搭建MySql主从复制与读写分离
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搭建MySql主从复制与读写分离相关的知识,希望对你有一定的参考价值。
一、实验名称:
?mysql主从复制读写分离
二、实验目的:?
?熟悉mysql主从复制的原理
?熟悉mysql读写分离的原理
?学会配置mysql主从复制
?学会配置mysql读写分离
三、实验环境:?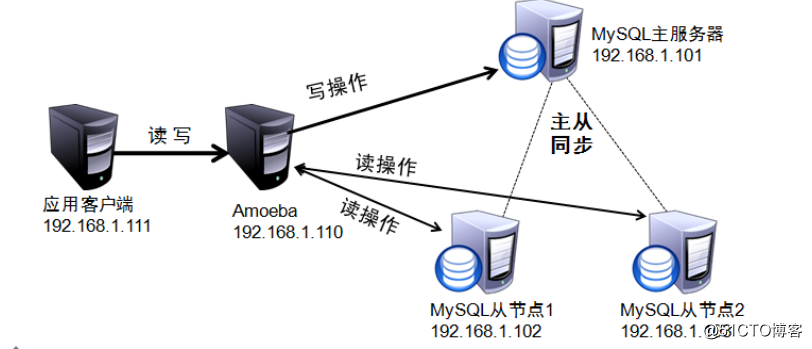
主机 操作系统 IP地址 主要软件
Master CentOS 6.5 x86_64 /linux6.5 192.168.1.101 cmake-2.8.6.tar.gz
mysql-5.5.22.tar.gz
Slave1 CentOS 6.5 x86_64 /linux6.5 192.168.1.102 cmake-2.8.6.tar.gz
mysql-5.5.22.tar.gz
Slave2 CentOS 6.5 x86_64 /linux6.5 192.168.1.103 cmake-2.8.6.tar.gz
mysql-5.5.22.tar.gz
Amoeba CentOS 6.5 x86_64 /linux6.5 192.168.1.110 amoeba-mysql-binary-2.2.0.tar.gz
jdk-6u14-linux-x64.bin
客户端 CentOS 6.5 x86_64 /linux6.5 192.168.1.111
注:将所需软件拷贝至/usr/src中
四:实验思路:
1.安装mysql
2.配置mysql的主从复制
3.配置mysql的读写分离
实验过程
一:网络环境的部署(本步骤每个机器都要设置)
1:按照图表设置每台服务器的ip地址
2:配置主机yum(每个系统都要设置)
[[email protected] network-scripts]# cd /etc/yum.repos.d/
[[email protected] yum.repos.d]# rm -rf CentOS-Base.repo
[[email protected] yum.repos.d]# vi CentOS-Media.repo
[c6-media]
name=CentOS-$releasever - Media
baseurl=file:///media/cdrom/
gpgcheck=1
enabled=1
gpgkey=file:///media/cdrom/RPM-GPG-KEY-CentOS-6
[[email protected] yum.repos.d]# cd
[[email protected] ~]# mkdir /media/cdrom
[[email protected] ~]# mount /dev/cdrom /media/cdrom
二:搭建Mysql主从复制
将所需软件拷贝到/usr/src/目录下
1:在mysql主服务器上建立时间同步服务器
[[email protected] ~]# yum -y install ntp
[[email protected] ~]# vi /etc/ntp.conf
添加:
server 127.127.1.0
fudge 127.127.1.0 stratum 8
[[email protected] ~]# service ntpd restart
[[email protected] ~]# service iptables stop
[[email protected] ~]# chkconfig iptables off
2:在从服务器上进行时间同步
[[email protected] yum.repos.d]# yum -y install ntpdate
[[email protected] yum.repos.d]# /usr/sbin/ntpdate 192.168.1.101
[[email protected] yum.repos.d]# service iptables stop
[[email protected] yum.repos.d]# chkconfig iptables off
3:在三个服务器上安装mysql(master,slave都有)
[[email protected] ~]# yum -y install ncurses-devel
注释:
ncurses是字符终端下屏幕控制的基本库
[[email protected] ~]#yum -y install gcc*
[[email protected] ~]# cd /usr/src
[[email protected] src]# tar zxvf cmake-2.8.6.tar.gz
[[email protected] src]# cd cmake-2.8.6
[[email protected] cmake-2.8.6]# ./configure
[[email protected] cmake-2.8.6]#gmake
[[email protected] cmake-2.8.6]#gmake install
[[email protected] cmake-2.8.6]# cd /usr/src
[[email protected] src]# tar zxvf mysql-5.5.22.tar.gz
[[email protected] mysql-5.5.22]# cd mysql-5.5.22
[[email protected] mysql-5.5.22]#cmake -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci -DWITH_EXTRA_CHARSETS=all -DSYSCONFDIR=/etc
注释:
-DCMAKE_INSTALL_PREFIX= 安装根目录
-DDEFAULT_CHARSET= 默认字符集
-DDEFAULT_COLLATION=默认编码
-DWITH_EXTRA_CHARSETS= 额外的编码,请使用ALL来编译。
-DWITH_MYISAM_STORAGE_ENGINE=1 编译myisam存储引擎,默认的存储引擎,不加也可以
-DWITH_INNOBASE_STORAGE_ENGINE=1 支持InnoDB存储引擎,这个也是默认安装的
-DWITH_READLINE=1 使用readline功能
-DENABLED_LOCAL_INFILE=1 可以使用load data infile命令从本地导入文件
-DMYSQL_DATADIR=数据库 数据目录
-DSYSCONFDIR= 指定主配置文件目录
[[email protected] mysql-5.5.22]# make && make install
4:优化调整(master,slave都有)
[[email protected] mysql-5.5.22]# cp support-files/my-medium.cnf /etc/my.cnf
cp:是否覆盖"/etc/my.cnf"? y
[[email protected] mysql-5.5.22]# cp support-files/mysql.server /etc/rc.d/init.d/mysqld
[[email protected] mysql-5.5.22]# chmod +x /etc/rc.d/init.d/mysqld
[[email protected] mysql-5.5.22]# chkconfig --add mysqld
[[email protected] mysql-5.5.22]# echo "PATH=$PATH:/usr/local/mysql/bin" >>/etc/profile
[[email protected] mysql-5.5.22]# . /etc/profile 点后面有个空格
5:初始化数据库(master,slave都有)
[[email protected] mysql-5.5.22]# groupadd mysql
[[email protected] mysql-5.5.22]# useradd -M -s /sbin/nologin mysql -g mysql
[[email protected] mysql-5.5.22]# chown -R mysql:mysql /usr/local/mysql
[[email protected] mysql-5.5.22]# /usr/local/mysql/scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --user=mysql
[[email protected] mysql-5.5.22]# service mysqld start
[[email protected] mysql-5.5.22]# chkconfig mysqld on
[[email protected] mysql-5.5.22]# mysqladmin -u root password ‘pwd123‘
6:配置mysql master主服务器(在master上)
[[email protected] mysql-5.5.22]# vi /etc/my.cnf
添加并修改:
server-id=11 修改,57行
log-bin=master-bin 修改,49行
log-slave-updates=true 添加 (可不用添加)
注释:
系统默认采用基于语句的复制类型
1:基于语句的复制。 在主服务器上执行的 SQL 语句,在从服务器上执行同样的语句。否则,你必须要小心,以避免用户对主服务器上的表进行的更新与对服务器上的表所进行的更新之间的冲突,配置:binlog_format = STATEMENT
2:基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一遍,从 MySQL 5.0开始支持,配置:binlog_format = ROW
3:混合类型的复制。默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制,配置:binlog_format = MIXED
log_slave_updates=true #Slave可以是其他 Slave 的 Master,从而扩散 Master 的更新
binlog-ignore-db=test #不记录指定的数据库的二进制日志
replicate-ignore-db=test #设置不需要同步的库
binlog_cache_size = 1M #日志缓存的大小
expire_logs_days=3 #自动过期清理日志的天数
以上参数在[mysqld]模块中设置
[[email protected] mysql-5.5.22]# service mysqld restart
7:给从服务器授权(在master上)
[[email protected] mysql-5.5.22]# cd
[[email protected] ~]# mysql -u root -p
输入密码pwd123
mysql> grant replication slave on . to ‘myslave‘@‘192.168.1.%‘ identified by ‘123456‘ ;
mysql> flush privileges;
mysql> show master status;
+-------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+------------------+
| master-bin.000001 | 337 | | |
+-------------------+----------+--------------+------------------+
1 row in set (0.01 sec)
8:配置从服务器(在slave上配置)
[[email protected] mysql-5.5.22]# vi /etc/my.cnf
修改并添加
server-id = 22 修改,57行值不能和其他mysql服务器重复
relay-log=relay-log-bin 添加(可不指定)
relay-log-index=slave-relay-bin.index 添加(可不指定)
注释:
--relay-log=name????中继日志的文件的名字
?--relay-log-index=name??????MySQL slave 在启动时需要检查relay log index 文件中的relay log信息,此处定义该索引文件的名字
[[email protected] mysql-5.5.22]# service mysqld restart
9:登陆从服务器配置同步(在slave上)
[[email protected] mysql-5.5.22]# mysql -u root -p
输入密码
mysql> change master to master_host=‘192.168.1.101‘,master_user=‘myslave‘,master_password=‘123456‘,master_log_file=‘master-bin.000001‘,master_log_pos=337; 红色的是用主服务器中show出来的值,337表示偏移量
注:?Slave?的?IO?线程接收到信息后,将接收到的日志内容依次写入到?Slave?端的Relay?Log文件(relay-log-bin.xxxxxx)的最末端,并将读取到的Master端的master-bin的文件名和位置记录到master-?info文件中,以便在下一次读取的时候能够清楚的告诉Master“我需要从某个master-bin的哪个位置开始往后的日志内容,请发给我
mysql> start slave;
mysql> show slave statusG;
确保下列两项是yes
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
10:验证主从复制效果
mysql> show databases; 查看当前的数据库,在从服务器上
mysql> create database db_test; 创建一个数据库,在主服务器上
mysql> show databases; 查看当前的数据库,在从服务器上发现多了一个刚创建的数据库
如果需要将一个slave1服务器作为另一台slave2的master,
1):在slave1上修改my.cnf,在[mysqld]模块添加log-slave-updates=true字段,并重启mysql
2):在slave1上执行以下命令创建一个授权用户,用于在slave2上链接slave1
mysql> grant replication slave on . to ‘myslave‘@‘192.168.1.%‘ identified by ‘123456‘ ;
mysql> flush privileges;
mysql> show master status;
3):show出来的信息做为slave2上连接slave1时的参数
重启Mysql服务不会影响主从关系
三:搭建mysql读写分离
1:在主机amoeba上安装java环境
把java拷贝到/usr/local目录下
[[email protected] ~]# chmod +x /usr/local/jdk-6u14-linux-x64.bin
[[email protected] ~]# cd /usr/local
[[email protected] local]# ./jdk-6u14-linux-x64.bin
[[email protected] local]# mv jdk1.6.0_14/ /usr/local/jdk1.6
[[email protected] local]# vi /etc/profile
添加到最末尾:
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
export AMOEBA_HOME=/usr/local/amoeba/
export PATH=$PATH:$AMOEBA_HOME/bin
[[email protected] local]# source /etc/profile
[[email protected] local]# java -version 查询版本,确定java安装成功
2:安装并配置amoeba
将amoeba软件拷贝到usr/src目录中
[[email protected] local]# mkdir /usr/local/amoeba
[[email protected] local]# cd /usr/src
[[email protected] src]# tar zxf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
[[email protected] src]# chmod -R 755 /usr/local/amoeba/
[[email protected] src]# /usr/local/amoeba/bin/amoeba
amoeba start|stop 有此提示表示成功
3:配置amoeba读写分离
(1)在三个mysql服务器中开放权限给amoeba访问
mysql> grant all on . to [email protected]‘192.168.10.%‘ identified by ‘123.com‘; 三个mysql服务器都要
(2)在amoeba上配置amoeba.xml文件
[[email protected] amoeba]# service iptables stop
[[email protected] ~]# cd /usr/local/amoeba/conf
[[email protected] conf]# vi amoeba.xml
修改红色部分
<property name="authenticator">
<bean class="com.meidusa.amoeba.mysql.server.MysqlClientAuthenticator">
<property name="user">amoeba</property> \30行
<property name="password">123456</property> \32行
<property name="filter">
<bean class="com.meidusa.amoeba.server.IPAccessController">
<property name="ipFile">${amoeba.home}/conf/access_list.conf</property>
</bean>
</property>
</bean>
</property>
。。。。。。。。略。。。。。。。<queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter">
<property name="ruleLoader">
<bean class="com.meidusa.amoeba.route.TableRuleFileLoader">
<property name="ruleFile">${amoeba.home}/conf/rule.xml</property>
<property name="functionFile">${amoeba.home}/conf/ruleFunctionMap.xml</property>
</bean>
</property>
<property name="sqlFunctionFile">${amoeba.home}/conf/functionMap.xml</property>
<property name="LRUMapSize">1500</property>
<property name="defaultPool">master</property> 115行
<property name="writePool">master</property> \118行
<property name="readPool">slaves</property> \119行此处的注释去掉
<property name="needParse">true</property>
</queryRouter>[[email protected] conf]# vi dbServers.xml
修改(注意去掉注释),slave2的复制一个slave1
以上是关于搭建MySql主从复制与读写分离的主要内容,如果未能解决你的问题,请参考以下文章