SQL Server 性能调优 之执行计划(Execution Plan)调优
Posted wangwust
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL Server 性能调优 之执行计划(Execution Plan)调优相关的知识,希望对你有一定的参考价值。
SQL Server 存在三种 Join 策略:Hash Join,Merge Join,Nested Loop Join。
Hash Join:用来处理没有排过序/没有索引的数据,它在内存中把 Join 两边数据(的关联key)分别建立一个哈希表。例如有以下的查询语句,关联的两张表没有建立索引,执行计划将显示为Hash Join。
- SELECT
- sh.*
- FROM
- SalesOrdHeaderDemo AS sh
- JOIN
- SalesOrdDetailDemo AS sd
- ON
- sh.SalesOrderID=sd.SalesOrderID
- GO
Merge Join:用来处理有索引的数据,它比Hash Join轻量化。我们为前面两张表的关联列建立索引,然后再次上面的查询,执行计划将变更为Merge Join
- CREATE UNIQUE CLUSTERED INDEX idx_salesorderheaderdemo_SalesOrderID ON SalesOrdHeaderDemo (SalesOrderID)
- GO
- CREATE UNIQUE CLUSTERED INDEX idx_SalesDetail_SalesOrderlID ON SalesOrdDetailDemo (SalesOrderID,SalesOrderDetailID)
- GO
Nested Loop Join:在满足Merge
Join的基础上,如果某一边的数据较少,那么SQL Server
会把数据较少的那个作为外部循环,另一个作为内部循环来完成Join处理。继续前面的例子为查询语句加上WHERE语句来减少 Join
一边的数据量,执行计划显示为Nested Loop Join。
- SELECT
- sh.*
- FROM
- SalesOrdHeaderDemo AS sh
- JOIN
- SalesOrdDetailDemo AS sd
- ON
- sh.SalesOrderID=sd.SalesOrderID
- WHERE
- sh.SalesOrderID=43659
执行计划中的(table/index scan)的改进
在许多场合我们需要在一张包含许多数据的表中提取出一小部分数据,此时应当避免Scan,因为扫描处理会遍历每一行,这是相当耗时耗力的。下面我们来看一个例子:
- SELECT
- sh.SalesOrderID
- FROM
- SalesOrdHeaderDemo AS sh
- JOIN
- SalesOrdDetailDemo AS sd
- ON
- sh.SalesOrderID=sd.SalesOrderID
- WHERE
- sh.OrderDate=‘2005-07-01 00:00:00.000‘
- GO

图中的红圈标出了table scan,并且执行计划也智能得建议建立索引。我们先尝试在SalesOrdHeader 表上建立一个索引:
- CREATE UNIQUE CLUSTERED INDEX idx_salesorderheaderdemo_SalesOrderID ON SalesOrdHeaderDemo (SalesOrderID)
- GO
然后再次执行相同的查询语句,执行计划变成以下的模样:
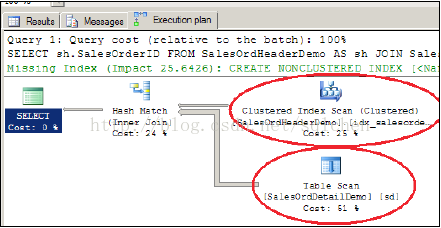
table scan 变为了 Index Scan,继续给另一张表也加上索引:
- CREATE UNIQUE CLUSTERED INDEX idx_SalesDetail_SalesOrderlID ON SalesOrdDetailDemo (SalesOrderID,SalesOrderDetailID)
- GO
执行计划发生以下的变化:

虽然不能说 Scan 比 Seek 差,但绝大多数的场合(尤其是在许多数据中查找少量数据时)Seek 是更好的选择。举例来说如果你有一个上亿条数据的表,你要取其中的100条,那么你应当保证其采用 Seek,但如果你需要取出其中绝大多数(比如95%)的数据时,Scan 可能更好。(有较权威的文章给出了这个阀值为30%,即取出超过30%数据时 scan 更高效;反之则 Seek 更好)
另外你可能注意到两张表上都建立了索引但一张表在执行计划中表现为 Clustered index scan,而另一张表现为 Clustered index seek,我们期待的不是两个 Clustered index seek 吗?这是因为前一张表没有断言(predicate),而后一张表通过 ON 关键字对SalesOrderID 进行了断言限制。
执行计划中的 Key Lookup
为了后续的示例,我们先在同一张表上建立两个不同的索引:
- CREATE UNIQUE CLUSTERED INDEX idx_SalesDetail_SalesOrderlID ON SalesOrdDetailDemo (SalesOrderID,SalesOrderDetailID)
- GO
- CREATE NONCLUSTERED INDEX idx_non_clust_SalesOrdDetailDemo_ModifiedDate ON SalesOrdDetailDemo(ModifiedDate)
- GO
执行以下的查询:
- SELECT
- ModifiedDate
- FROM SalesOrdDetailDemo
- WHERE ModifiedDate=‘2005-07-01 00:00:00.000‘
- GO
执行计划如下图,他利用了我们先前建立在 ModifiedDate 字段上的 Non-Clustered Index,生成为一个Index Seek 处理。
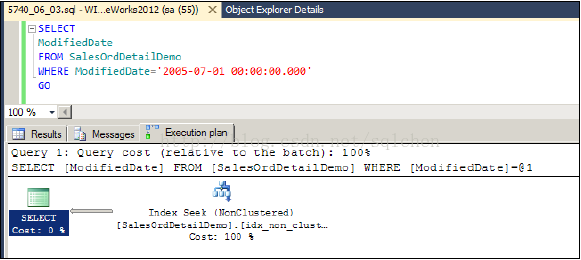
我们改造一下查询语句,SELECT 中多加两个字段:
- SELECT
- ModifiedDate,
- SalesOrderID,
- SalesOrderDetailID
- FROM SalesOrdDetailDemo
- WHERE ModifiedDate=‘2005-07-01 00:00:00.000‘
- GO
执行计划如下图,基本没变:
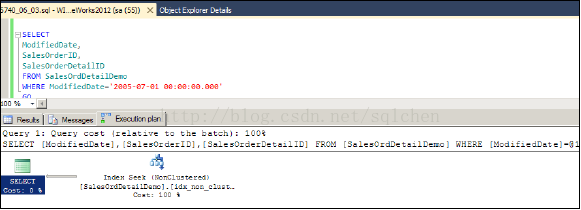
上面选出的字段不是属于 Non-Clustered Index 就是属于 Clustered Index,如果再增加几个其他的字段呢?
- SELECT
- ModifiedDate,
- SalesOrderID,
- SalesOrderDetailID,
- ProductID,
- UnitPrice
- FROM SalesOrdDetailDemo
- WHERE ModifiedDate=‘2005-07-01 00:00:00.000‘
- GO
乖乖,执行计划一下多了两个处理(Key Lookup, Nested Loop):
Key Lookup 是一个繁重的处理,我们可以使用关键字 WITH 来指定使用 Clustered Index,以此回避Key Lookup。

- SELECT
- ModifiedDate,
- SalesOrderID,
- SalesOrderDetailID,
- ProductID,
- UnitPrice
- FROM SalesOrdDetailDemo WITH(INDEX=idx_SalesDetail_SalesOrderlID)
- WHERE ModifiedDate=‘2005-07-01 00:00:00.000‘
- GO
执行计划应声而变成为一个 Clustered Index Scan:
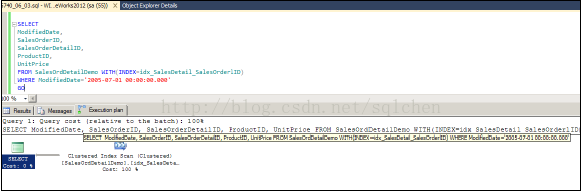
前文提过 Scan 似乎也不是一个很好的处理,那么矮子里拔高个,使用 SET STATISTICS IO ON 来比较一下:
- SET STATISTICS IO ON
- GO
- SELECT
- ModifiedDate,
- SalesOrderID,
- SalesOrderDetailID,
- ProductID,
- UnitPrice
- FROM SalesOrdDetailDemo
- WHERE ModifiedDate=‘2005-07-01 00:00:00.000‘
- GO
- SELECT
- ModifiedDate,
- SalesOrderID,
- SalesOrderDetailID,
- ProductID,
- UnitPrice
- FROM SalesOrdDetailDemo WITH(INDEX=idx_SalesDetail_SalesOrderlID)
- WHERE ModifiedDate=‘2005-07-01 00:00:00.000‘
- GO
- SELECT
- ModifiedDate,
- SalesOrderID,
- SalesOrderDetailID,
- ProductID,
- UnitPrice
- FROM SalesOrdDetailDemo WITH(INDEX=idx_non_clust_SalesOrdDetailDemo_ModifiedDate)
- WHERE ModifiedDate=‘2005-07-01 00:00:00.000‘
- GO
比较下来,采用了 clustered index 的查询表现最差,另外 SET STATISTICS IO 输出的数据中clustered index 的查询在 logical reads 上花费了更多的时间。
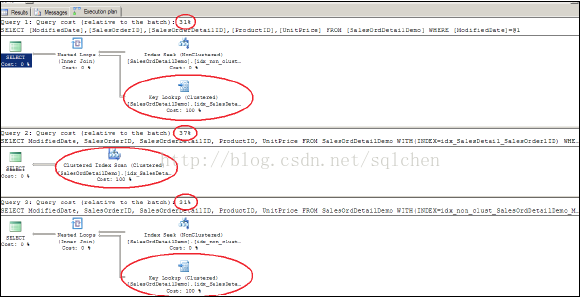
看起来采用 non-clustered index + Key Lookup 执行计划表现还不错,但如果能回避 Key Lookup 就完美了,我们来把 non-clustered index 修改一下,用 INCLUDE 关键字在索引中包含其他的字段:
- DROP INDEX idx_non_clust_SalesOrdDetailDemo_ModifiedDate ON SalesOrdDetailDemo
- GO
- CREATE NONCLUSTERED INDEX idx_non_clust_SalesOrdDetailDemo_ModifiedDate ON SalesOrdDetailDemo(ModifiedDate)
- INCLUDE
- (
- ProductID,
- UnitPrice
- )
- GO
- -- 清下缓存,仅用于开发环境!
- DBCC FREEPROCCACHE
- DBCC DROPCLEANBUFFERS
- GO
再次执行之前的查询:
- SELECT
- ModifiedDate,
- SalesOrderID,
- SalesOrderDetailID,
- ProductID,
- UnitPrice
- FROM SalesOrdDetailDemo
- WHERE ModifiedDate=‘2005-07-01 00:00:00.000‘
- GO

这下完美了,因为我们的查询字段都包含在索引中,所以执行计划最终被优化为 Index Seek。
以上是关于SQL Server 性能调优 之执行计划(Execution Plan)调优的主要内容,如果未能解决你的问题,请参考以下文章