 NOTICE.txt 作为测试文件。
2.输入命令:start-all.sh 启动hadoop集群。
3.上传文件到hdfs
依次输入以下命令:
hadoop fs -mkdir /input
hadoop fs -put NOTICE.txt /input
hadoop fs -ls -R /

4.运行实例程序。
输入命令:hadoop jar /opt/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output
输入命令 :hadoop fs -ls -R / 查看程序运行后产生的文件
输入命令 :hadoop fs -cat /output/part-r-00000 查看程序运行结果

运行出测试文件内容,则测试完毕。
至此,hadoop集群的所有搭建完成。
十、Docker安装
Docker的安装在没有虚拟机的环境下进行。
1.开启win10的Hyper-V
控制面板 -> 程序 -> 启用或关闭Windows功能 -> 选中Hyper-V
确定后,重启电脑,完成功能的设置

2.下载Docker for Windows
官网地址:https://docs.docker.com/docker-for-windows/install/#download-docker-for-windows

一直点击 Next,安装路径根据自己路径更改,点击 Finish 完成安装。
3.去微软官网下载最新版的wsl2。
下载地址:https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
4.启动docker:桌面双击启动
5.通过cmd指令查看docker版本。
依次输入命令:
docker --version
docker version
docker info


5.测试用例——hello-world:docker run hello-world

至此,docker的安装完毕。
本文参考:
https://blog.dhbxs.top/posts/d06540f2.html
https://blog.csdn.net/ZN_COME/article/details/117167474
以上是关于Spark在Hadoop集群上运行时虚拟内存超出限制的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop集群+Spark集群搭建基于VMware虚拟机教程+安装运行Docker
Hadoop集群+Spark集群搭建基于VMware虚拟机教程+安装运行Docker